去雨总结(更新中)
文章目录
- 单张图像去雨问题( single image deraining)
- 定义
- 常用数据集
- 指标
- 雨水模型
- rain streak
- raindrop
- rain and mist
- 全监督方法
- Attentive Generative Adversarial Network for Raindrop Removal from A Single Image[CVPR2018]
- Non-locally Enhanced Encoder-Decoder Network for Single Image De-raining[ACM MM2018]
- Deep Joint Rain Detection and Removal from a Single Image[CVPR2017]
- Progressive Image Deraining Networks: A Better and Simpler Baseline[CVPR2019]
- pix2pix
- 半监督方法
- Semi-supervised Transfer Learning for Image Rain Removal[CVPR2019]
- 无监督方法
- DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking[2019.12 from arxiv]
- 新的数据集和指标
- Single Image Deraining: A Comprehensive Benchmark Analysis[CVPR2019]
- 存在的问题
单张图像去雨问题( single image deraining)
定义
该问题的目标是从包含雨水的图像生成去除雨水的图像。与图像修复问题不同,单张图像去雨问题中没有给出雨水的位置,也就是需要“修复”的位置,且被雨水遮挡的位置的图像背景信息几乎丢失,因此难度较大
早期的去雨方法利用视频中得到的连续的多帧图像,并对图像取平均得到去雨图像,而单张图像去雨问题缺少这样时序性的信息作为辅助
常用数据集
合成数据:
| 数据集 | 数量 | 说明 |
|---|---|---|
| DDN-Data | 训练9100对,测试4900对 | 由1000幅清晰的图像合成,包含14种不同的条纹方向和大小 |
| DIDMDN-Data | 12000对 | 3种密度 |
| Rain100L&Rain100H | L:训练200对,测试100对;H:训练1800对,测试100对 | L只有1种类型的雨,H有5种方向的雨 |
| Rain800 | 训练700对,测试100对 | rain streak |
真实数据(获取难度较大):
| 数据集 | 数量 | 说明 |
|---|---|---|
| AttentiveGAN-Data | 1119对 | raindrop图,在放置在镜头前的玻璃片上喷洒水珠前后进行拍摄得到 |

指标
常用的指标为两种图像质量评价指标PSNR和SSIM
PSNR(Peak Signal to Noise Ratio)
峰值信噪比,一种全参考的图像质量评价指标,单位为dB
给定一个大小为 m×n 的干净图像 I 和噪声图像 K,均方误差 (MSE) 定义为:

PSNR定义为:
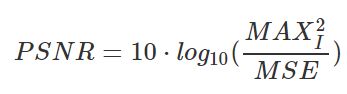
M A X I 2 MAX^{2}_{I} MAXI2 为图片可能的最大像素值,常见的即255
上面是针对灰度图像的计算方法,如果是彩色图像,通常有三种方法来计算:
- 分别计算 RGB 三个通道的 PSNR,取平均值
- 计算 RGB 三通道的 MSE ,再除以 3
- 将图片转化为 YCbCr 格式,只计算 Y 分量也就是亮度分量的PSNR
SSIM (Structural SIMilarity)
结构相似性,基于样本 x 和 y 之间的三个比较衡量:亮度 (luminance)、对比度 (contrast) 和结构 (structure)
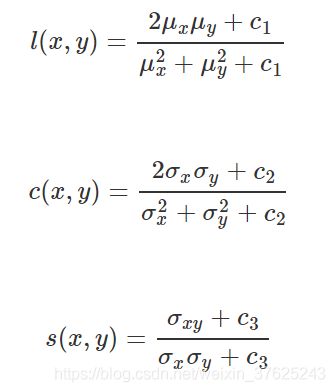

