insightface心得
MXNet框架用于做图像相关的项目时,读取图像主要有两种方式:第一种是读.rec格式的文件,类似Caffe框架中LMDB,优点是.rec文件比较稳定,移植到别的电脑上也能复现,缺点是占空间(.rec文件的大小基本上和图像的存储大小差不多),而且增删数据不大灵活。第二种是.lst和图像结合的方式,首先在前面生成.rec文件的过程中也会生成.lst文件,这个.lst文件就是图像路径和标签的对应列表,也就是说通过维护这个列表来控制你训练集和测试集的变化,优点是灵活且不占空间,缺点是如果图像格式不符合要求的话容易出错而且如果列表中的某些图像路径对应的图像文件夹中图像被删除,就寻找不到,另外如果你不是从固态硬盘上读取图像的话,速度会很慢。
1、.rec
主要分两步:生成.lst和生成.rec
1.1、生成.lst
需要准备的就是你的图像。假设你的图像数据放在/home/image文件夹下,一共有10个类别,那么在/home/image文件夹下应该有10个子文件夹,每个子文件夹放属于这个类的图像文件,你可以用英文名命名这些子文件夹来表达类别,这个都无所谓,即便用1到10这10个数字来分别命名这10个子文件夹也没什么,只不过用英文名会方便你记忆这个文件夹包含的图像是属于哪个类别的。另外假设你要将生成的.lst文件放在/home/lst文件夹下,你的mxnet项目的路径是~/incubator-mxnet,那么运行下面的命令就可以生成.lst文件:
python ~/incubator-mxnet/tools/im2rec.py --list True --recursive True --train-ratio 0.9 /home/lst/data /home/image- 1
–list参数必须要是True,说明你是要生成.lst文件,–recursive参数必须为True,表示要将所有图像路径写进成.lst文件,–train-ratio参数表示将train和val以多少比例划分,默认为1,表示都是train的数据。
这样在/home/lst文件夹下就会生成data_train.lst和data_val.lst两个文件。
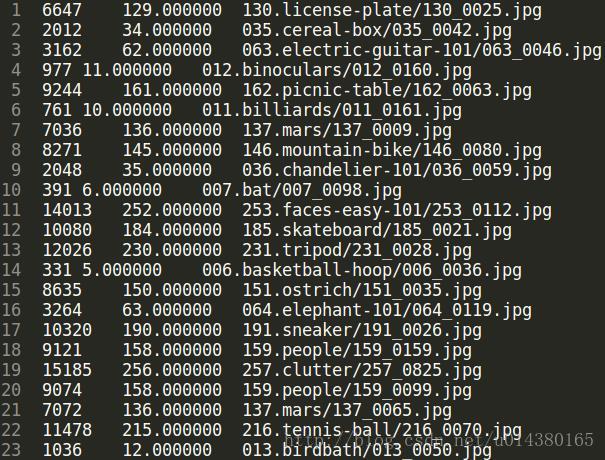
.lst文件样例:第一列是index,第二列是label,第三列是图像路径
当然有时候可能你的数据图像不是按照一个类别放在一个文件夹这种方式,那么就要考虑修改这个脚本来生成相同格式的.lst文件才能用于后续生成.rec文件。
1.2、生成.rec
需要准备的就是第一步生成的.lst文件和你的图像。
假设你要将生成的.rec文件放在.lst文件相同的/home/lst文件夹下(一般都会这样操作),那么运行下面的命令就可以生成.rec文件:
python ~/incubator-mxnet/tools/im2rec.py --num-thread 4 /home/lst /home/image- 1
这里倒数第二个参数:/home/lst是你的.lst文件所放的路径,可以不用指明.lst文件名称,因为代码会自动搜索/home/lst文件夹下所有以.lst结尾的文件。最后一个参数:/home/image是你的图像所放的路径。–num-thread 4 这个参数是表示用4个线程来执行,当你数据量较大的时候,生成.rec的过程会比较慢,所以这样可以加速。
运行成功后,在/home/rec文件夹下就生成了data_train.rec和data_val.rec文件,然后就可以用mxnet.io.ImageRecordIter类来导入.rec文件了。

另外还会生成两个.idx文件,可忽略。
2、.lst + 图像
这里.lst文件的生成和前面1.1部分的一样。然后用mxnet.image.ImageIter类来导入.lst和图像数据。可以参考博客:MXNet如何用mxnet.image.ImageIter直接导入图像
2.
