Pix2Pix-GAN 简介与代码实战
1.介绍
Pix2Pix出自于论文“Image-to-Image Translation with Conditional Adversarial Networks”,其中文翻译为:“基于条件gan的图片翻译”,说到翻译,我们很容易想到,英语转换成汉语就是一种语言上的翻译,同理,图片上内容的转换就是图片翻译(比如图片的风格转换)
2.模型结构
下图为生成器网络,左边为一个普通自编码器网络,右边为一个特殊的自编码器网络(U-Net),在自编码器网络中,编码端提取重要信息,解码端恢复这些信息,在对称的位置上,两者的信息是很相似的(如果能完全相同,图片就会无误差的被恢复),所以,如果我们能把解码端提取到的信息直接给解码端,那么恢复出来的图片是不是会更好?
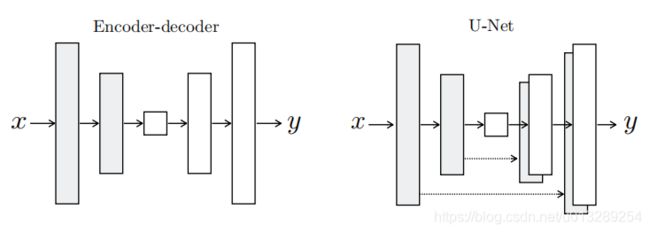
对于判别器网络,普通的gan网络(可以参考我以前的博客),输入是一张图片,输出是一个二值数(0代表是生成图片,1代表是真实图片),而本论文的D称为Patch-D(名字很高大上,在代码中,实现起来很简单,让原本输出0和1的数字改成输出feature map),这样做的好处有两点:1.速度快,feature map的一个点相当于代表图片中的一个小区域,相当于把图片分区域判断(并行的感觉);2.对于全卷积的D,输入可以是任意大小图片。
3.模型特点
对于损失函数,注意两点就行:1.判别器输入的是两张图片一张是待被转换的图片(x),另外一张是目标图片或者生成的图片;2.增加L1损失函数,减少模糊(相当于L2),并让生成的图片更接近目标图片
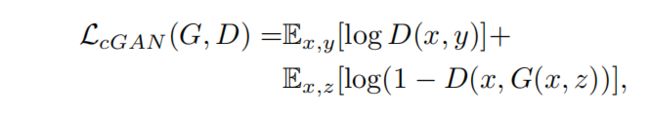
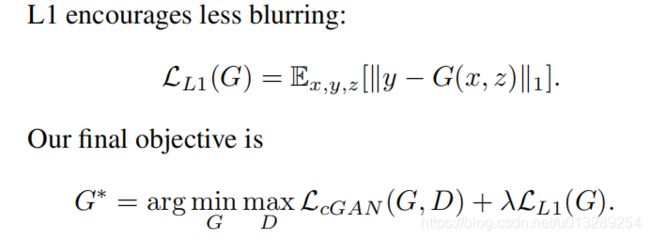
4.代码实现keras
class Pix2Pix():
def __init__(self):
# Input shape
self.img_rows = 256
self.img_cols = 256
self.channels = 3
self.img_shape = (self.img_rows, self.img_cols, self.channels)
# Configure data loader
self.dataset_name = 'facades'
self.data_loader = DataLoader(dataset_name=self.dataset_name,
img_res=(self.img_rows, self.img_cols))
# Calculate output shape of D (PatchGAN)
patch = int(self.img_rows / 2**4)
self.disc_patch = (patch, patch, 1)
# Number of filters in the first layer of G and D
self.gf = 64
self.df = 64
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='mse',
optimizer=optimizer,
metrics=['accuracy'])
#-------------------------
# Construct Computational
# Graph of Generator
#-------------------------
# Build the generator
self.generator = self.build_generator()
# Input images and their conditioning images
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
# By conditioning on B generate a fake version of A
fake_A = self.generator(img_B)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# Discriminators determines validity of translated images / condition pairs
valid = self.discriminator([fake_A, img_B])
self.combined = Model(inputs=[img_A, img_B], outputs=[valid, fake_A])
self.combined.compile(loss=['mse', 'mae'],
loss_weights=[1, 100],
optimizer=optimizer)
def build_generator(self):
"""U-Net Generator"""
def conv2d(layer_input, filters, f_size=4, bn=True):
"""Layers used during downsampling"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
def deconv2d(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
"""Layers used during upsampling"""
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same', activation='relu')(u)
if dropout_rate:
u = Dropout(dropout_rate)(u)
u = BatchNormalization(momentum=0.8)(u)
u = Concatenate()([u, skip_input])
return u
# Image input
d0 = Input(shape=self.img_shape)
# Downsampling
d1 = conv2d(d0, self.gf, bn=False)
d2 = conv2d(d1, self.gf*2)
d3 = conv2d(d2, self.gf*4)
d4 = conv2d(d3, self.gf*8)