则SSIM为:
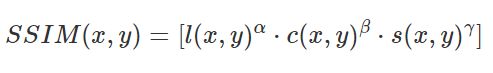
每次计算的时候都从图片上取一个 N×N 的窗口,然后不断滑动窗口进行计算,最后取平均值作为全局的 SSIM
(转载:https://www.cnblogs.com/seniusen/p/10012656.html)
雨水模型
一般将雨图建模为雨水层和干净背景层的组合。按照雨水的类型,可以分为以下三种
rain streak
雨线图可以表示为干净背景B和稀疏的线型雨水S的线性叠加:
![]()
raindrop
雨点图可以视为干净背景B和分散的、小范围、局部区域的雨点带来的模糊效果的组合:
![]()
M是一个二元掩码,如果该像素属于雨区,则M=1,若属于背景区则M=0
rain and mist
雨图常包含雨水及其带来的雾效。这种雨图可以建模为雨线模型+大气散射霾模型(atmospheric scattering haze model):
![]()
S是雨线,t和A是透射图(transmission map)和大气光(atmospheric light),它们决定了雾/薄雾成分
全监督方法
现在用深度学习进行去雨的模型绝大部分使用全监督的方法,将包含计算机合成雨水的雨图和相同背景的无雨图作为ground truth的合成数据集进行训练和测试
这些模型为了有效去雨,大都采用多阶段的方式或encoder-decoder的架构,用全卷积学习雨图到无雨图的映射或残差
目前论文中使用的模块大致可看作分别用于解决两个问题:定位雨水和保留背景信息
定位雨水需要扩大感知野、得到丰富的contextual info,用到的模块主要有:
- dilated network
- non-local block
- attention
为了保留背景信息,也需要从雨水周围的像素中获得局部信息,同时要在后面的层中尽可能地保留原有特征。对于保留原有特征,常见方法有:
- RNN
- 残差连接
- pooling indices
- discriminator
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image[CVPR2018]
主要贡献:在generator和discriminator中引入attention机制
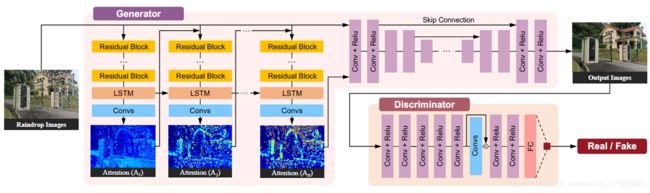
Generator
-
Attentive-recurrent network:定位雨点
通过多个时间步生成attention map,找到原图中需要被网络关注的区域:雨点及其周围区域- attention map V.S. binary mask:前者是每个值为0~1之间的矩阵,值越大表示该位置越需要关注;后者是二元掩码,值为1表示该位置属于雨点区域,值为0则是背景区域,该掩码由雨图与无雨图相减,再设定一个阈值(threshold)决定雨区与非雨区得到
每个时间步的输入是前一个时间步产生的attention map和雨图的拼接,包含以下步骤:
- ResNet:在前一个时间步产生的attention map的指导下,从雨图中提取特征
- 卷积LSTM:充分利用之前的时间步提取的特征
- 卷积层:生成attention map
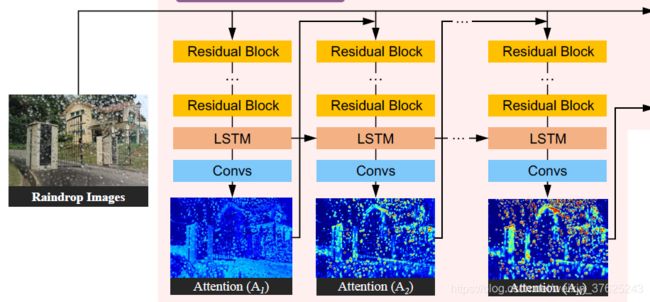
attention loss:计算每个时间步生成的attention map与binary mask之间的均方误差