Insightface制作rec和idx的训练集
要求
- 制作成rec和idx的数据集需要先对齐,使用作者的 $INSIGHTFACE/src/align 的对齐代码可以对齐并生成lst
- 需要用到property和lst,使用face2rec2.py会在指定目录下寻找lst结尾的文件,因此可把lst更名为example.lst,运行face2rec2.py会在指定目录下生成example.rec、example.idx。
- property中就定义数据集的格式,整体内容如下:1000,112,112 ,其中1000代表人脸的类别数目,图片格式为112x112。
cd $INSIGHTFACE\src\data
python face2rec2.py --encoding=.png $INSIGHTFACE/datasets/facescrubs_aligned - 1
- 2
- 过程中我将lst中的相对路径改为了绝对路径,发现相对路径会出现一些小问题

- 如果使用自己制作的lst,需要注意一下格式,据个栗子。
1 path/Adam_Brody/Adam_Brody_277.png 25
第一个参数“1”代表已对齐的图片,第二个参数代表图片的路径,第三个参数代表图片的标签编号
中间不能用空格隔开,必须用/t(TAB)隔开,用空格会报错。
2、训练模型的入口
我们知道训练一个模型需要定义一个网络结构,然后喂给这个网络数据,最后训练得到合适的模型。又因为现在基本上都是在预训练模型上做fine-tune,所以这里直接介绍MxNet里面fine-tune的快速操作。可以参看博文:MXNet的预训练:fine-tune.py源码详解。
在fine-tune.py这个脚本中,最重要的是调用了fit.fit()函数训练,这个fit.py脚本的介绍可以看博客:MXNet的训练入口:fit.py源码详解。这个脚本也是在最终训练之前封装好的一个脚本。那么具体训练的细节在哪呢?答案是base_module.py和module.py。base_module.py是MxNet训练模型的基类的脚本,而module.py则是继承base_module里面的基类的具体实现,包括前向和后向传递等等,相关的博文介绍可以参看:MXNet的训练基础脚本:base_module.py和MXNet的训练实现脚本:module.py。
3、关于数据读取和预处理
fine-tune.py这个脚本是MxNet官方写好的,默认的数据读入方式是.rec,类似Caffe里面的LMDB,关于数据读取,可以参看博文:MXNet的数据读取:data.py源码详解。这种.rec格式的数据一般需要较多的存储空间,当你需要灵活增减数据时候需要重新生成新的.rec文件,不是很灵活,因此推荐使用lst列表和原始图像结合的数据读取方式,可以参看博文:MXNet如何用mxnet.image.ImageIter直接导入图像。这种数据读取的方式还涉及图像预处理的部分,原来的MxNet项目中没有相应的例子,可以参看博文:MXNet的数据预处理:mxnet.image.CreateAugmenter源码详解。了解在mxnet.image.ImageIter中是怎么做图像预处理的。
接下来举几个例子说明,
1. 性价比最高的模型:
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train_softmax.py --network r100 --loss-type 4 --margin-m 0.5 --data-dir ../datasets/faces_ms1m_112x112 --prefix ../model-r100
--network r100 代表使用 LResNet100-IR(L和-IR是默认选项, 也可修改).
--loss-type 4和--margin-m 0.5代表使用我们的additive angular loss.
--data-dir指定训练数据目录.
--prefix指定模型输出目录.
默认的每张卡batch-size为128, 可通过--per-batch-size修改.
默认每2000个iterators输出一次验证集结果, 包括lfw,cfp,agedb-30. 可通过--verbose修改.
硬件需求: 4*P40. 如果只有12G卡的话, 参考issue 32 .
这个模型可以完美复现我们提交的MegaFace结果, 并且lfw能达到99.81或99.83.
(提供的训练数据集已经剔除了和FaceScrub重复的人物, 如果不剔除的话, MegaFace达到98.5左右都是可能的. 同时在另一个剔除LFW重复人物的实验上, LFW精度并没有降低)
2.训练MobileNetV1,Softmax.
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train_softmax.py --network m1 --loss-type 0 --data-dir ../datasets/faces_ms1m_112x112 --prefix ../model-m1-softmax
除了--network m1和--loss-type 0以外和上面的例子基本没有差别. --loss-type 0代表Softmax Loss. m1代表MobileNetV1. 我们另外还支持InceptionResNetV2, DPN, DenseNet, 等等.
3.Fine-tuning Triplet Loss, 在上述模型的基础上.
CUDA_VISIBLE_DEVICES='0,1,2,3' python -u train_softmax.py --network m1 --loss-type 12 --lr 0.005 --mom 0.0 --per-batch-size 150 --data-dir ../datasets/faces_ms1m_112x112 --pretrained ../model-m1-softmax,50 --prefix ../model-m1-triplet
注意一下后面的参数(lr, weight decay, momentum等).--loss-type 12代表Triplet Loss. 另外我们已经把semi-hard mining放入GPU计算, 极大加快了训练速度.
模型测试和部署:
0. 预训练模型下载:
0.1 LResNet50-IR: https://pan.baidu.com/s/1mj6X7MK LFW: 99.80
0.2 LResNet34-IR: https://pan.baidu.com/s/1jKahEXw LFW: 99.65. 单张图模型推理时间(包括对齐): 17ms
1. Verification Test.
lfw,cfp,agedb-30这几项已经在训练时不断被测试了. 如果想用训好的模型测试这几项得分的话, 可参考 src/eval/verification.py.
2.MegaFace Test.
参考 src/megaface/目录, 分三步走: 一、对齐FaceScrub和MegaFace distractors. 二、生成对应feature(src/megaface/gen_megaface.py), 三、运行megaface development kit.
3.模型部署.
我们提供了一些脚本, 可参考做模型部署. 值得注意的是输入的图片不需要被对齐, 只需要检测人脸后裁剪就可以.
3.1 进入deploy/文件夹.
3.2 训练或下载训好的模型.
3.3 参考 deploy/test.py 输入一张检测并切割好的面部照片, 返回512维的embedding. 利用上述的 LResNet34-IR模型, 单次推理仅需17毫秒(Intel E5-2660 @ 2.00GHz, Tesla M40).