随机森林(Random Forest )
上一篇:决策树(Decision Tree)
随机森林是一个具有高度灵活的机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,在当前的很多数据集上,相对其他算法有着很大的优势,表现良好.因为随机森林同决策树有着莫大的关系,建议读者先阅读决策树相关的文章.
其实从名字上我们就可以做一些联想.森林是什么,森林的主要构成就是树,很多很多的树,随机森林中的树就是决策树,所以随机森林就是由很多决策树构成的整体.那随机怎么理解呢?
本文的学习思路如下:
1- 现实中的随机森林
2- 随机森林的特点
3- 随机森林都有哪些随机
4- 测试随机森林
5-随机森林在数据分类上的表现
6-随机森林的优缺点
7-样例代码
1- 现实中的随机森林
有监督机器学习实际上是让机器拿着模型在数据中学习到一些规律以用来做回归和分类.拿着模型的机器是学生,数据是老师.当我们找到决策树这个老师的时候,可以从它这学到的是:模型应该先以某个维度为的值为基准,进行分裂,然后再以另一个为基准去分裂,最终得到了叶子节点,也就是决策树老师的真传.但是这有一个问题.如果我们所有的知识都从一个老师这学习,那必然会沾染上这个老师的特性,众所周知,决策树老师可是非常容易过拟合的和欠拟合的.那怎么办呢?
在现实中,学校就做了一个很好的例子.总体还是 语文/数学/英语/体育 这么多知识,我们分四个老师来教.每个老师教不同东西,在我们这个例子里边就是,每个老师拿着不同的数据集,所有老师的数据集加起来就是我们原来决策树老师的数据集.我们从不同的老师身上分别学习.那是不是每一位老师的数据集都完全不同呢?当然不是,因为语文老师和体育老师都会教你上课别迟到,数学老师和英语老师都会告诉你高中不许谈恋爱,而且很多时候,体育老师的课都给数学老师上了.所以在我们机器学习中,是从整体的数据集中随机出来很多份子数据集,可以比作有放回的随机抽样,数据集之间是有数据相同的.然后,每一份子数据集扮演原来决策树老师的角色来让我们学习,现在由众多子数据集扮演的决策树老师,我们称为子树.
还有一点需要注意,当我们问所有老师:地球有多重,语文老师的回答应该是:地球的重量等于它承载的所有生命的重量(文艺范).数学老师的回答应该是:地球重5.965×10^24kg.体育老师可能回答:我也不知道.所以,当我们由从一个老师身上学知识,所有问题的答案都来自一个老师转变成了每个问题都由多个老师回答时,我们要分别考虑老师回答的靠不靠谱,也就是给每位老师的回答加一个权重.问地球质量的问题可能数学老师的权重高,体育老师回答不知道对我们没有影响权重可以很低,而假如语文老师的文艺范并不是我们想要的内容,我们需要给他负数的权重.
再假设我们现在要买一本复习资料,而我们手上的钱只够买一本,当询问老师要买什么类型的资料时,语文老师让你买语文资料,数学老师要你买数学习题,体育老师的课不需要复习资料,但是他跟数学老师关系好,此时他建议让你买数学资料.如果这是在随机森林中,我们的结果就是买数学资料.因为投票决定的时候选择票数多的一项.
2- 随机森林的特点
以上,就是随机森林的比喻.可能太冗长又不太准确,但是我们要从中总结出随机森林的特点:
a- 随机森林是由众多的子树构成的. 每一颗子树都是由总数据集的部分数据集得来的,而且子树之间会有数据重复.
b- 选择票数多的结果作为最终结果.
c- 速度快,因为数据抽取和子树生成的过程式可以并行运算的.
当我们使用随机森林来做回归的时候,最终结果的表达就是选用了这个数据集的所有子树中这条样本被分到的叶子节点的y平均.这句话有点长不好意思.
3- 随机森林都有哪些随机
在数据集中随机出子数据集,用来生成子树,所以随机数据集的过程(这个过程叫bagging)就必须要知道,我们看随机森林都由哪些随机:
假设我们的数据集是一个表格,一行是一个样本的所有数据,一列是这个样本的一个维度.
a- 随机行数.就是选择一些样本的全部数据抽出来.
b- 随机列,把刚刚抽出来的行,再按比例或固定值随机抽几列
c- 将随机到的列也就是维度重新组合生成新的维度.
抽取数据的方法有了,那到底抽多少份呢?这个是超参数,由使用算法的人来设定.随机森林的其他超参数看下图:

上图为sklearn.ensemble包中RandomForestClassifier的构造函数,就是随机森林哈.我们可设置的超参数:
a. n_estimators : 随机森林中要多少棵子树,默认是10.
b. criterion : 设置树评判纯度的标准,默认是Gini系数
c. max_depth : 每棵树的最大深度
d. min_samples_split : 分割内部节点所需的最小样本数量
e. max_features : 每棵树保留的维度数量,默认值auto的意思是给所有维度的数开平方,得到的数是要保留维度的个数.
还有好多个,我就不再这里赘述了,大家可以到源码中看随机森林的构造方法,构造方法上面有对所有参数的详细描述.
随机分好数据集和设置参数以后,按照生成决策树的方法生成每一颗子树就行了.
4- 测试随机森林
生成模型必不可少的步骤就是验证模型,像多元线性回归,逻辑回归和刚刚提到的决策树,都是实用train_test_split()方法来将原来的数据集划分为大小不一的两份(有的时候分三份,训练集,测试集和验证集).随机森林生成的时候是以整体数据为基础进行抽样,它验证的过程有些不同.
假设我们每次随机抽样都抽取N次,1条数据N轮都没有被拿到的概率为(1 - 1/N) ^N,当N足够大时,这个式子约等于1/e,e约等于2.71828...所以我们可以粗略的估计当数据集很大时每次都大概有三分之一的数据没有被抽到.我们可以用每棵树没有抽到的三分之一数据来对这课树进行验证.虽然感觉这样需要对数据进行很多标记,但没关系,这些都是计算机来做的,咱们知道原理就行.
每一次数据抽取比作一次数据分包裹,没抽到的数据就叫做Out Of Bag Data,简称Oob data.
5-随机森林在数据分类上的表现
我们采用决策树和随机森林分别对一个数据集分类,得到的图片结果如下:
随机森林抽取一棵子树:

gc&rt就是CART树,虽然将所有红蓝点都分类了,但是结果很锐利,容易过拟合.,gt代表随机森林中的一棵树,图片中的t=1代表这是第一号树.G代表所有树的结果整合(投票).gt和G中所有的小点点代表随机森林没有抽取到的样本,也就是子树gt在分类的时候不考虑实心的小点. 因为第一张图片只随机出一棵子树,所以看着G和gt是一样的,结果并不好.
随机森林抽取100棵子树:
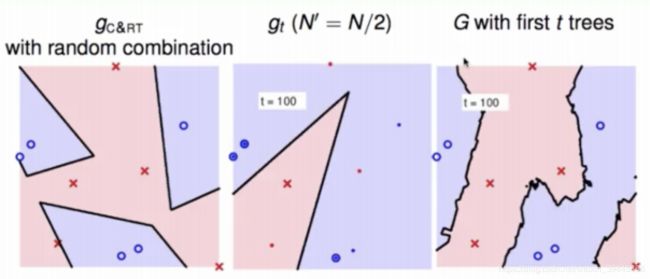
gt中t=100,代表这是第100棵子树,也就是众多子树中的一个,G代表合成的结果.可以看到结果好一些了.
随机森林抽取1000棵子树:

可以看到当抽取数量增大到某个数值后,随机森林可以很好的完成分类而且分类结果教决策树要平滑很多.这也就是为什么现在的家长喜欢给学生报课外辅导的原因,老师多了,学到的就要比其他人好.这都是有科学依据的.令狐冲称霸武林采用的也是随机森林的理论.
随机森林在复杂数据上的表现:

当大量的数据中出现垃圾数据(噪声)的时候,我们对比一下决策树和随机森林的表现:
左侧是子决策树的表现,右图是随机森林只有一棵树的时候的合成结果.因为只有一棵树,所以基本就是一样的乱.

当随机森林子树达到21棵的时候,左图是其中一棵树的结果,右图是21棵树的合成结果:

可以看到,结果已经有了很大的改善,当子树的数目增加的时候,结果还会更好.所以,随机森林是有一定的降噪能力的.
6-随机森林的优缺点
优点:
a-表现良好
b-可处理高纬度数据,因为进行了维度抽样
c-辅助进行特征选择(其实决策树也可以)
d-得益于bagging可以进行并行训练
缺点:
对于噪声过大的数据,也容易造成过拟合.
7- 样例代码
这个代码就是我从官网上拷贝的简单例子,让还没接触过随机森林的伙伴看一下怎么用而已.嘿嘿.
>>> from sklearn.ensemble import RandomForestClassifier
>>> from sklearn.datasets import make_classification
>>>
>>> X, y = make_classification(n_samples=1000, n_features=4,
... n_informative=2, n_redundant=0,
... random_state=0, shuffle=False)
>>> clf = RandomForestClassifier(max_depth=2, random_state=0)
>>> clf.fit(X, y)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=2, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=0, verbose=0, warm_start=False)
>>> print(clf.feature_importances_)
[ 0.17287856 0.80608704 0.01884792 0.00218648]
>>> print(clf.predict([[0, 0, 0, 0]]))
[1]
Ok,到这里,随机森林的内容就讲完了.谢谢您的耐心阅读.如果对您有帮助,记得点赞呦.