- Contextual Autoencoder:去雨
attention map与雨图的拼接作为输入
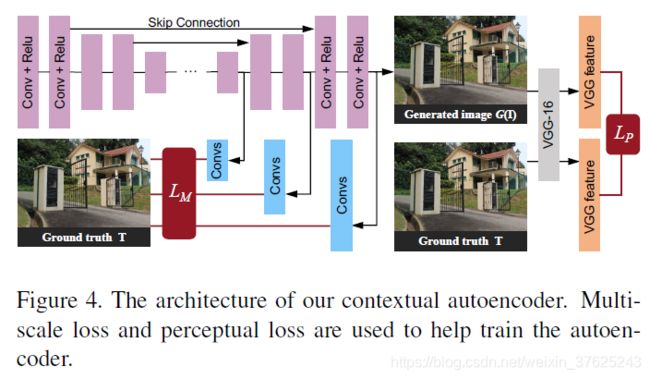
multi-scale loss+perceptual loss,分别对应局部的像素之间的差异和全局的特征之间的差异
multi-scale loss:从多个尺度捕捉更多的情境信息。 S i S_{i} Si和 T i T_{i} Ti分别是相同尺寸的某层decoder输出和ground truth, λ \lambda λ是不同尺度的权重,尺寸越大,权重越大
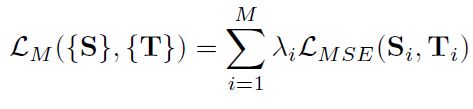
perceptual loss:将autoencoder的输出和ground truth分别输入VGG-16得到提取的特征,计算二者之间的全局差异
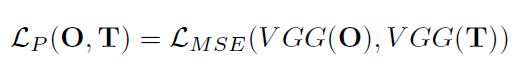
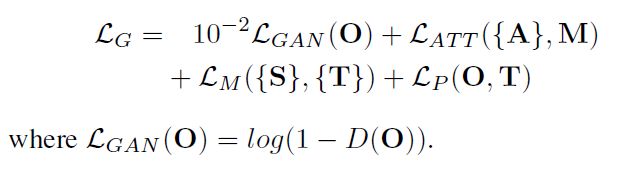
Discriminator
利用局部和全局的图像内容的一致性作为D的判断条件
从D的内部层提取到的特征输入一个CNN,将CNN的输出与D的特征相乘,再往后面的层传播,最后使用全连接层判断真假
计算CNN的输出与attention map之间的差异作为损失,引导D将注意力放在attention map关注的位置。R是抽样的无雨图,第二项意在表明对于无雨图,没有需要施加注意力的区域
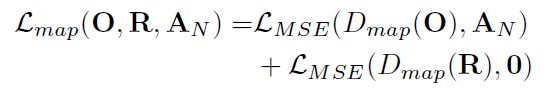
D的总损失如下:

结果


Non-locally Enhanced Encoder-Decoder Network for Single Image De-raining[ACM MM2018]
论文
github
我的博客
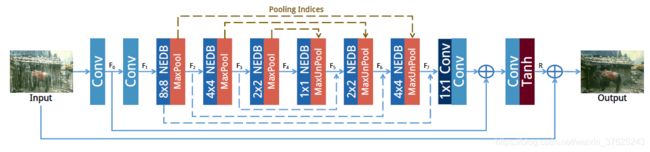
主要贡献:将非局部增强加入编码器解码器架构,有效去除各种密度的雨水的同时完美保留图像的细节
Non-locally Enhanced Dense Block (NEDB)
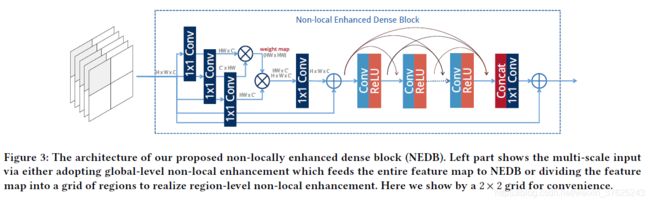
NEDB的非局部操作,通过对像素矩阵中每个位置i考虑图像中所有可能位置 ( ∀ j ) (\forall j) (∀j)对特征表示进行非局部增强:

f f f:采用点积形式计算一对值之间的关联
F n F_{n} Fn:输入NEDB的特征激活值
g ( . ) g(.) g(.):计算 F n F_{n} Fn表示的一元函数
C ( F ) C(F) C(F):归一化因子 C ( F ) = Σ ∀ j f ( F n , i , F n , j ) C(F) = \Sigma_{\forall j}f(F_{n,i},F_{n,j}) C(F)=Σ∀jf(Fn,i,Fn,j)
将非局部增强过的特征表示作为输入送给五个密集连接的卷积层
每一层到所有后续层都直接连接,第 l l l层接受之前所有层的特征激活值 D 0 , . . . , D l − 1 D_{0},...,D_{l-1} D0,...,Dl−1的拼接作为输入
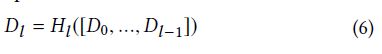
为避免梯度爆炸/梯度消失问题,在每个NEDB中使用局部残差学习
另外,由于NEDB中的非局部操作计算每个空间位置的值之间的相关性,随着尺寸的增大,计算负担显著增加。为了解决这个问题,以多尺度的方式实现非局部操作:将具有较高空间分辨率的特征图划分为区域网格(例如F1被划分为一个8×8的网格),让NEDB在每个划分出来的小区域内进行特征激活。对于较低分辨率的特征图,NEDB直接作用于整个图
Pooling Indices Guided Decoding
编码器部分包含三个连续的NEDB,每个NEDBs后面都有一个带striding的最大池化层,对特征激活值进行下采样。相对应地,在解码器部分堆叠另外三个NEDB,每一个后面都有一个最大池化层对特征激活值进行上采样。在编码时记录pooling indices,之后解码时的上采样将记录的池化索引矩阵作为依据。最后利用残差连接将编码层的特征激活与对应的解码层连接
实验证明该方法比双线性插值上采样方法更适合去雨任务
损失函数
输出图像和ground truth之间的平均绝对误差

