房价回归分析用svr(高斯核)、随机森林、决策树手段模拟非线性回归预测
房价回归分析用svr(高斯核)和随机森林 决策树手段模拟非线性结果
之前用线性回归的方法做了链家网房价的预测
https://blog.csdn.net/weixin_41044499/article/details/94591356
1 爬取链家网房源数据
https://blog.csdn.net/weixin_41044499/article/details/94382662
得到的数据格式如下:
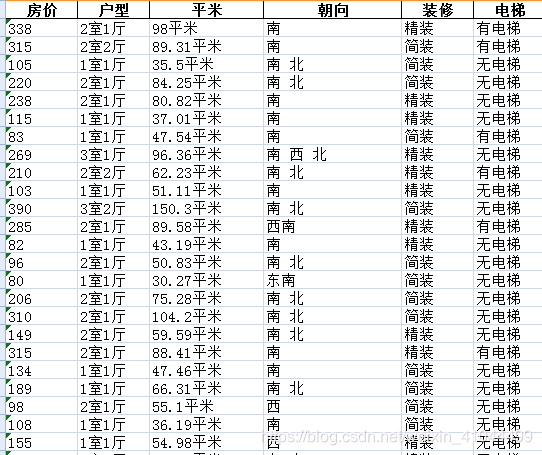
2 将所有的特征进行处理,转化为多个特征。调用skilearn的svr和随机森林 决策树等手段模拟非线性回归预测,做房价的线性回归的训练和预测
# !/usr/bin/python
# -*- coding:utf-8 -*-
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
import pandas as pd
import numpy as np
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
raw = pd.read_excel('lianjia-info.xlsx')
# 房价 户型 平米 朝向 装修 电梯
raw['装修2'] = raw['装修'].map({'精装': 3, '简装': 2, '毛坯': 1, '其他': 0})
# 将不同的朝向分别单独出来一列
raw['nan'] = raw['朝向'].apply(lambda x: '南' in x).map({True: 1, False: 0})
raw['dong'] = raw['朝向'].apply(lambda x: '东' in x).map({True: 1, False: 0})
raw['xi'] = raw['朝向'].apply(lambda x: '西' in x).map({True: 1, False: 0})
raw['bei'] = raw['朝向'].apply(lambda x: '北' in x).map({True: 1, False: 0})
# print(raw['bei'])
raw['平米2'] = raw['平米'].apply(lambda x: np.round(float(x.split('平米')[0]), 2))
# 将室和厅单独统计
raw['shi'] = raw['户型'].apply(lambda x: int(x.split('室')[0]))
raw['ting'] = raw['户型'].apply(lambda x: int(x.split('室')[1].split('厅')[0]))
print(raw['ting'])
a = {'有电梯': 1, '无电梯': 0}
raw['是否电梯'] = raw['电梯'].apply(lambda x: int(a[x]))
print(raw.ix[:, 4:].head())
raw = raw.drop(['户型', '平米', '朝向', '装修', '电梯'], axis=1)
print(raw.head())
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(raw.ix[:, 1:], raw.ix[:, 0], random_state=0, test_size=0.10)
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 使用训练数据进行参数估计
lr.fit(X_train, y_train)
# 回归预测
lr_y_predict = lr.predict(X_test)
from sklearn.metrics import r2_score
score = r2_score(y_test, lr_y_predict)
print(score)
print('SVR - RBF')
svr_rbf = svm.SVR(kernel='rbf', gamma=0.1, C=100)
svr_rbf.fit(X_train, y_train)
y_rbf = svr_rbf.predict(X_test)
score = r2_score(y_test, y_rbf)
print(score)
print('SVR - Linear')
svr_linear = svm.SVR(kernel='linear', C=10)
svr_linear.fit(X_train, y_train)
y_linear = svr_linear.predict(X_test)
score = r2_score(y_test, y_linear)
print(score)
dt = DecisionTreeRegressor(criterion='mse')
dt.fit(X_train, y_train)
y_hat = dt.predict(X_test)
score = r2_score(y_test, y_hat)
print(score)
from sklearn.ensemble import BaggingRegressor
dtr = DecisionTreeRegressor(max_depth=9)
n_estimators = 50
max_samples = 0.5
bg = BaggingRegressor(dtr, n_estimators=n_estimators, max_samples=max_samples)
bg.fit(X_train, y_train)
y_bg = bg.predict(X_test)
score = r2_score(y_test, y_bg)
print(score)
R2得分:
线性回归 0.6462123487128065
SVR - RBF 0.6098776959137255
SVR - Linear 0.6459080119847315
决策树回归 0.7205860746722759
随机森林回归 0.7155037495293906