d5 = conv2d(d4, self.gf*8)
d6 = conv2d(d5, self.gf*8)
d7 = conv2d(d6, self.gf*8)
# Upsampling
u1 = deconv2d(d7, d6, self.gf*8)
u2 = deconv2d(u1, d5, self.gf*8)
u3 = deconv2d(u2, d4, self.gf*8)
u4 = deconv2d(u3, d3, self.gf*4)
u5 = deconv2d(u4, d2, self.gf*2)
u6 = deconv2d(u5, d1, self.gf)
u7 = UpSampling2D(size=2)(u6)
output_img = Conv2D(self.channels, kernel_size=4, strides=1, padding='same', activation='tanh')(u7)
return Model(d0, output_img)
def build_discriminator(self):
def d_layer(layer_input, filters, f_size=4, bn=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
# Concatenate image and conditioning image by channels to produce input
combined_imgs = Concatenate(axis=-1)([img_A, img_B])
d1 = d_layer(combined_imgs, self.df, bn=False)
d2 = d_layer(d1, self.df*2)
d3 = d_layer(d2, self.df*4)
d4 = d_layer(d3, self.df*8)
validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
return Model([img_A, img_B], validity)
def train(self, epochs, batch_size=1, sample_interval=50):
start_time = datetime.datetime.now()
# Adversarial loss ground truths
valid = np.ones((batch_size,) + self.disc_patch)
fake = np.zeros((batch_size,) + self.disc_patch)
for epoch in range(epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):
# ---------------------
# Train Discriminator
# ---------------------
# Condition on B and generate a translated version
fake_A = self.generator.predict(imgs_B)
# Train the discriminators (original images = real / generated = Fake)
d_loss_real = self.discriminator.train_on_batch([imgs_A, imgs_B], valid)
d_loss_fake = self.discriminator.train_on_batch([fake_A, imgs_B], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# -----------------
# Train Generator
# -----------------
# Train the generators
g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, imgs_A])
elapsed_time = datetime.datetime.now() - start_time
# Plot the progress
print ("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %3d%%] [G loss: %f] time: %s" % (epoch, epochs,
batch_i, self.data_loader.n_batches,
d_loss[0], 100*d_loss[1],
g_loss[0],
elapsed_time))
# If at save interval => save generated image samples
if batch_i % sample_interval == 0:
self.sample_images(epoch, batch_i)
def sample_images(self, epoch, batch_i):
os.makedirs('images/%s' % self.dataset_name, exist_ok=True)
r, c = 3, 3
imgs_A, imgs_B = self.data_loader.load_data(batch_size=3, is_testing=True)
fake_A = self.generator.predict(imgs_B)
gen_imgs = np.concatenate([imgs_B, fake_A, imgs_A])
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
titles = ['Condition', 'Generated', 'Original']
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt])
axs[i, j].set_title(titles[i])
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%s/%d_%d.png" % (self.dataset_name, epoch, batch_i))
plt.close()