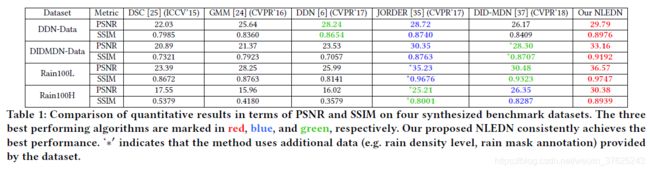
定量分析
与五个模型的不同数据集用两个metric进行对比。PSNR显著提高,较高的SSIM值也表明该方法可以更好地恢复图像的结构信息。
Deep Joint Rain Detection and Removal from a Single Image[CVPR2017]
主要贡献:
- 提出新的雨图模型,包括rain accumulation
- 提出新的pipeline:先检测雨水位置,再估计雨线,最后提取出背景层,完成去雨
雨图模型
原来公认的模型:

O O O:带雨的输入图像
B B B:干净的背景层
S ~ \widetilde S S :雨水层
在原来的模型中,去雨被看做是两个信号分离的问题,基于背景层和雨水层各自的独特特征对其进行分离。
但这样做存在问题: S ~ \widetilde S S 需要同时包含雨水位置和该位置上的密度信息。图像中不同区域的雨的疏密程度不同,很难用统一的稀疏度对 S ~ \widetilde S S 进行建模;而不区分雨区和非雨区,也将造成非雨区过于平滑
泛化的雨图模型:
为了解决上述问题,作者在原有模型中加入了一个region-dependent的变量 R R R,表征单个雨线的位置。R即为binary map,1表示该像素点位于雨区内,0则反之
![]()
这样做不但给网络学习雨区提供了额外的信息,而且有助于构建一个新的流水线:先检测雨区,再对雨区和非雨区进行不同操作。
针对大雨和雨累积的模型:
在雨水密集的情况下,单个雨线无法看清,且图中会出现模糊的“雾效”。作者提出了包含雾效和多层雨线的新模型:
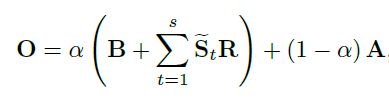
S ~ t \widetilde S_{t} S t:表示一层拥有相同方向的雨线,对不同方向雨线求和,则得到贴近真实场景的效果
α \alpha α:传输率,在大气散射中的成像模型中表示该点的光强被衰减之后,进入成像设备的比例
A A A:环境光
加入传输率和环境光后,该模型可以表示图像中因雨累积造成的雾效。更重要的是,这种雾效是在不同方向的雨线模型的基础上建模的,因此可以分阶段解决雨累积和雨线去除
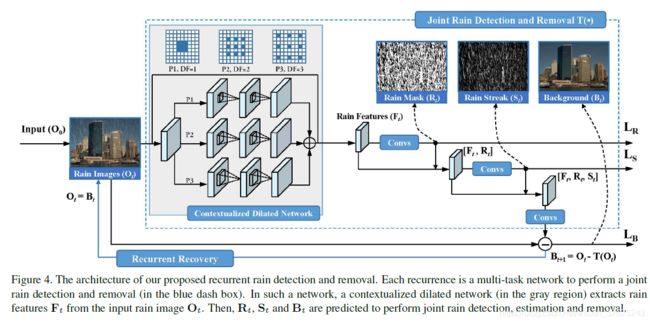
joint rain detection and removal
论文提出的去雨架构大致可看成多任务的两个步骤再对其进行循环:
- contextualized dilated network将初步提取到的特征经过三个感知野逐渐扩大的卷积路径,利用空洞卷积挖掘不同尺度的区域性情境信息,为检测雨水提供更好的表征
- jointly detection and removal根据提取到的特征,先检测雨水位置,再估计雨水强度,最后提取出背景层,完成去雨。即先通过得到的特征F计算R,再根据F和R计算S,最后根据F,R,S,O-RS计算残差 ϵ \epsilon ϵ,利用B=O- ϵ \epsilon ϵ得到干净图B。实验证明这样的顺序和按顺序而非并行估计的方式效果最好
- recurrent rain detection and removal network,将去雨视作多阶段任务进行循环操作,每个recurrence执行上述部分的操作,可以有效去除大雨场景的雨水
rain accumulation removal
根据针对大雨和雨累积的雨图模型,为了得到“包裹”在公式最内部的背景层B,按照顺序应该先去除最外端的雨累积效应,再去除其他雨线
但作者发现,如果将其作为第一步,会使得已经非常显眼的雨线变得更为突出,造成在下一步去除雨线时,这些雨线与其他雨线看上去很不一样。下图展示了使用不同的顺序的结果

