QDD检测框架系列(3)——EAST: An Efficient and Accurate Scene Text Detector
今天给大家介绍的是一个来自贵司的文本检测的框架,首先大家要搞清楚什么是文本检测,什么是文本识别。
文本检测,顾名思义,一般来说是指对于自然长久中存在的文字,检测出它的位置,到此为止。
而文本识别,则大不相同,他可以是文本检测的下一个步骤,他对于检测出来的文字,进行识别工作,这个字是什么?
而今天给大家介绍的这个网络就是EAST,文本检测网络。
一 模型框架
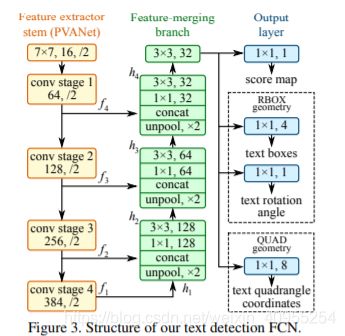
如上图所示,整个模型被分为了三个部分,第一部分特征提取,第二部分特征融合,第三部分输出。
首先介绍特征提取部分,各位看官有没有很眼熟,这不是vgg16的一些中间层嘛,对,没错。这就是vgg16的pool2到pool5四层,每一层的输出单独作为一个提取出来的特征图。从上到下,f4是原始图像的1/4,f3是原始图像的1/8,f2是原始图像的1/16。
接下来就是特征融合分支了,在这一部分作者借鉴了unet的思想,只不过unet使用的是反卷积,这里使用的操作是反池化。具体的操作流程叙述如下:对于f1,首先经过一个反池化,然后通过concat层与f2拼接,然后再通过1*1和3*3的卷积减少通道的数量,依此类推。最终得到的featuremap再通过一个卷积输出。由于在实际的场景中,文字的大小往往不是固定的,对于比较小的文字可能需要比较底层的信息,而比较大的文字则需要比较高层的信息,所以在这个网络中,我们可以看到各个层次的信息得到了比较好的融合。
最后就是输出部分了。这部分主要分为三个部分,第一部分是单个通道卷积得到的score map,然后另外一部分又分为两部分,一个是相应的几何形状结果,一个是四边形结果。对于几何形状,也就是旋转过的四边形主要是又五个通道,四个通道代表坐标,第五个通道代表旋转角度。对于四边形,则用四个顶点来表示,每个顶点两个坐标,因此一共有八个通道。
二,真实标签的生成
文中的做法是,将原始标签进行缩放作为真实的标签。那么这个缩放是如何进行的呢?以及为什么需要进行缩放呢?
首先,记四边形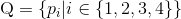 ,其中,
,其中,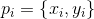 表示四边形顺时针方向的四个顶点,然后计算每个顶点
表示四边形顺时针方向的四个顶点,然后计算每个顶点 的参考长度
的参考长度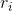 ,说简单一点,其实就是计算每个顶点相邻两条边的最短边的长度,其计算公式如下:
,说简单一点,其实就是计算每个顶点相邻两条边的最短边的长度,其计算公式如下:
其中,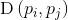 表示
表示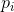 和
和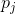 的欧式距离。
的欧式距离。
接着,对于四边形每一对对边,将两条边的长度与他们的均值进行对比,以确定出哪对对边是长边,然后对两条长边优先进行放缩,放缩的方式是对每个顶点沿着边向内部分别移动0.3
对于geometry map,对于score map为正例的像素点,其QUAD对应的标签直接是他们与四个顶点的偏移坐标,即顶点的差值,而对于RBOX,则首先会选择一个最小的矩形框住真实的四边形,然后计算每个正例像素点与该矩形四条边界的距离。具体的如图2(c)-(e)所示。
至于为什么要采用标签缩放的方式,我表示一脸懵逼,等我这两天找人讨论讨论。
3 损失函数
由于输出主要是score和box两个分支,所以损失函数相应的就也由两个部分组成。
![]()
其中,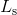 和
和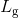 分别表示score map和geometry map的损失函数,
分别表示score map和geometry map的损失函数,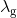 表示权重,在论文中作者设置为1。
表示权重,在论文中作者设置为1。
对于,由于其存在着类别不平衡的问题,作者引入了平衡交叉熵损失函数:

其中,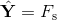 是预测出来的分数,
是预测出来的分数,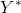 是真实的标签,
是真实的标签, 是每一张图像中负例的占比,其计算公式如下:
是每一张图像中负例的占比,其计算公式如下:

讨论完了,下面是,当geometry map采用的是RBOX时,对于RBOX中的AABB,作者采用的是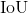 损失函数,其表达形式如下:
损失函数,其表达形式如下:

其中,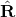 表示预测到的矩形,
表示预测到的矩形,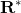 表示真实的矩形,
表示真实的矩形,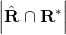 表示两个矩形的重叠面积。
表示两个矩形的重叠面积。
由于RBOX还有一个通道是表示旋转角度,因此,对于角度的损失函数计算如下:

其中,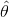 表示预测到的角度,
表示预测到的角度,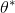 是真实的角度,最后,RBOX的损失函数如下:
是真实的角度,最后,RBOX的损失函数如下:
![]()
其中,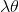 表示权重,作者在实验时取的是10。
表示权重,作者在实验时取的是10。
对于,当geometry map采用的是QUAD时,此时损失函数的计算方式与RBOX不一样,作者采用的是smoothed-L1损失函数。记一个四边形Q对应的坐标集合为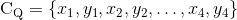 ,则QUAD对应的损失函数如下:
,则QUAD对应的损失函数如下:

其中,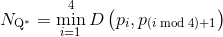 ,表示每个四边形的最小边长,而
,表示每个四边形的最小边长,而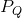 是与
是与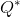 等价的四边形集合,唯一的不同就是是经过排序,因为原始数据中,的标注是无序的。
等价的四边形集合,唯一的不同就是是经过排序,因为原始数据中,的标注是无序的。
好啦,大体就介绍到这里啦,感觉读的还是不够彻底,我下午再去研读研读,晚上再做修改。
学术交流可以关注我的公众号,后台留言,粉丝不多,看到必回。卑微小钱在线祈求