因此,作者提出三步走策略,streak removal-> rain accumulation removal-> streak removal,先去一遍雨线,再进行雨累积效应的去除,最后再去一遍雨线,效果如图中(f)所示。这是合理的,因为去除雨累积效应的步骤可以使得在第一阶段可能不够明显的雨线变得明显,然后在第三阶段将它们去除
雨累积效应的去除与其他两个步骤网络不同,与去雾类似,只基于情境空洞卷积网络进行一个recurrence
实验
作者利用新提出的雨图模型自行合成了一些数据,命名为Rain100L,Rain100H,并将Rai100L的一个子集命名为Rain20作为其他对比模型的测试集
对提出的模型的四个变体进行实验:
JORDER-
在每个recurrence只有一个卷积路径,且没有进行空洞卷积
JORDER
多任务网络,joint rain detection and removal,没有循环操作
JORDER-R
循环地去除针对大雨和雨累积的雨图模型描述的雨水。
JORDER-R-DEVEIL
去除雨累积效应



*作者没有给出JORDER-R-DEVEIL的PSNR和SSIM数据
Progressive Image Deraining Networks: A Better and Simpler Baseline[CVPR2019]
论文
github
我的博客
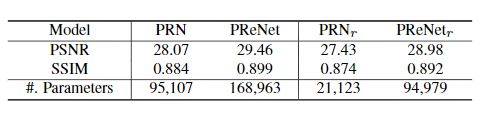
主要贡献:提出一个简单的baseline,减少网络参数,同时保持SOTA水平

这个工作提出了一个很简单的baseline:采用6个阶段的多阶段模型,每个阶段以原始雨图和上个阶段生成的去雨图的拼接作为输入,根据每个阶段是否加入RNN分为PRN和PReNet两种模型,以及减少参数的PRN r _{r} r和PReNet r _{r} r
PRN:Progressive Residual Network
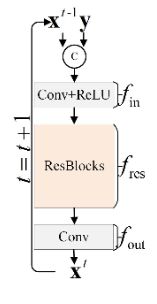
在每个阶段,由ReLU激活的卷积层接受输入、5个ResBlock提取深层特征,最后一个卷积层生成去雨图
PReNet: Progressive Recurrent Network

在PRN的基础上加入一个LSTM挖掘不同阶段之间的深层特征,即图中的蓝绿色模块。阶段之间的特征依赖可以促进去雨
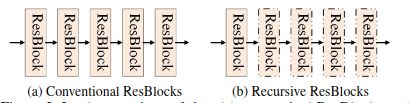
PRN r _{r} r和PReNet r _{r} r
对于原来模型中的ResBlock组,重复使用同一个ResBlock(下图中右边的Recursive ResBlocks),减少网络参数的同时保持SOTA水平,在模型大小和去雨性能之间做了折中
损失函数
近期去雨模型中很多都使用了混合损失函数(如MSE+SSIM)和对抗损失。作者指出,这些损失增加了调整超参的负担。由于渐进式网络结构的存在,单独的MSE或者负SSIM已经足够训练PRN和PReNet达到理想效果

pix2pix
我的博客
许多与图像有关的问题都可以理解为图像翻译问题,即输入图像到输出图像的变换。这些问题的实质都是一样的:从像素映射到像素,非常适合利用GAN来解决问题。但是传统GAN缺少用户控制,生成器可能不管输入是什么,盲目地生成能让鉴别器打高分的图片。这是我们不希望看到的
作者使用conditional GAN,将G的输入和输出一起给D作为输入,增加指导性的额外条件(图中的x),帮助D进行判断

对于G,第i层和第n-i层之间添加残差连接,使其形成类似于U-Net的结构,如下图所示;对于D,仅对一个patch大小范围内的图像部分进行惩罚,形成“PatchGAN”分类器
虽然L1或L2损失函数会造成生成图像的模糊,但是已经足够能够捕捉低分辨率的正确特征,因此只需要让GAN的判别器D对高分辨率的结构进行建模,靠L1损失项去实现低分辨率的正确性即可
![]()
半监督方法
Semi-supervised Transfer Learning for Image Rain Removal[CVPR2019]
论文
我的博客
主要贡献:第一个将单张图像去雨任务视为领域自适应问题,第一个提出半监督模型解决去雨问题
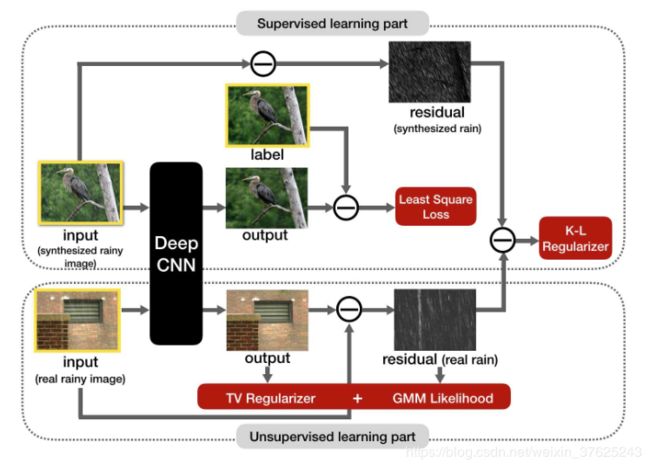
该论文提出一种半监督的方法, 将真实雨图(无需对应的无雨图)加入训练集,将雨图和无雨图之间的残差视为一个参数化雨水分布,网络可以通过有监督的合成雨水来适应真实无监督多种雨类型,这样缺少训练样本和真实与合成数据之间存在差别的问题可被显著减轻
模型
用混合模型可以实现对任意连续函数的逼近,因此可以用GMM(Gaussian Mixture Model)来描述无监督数据中的雨水(本文中使用了三层)
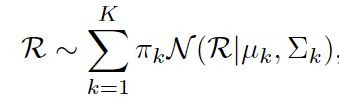
k表示不同的分布的序号, N \mathcal{N} N即高斯分布, π k , μ k , ∑ k \pi_{k}, \mu_{k}, \sum_{k} πk,μk,∑k分别是混合系数、高斯分布的均值和方差
对无监督样本使用如下的负对数似然(negative log likelihood function)作为无监督部分的损失;对于有监督的样本,采用DerainNet的网络结构 f ω f_{\omega} fω生成无雨图,损失即为无雨图与ground truth之间的平方损失;最小化K-L散度,约束真实雨水分布和合成雨水分布之间的差异,使得模型从合成雨水的域转移到真实雨水的域,而不是任意域;加入Total Variation regularizer对图像进行一些平滑,得到的总loss如下:

x i x_{i} xi和 y i y_{i} yi分别是合成雨图的对应的ground truth, x ~ \tilde x x~是真实雨图, x ~ n − f ω ( x ~ ) n \tilde x_{n}-f_{\omega}(\tilde x)_{n} x~n−fω(x~)n是提取到的雨层,与 R n \mathcal R_{n} Rn等价。 λ , α , β \lambda, \alpha, \beta λ,α,β是对不同loss进行比例控制的超参,为0时则模型退化为全监督。第一项为有监督的loss,第二项为TV正则,第三项为KL散度,最后一项为无监督loss
作者对EM算法进行修改,用于解决损失函数离散不可微的问题。E步计算代表某一混合分量的后验分布,将损失函数展开为关于GMM参数可微分的;在M步中,更新混合分布和卷积神经网络的参数
实验
作者使用两种不同的方式合成两个雨图数据集,一种作为有监督的训练集,一种分为两部分,一部分作为无监督的训练集,一部分作为验证集。因此有监督的训练集和验证集的数据分布是不同的。为了显示该模型的分布转换的能力,作者可视化了训练过程中有监督的训练集和验证集的PSNR值的变化:
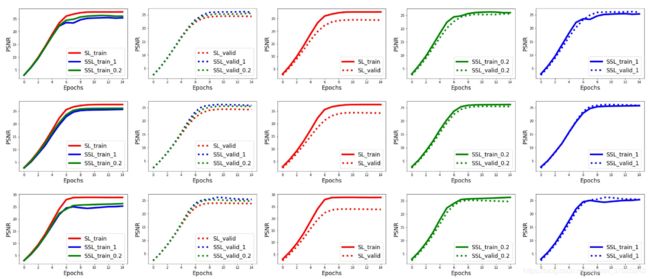
实线表示有监督的训练集,虚线表示验证集,红、绿、蓝分别代表 λ \lambda λ为0, 0.2, 1的情况,从上到下三排图像分别代表训练数据有500, 5000, 10000个图片块。从第三列可以看到,如果损失函数中不加入无监督项,随着训练过程的推进,如果训练集和验证集的数据分布不同,当训练数据增加时,模型越来越拟合训练数据,但越来越难以泛化到验证集数据。也就是说训练集的效果变好了,但是测试效果没有更好,甚至更差。但从最后两列可以看到,在加入无监督项后,这个问题得到缓解
对于PSNR指标,作者对两种场景的雨图进行测试,一种是带有雾效的大雨场景,一种是雨水比较稀疏,但深浅、长度不一的场景。与其他几种以前的无监督模型,和之后出现的有监督的深度学习模型进行对比

无监督方法
DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking[2019.12 from arxiv]
主要贡献:
- 提出无监督的注意力机制引导的雨水提取模型U-ARSE,对雨图和无雨图的空间域都使用注意力机制,使用具有两个约束分支的CycleGAN循环结构来去雨
- 模型中得到副产品:成对雨图数据集Rain200A
本文对雨图和无雨图的信息都充分利用,并且构建了两对生成器和判别器,充分利用CycleGAN的循环结构,形成一个两个分支的网络,提供更稳定的约束

模型包含三个部分:
- U-ARSE,从雨图中一阶段一阶段地提取雨水
- 两个生成器 G N G_{N} GN, G R G_{R} GR,分别生成无雨图和雨图
- 两个判别器 D N D_{N} DN, D R D_{R} DR,区分真图和G生成的图
两个分支:
- 雨-雨分支(rainy to rainy cycle-consistency branch): r − > n r − > r ~ r->n_{r}->\widetilde{r} r−>nr−>r ,用雨图生成无雨图,再重构成雨图
- 无雨-无雨分支(rain-free to rain-free cycle-consistency branch): n − > r n − > n ~ n->r_{n}->\widetilde{n} n−>rn−>n ,用无雨图生成雨图,再重构成无雨图
U-ARSE(Unsupervised Attention guided Rain Streak Extractor)
U-ARSE同时对雨图和无雨图进行关注,包含6个阶段,每个阶段包含一个Hybrid Block单元(dual-path residual dense block,双路径残差密集块),一个LSTM单元和一个CNN,如下图所示

Hybrid Block有两条路径,可以重用前一层学到的通用特征,同时学习当前层的新特征,提取雨水掩码(mask)
为了提取到准确的mask,定义了雨层注意力 A t t ( r ) Att(r) Att(r)和背景层注意力 A t t ( n ) Att(n) Att(n)上的先验作为约束,在多雨域和无雨域之间传输信息,解决两个域之间的不对称。
总的注意力损失如下:

N N N是高斯分布,N~(0,1); Z Z Z是与mask相同大小、所有值为0的分布。用 L a t t n r L_{attn_{r}} Lattnr计算 A t t ( r ) Att(r) Att(r)与N之间的均方误差;因为背景图中没有雨层,因此用 L a t t n n L_{attn_{n}} Lattnn约束 A t t ( n ) Att(n) Att(n)尽可能与0接近
Generators & Discriminators
作者使用U-Net作为G。G的输入是原始雨图与上一个U-ARSE输出的最后一个attention map的拼接
G N G_{N} GN利用雨图 r r r和 A t t r Att_{r} Attr生成无雨图 n r n_{r} nr, G r G_{r} Gr利用无雨图 n n n和 A t t n Att_{n} Attn生成雨图 r n r_{n} rn
U-ARSE从生成的 n r n_{r} nr和 r n r_{n} rn中提取到雨水信息 A t t n r Att_{n_{r}} Attnr和 A t t r n Att_{r_{n}} Attrn, G r G_{r} Gr利用无雨图 n r n_{r} nr和 A t t n r Att_{n_{r}} Attnr重构雨图 r ~ \widetilde{r} r , G n G_{n} Gn利用雨图 r n r_{n} rn和 A t t r n Att_{r_{n}} Attrn重构无雨图 n ~ \widetilde{n} n
D r D_{r} Dr用于区分真实雨图 r r r和生成的雨图 r n r_{n} rn, D n D_{n} Dn用于区分无雨图 n n n和生成的无雨图 n r n_{r} nr
D采用多尺度结构,每个尺度上的特征映射经过三个卷积层,然后输入sigmoid
模型总目标函数如下:

所有 λ \lambda λ是trade-off参数, L a t t L_{att} Latt是注意力损失, L a d v L_{adv} Ladv是对抗损失, L c c L_{cc} Lcc是在雨水域R和无雨域N上受约束的双分支的循环一致性损失函数 L c c L_{cc} Lcc(Constrained two-branch cycle-consistency loss), L p L_{p} Lp是感知损失,描述生成的无雨图 n r n_{r} nr与原始雨图之间的差异, L g m m L_{gmm} Lgmm描述用GMM(Gaussian Mixture Model)提取的雨水层, L r L_{r} Lr重构损失(reconstructive loss)对雨图 r r r与恢复的雨图 r ′ r' r′之间的不匹配进行描述
Rain200A数据集
将200张图像输入该论文模型的第二个分支: n − > r n − > n ~ n->r_{n}->\widetilde{n} n−>rn−>n ,则雨水层会被自动地加到无雨图上,得到有更多的形状和方向、更接近真实雨水的雨图。通过这个过程得到新的去雨成对数据集Rain200A
实验结果
作者给出了该模型与一些模型驱动的方法、全监督模型、半监督模型、无监督模型在三个合成数据集和一个真实数据集(SPANet-Data)上的定量比较结果。作者提出的模型完胜其他无监督模型,可以与表现最好的全监督模型抗衡,甚至可以比过半监督模型

新的数据集和指标
Single Image Deraining: A Comprehensive Benchmark Analysis[CVPR2019]
作者提出了一个新的benchmark,从多个角度评估去雨模型。整理、生成了一份大规模数据集,包括上述三种雨图的训练集,测试集中合成和真实数据集都包含。其中包含两个人工标注object bounding box的真实雨图数据集进行针对特定任务的评估
大规模数据集MPID
现有的数据集要么规模太小,要么缺少足够的真实图像来进行多样化的评估,而且没有任何一个数据集有语义标注或者考虑去雨后的图像在下游任务上的性能。作者整理、重新合成了大规模数据集MPID(Multi-Purpose Image Deraining),整体组成如下表所示
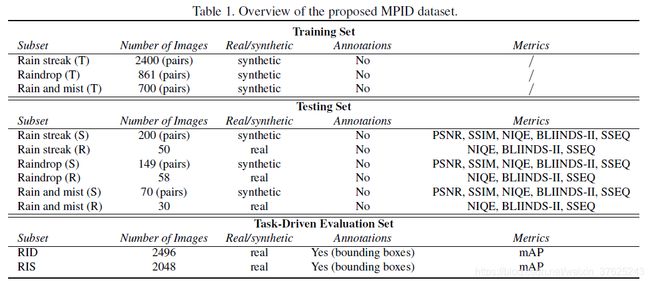
评价
-
指标比较法
作者使用了两种参照指标PSNR,SSIM和三种无参照指标NIQE, SSEQ, BLIINDSII -
人为主观比较法
作者从三种雨图模型的数据集中选取不同数量的图像,请11位评价人员对其进行打分 -
任务驱动比较法
去雨任务被视为一些下游的视觉任务(比如目标检测)的预处理步骤。因此作者希望通过实验检验经过去雨的图像是否对下游任务起到了帮助
实验结果表明,所有参与比较的现有去雨模型生成的去雨图在目标检测上的效果都比直接使用雨图要差
存在的问题
- 大部分工作中,一个监督模型在一个类型的训练集上训练,并对该类型的测试集测试,只能解决一种类型的雨水的去除
- 指标
很多研究者发现,指标显示的情况与人眼观察效果不一。如下图,指标偏向于给细节正确但是不够清晰的图打高分(中图),清晰但细节错误的图片(右图),也就是说现有的评判指标还存在一定的缺陷

- 下游任务
雨水会对图片内容造成污染。与雨图相比,生成的无雨图没有达到明显的在下游任务上的效果的提升,反而更差 - 填充不全
从图中可以看到,大部分雨水被较完美地填充,但是生成的图片仍有两个问题:
(1)颜色填补不全。从第一排中可以看到去雨效果还不错,雨水的位置应该是都找到了,但是部分区域的填充不到位,人眼可以看到明显的填补痕迹
(2)雨水重叠效应。第二排中,雨水较为“重”的位置或深浅交叠的位置,雨水去不干净