把C语言的书读薄(一)
文章目录
- 入门:VScode 环境配置
- Using GCC with MinGW
- VScode 远程部署
- 1、理解linux服务器的VScode 运行原理
- 2、远程连接VScode——ssh
- 3、vs code 调试远程代码
- 入门:C 语言的程序结构
- 1.1 补充预处理命令:
- 1.1.1 ``# ``和``##`` 与``#define``联合使用
- 1.1.2 #define
- 1.1.3 #error
- 1.1.4 #if, #ifdef, #ifndef, #else, #elif, #endif
- 1.1.5 #include
- 1.1#line
- 1.1.7 #pragma
- 1.1.8 #undef
- 1.1.9 预定义变量
- 1.2 函数定义
- 1.3 c程序运行步骤
- 1.3.1 cpp有点不同
- 2. 入门:三种基本结构与设计方法
- 3. 入门:常量转义字符
- 3.1 补充:空字符 和 空格字符
- 3.1.1 字符
- 3.1.1.1 空字符 空格字符
- 3.2 补充 字符串
- 3.3 补充 NULL
- 4. C/C++ 数据类型
- 4.1 数据类型
- 4.2 整型数据
- 4.3 字符型数据character
- 5. C语句
- 6. C提供的标准库的输入与输出
- 6.1 补充printf("%d %c",c,c)
- 6.1 补充scanf("%d:%c",&a,&b)
- 7. 一维数组
- 8. 二维数组
- 9. 字符数组
- 10. 字符串
- 11. c标准库的字符串函数
- 12. 局部变量与全局变量的作用域
- 13. 变量的存储方式与生存期
- 14. 指针的定义
- 15. 指针指向一维数组
- 16. 指针指向多维数组
入门:VScode 环境配置
帮助文件:
默认的C++ extension不包含编译器or调试器,需要自己安装
https://code.visualstudio.com/docs/languages/cpp
Popular C++ compilers are:
GCC on Linux
GCC via Mingw-w64 on Windows
Microsoft C++ compiler on Windows
Clang for XCode on macOS
Make sure your compiler executable is in your platform path so the extension can find it. You can check availability of your C++ tools by opening the Integrated Terminal (Ctrl+`) in VS Code and try running the executable (for example g++ --help)
Using GCC with MinGW
https://code.visualstudio.com/docs/cpp/config-mingw
VScode 远程部署
1、理解linux服务器的VScode 运行原理
https://code.visualstudio.com/docs/cpp/config-linux
mkdir projects
cd projects
mkdir helloworld
cd helloworld
code .
The code .command opens VS Code in the current working folder, which becomes your "workspace".
As you go through the tutorial, you will create three files in a.vscode folder in the workspace:
- tasks.json (compiler build settings)
- launch.json (debugger settings)
- c_cpp_properties.json (compiler path and IntelliSense settings)

Build helloworld.cpp
—>This will create a tasks .json file in a .vscode folder and open it in the editor.
Debug helloworld.cpp#
—> you’ll create a launch.json file to configure VS Code to launch the GDB debugger when you press F5 to debug the program.
2、远程连接VScode——ssh
https://www.cnblogs.com/tinywan/p/11107397.html
3、vs code 调试远程代码
https://blog.csdn.net/ucmir183/article/details/93239909
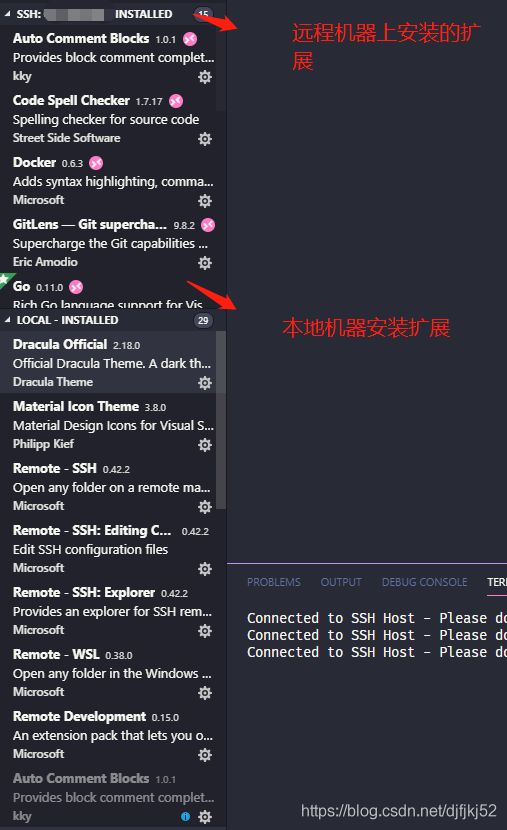
插件安装
VS Code 支持安装插件到远程主机,以增加远程代码调试的流畅性. VS Code 支持两种方式安装插件到远程主机
- 同步本地已安装插件到远程主机
- 搜索插件直接安装到远程主机
入门:C 语言的程序结构
- 一个源文件可以包括三部分:
- 1、预处理指令(例如#include #define等;预处理器会将.h头文件等内容读进来)
- 2、全局声明
- 3、函数定义
1.1 补充预处理命令:
1.1.1 #和## 与#define联合使用
1、#:使在#后的首个参数返回为一个带引号的字符串
#define to_string( s ) # s
将会使编译器把以下命令
cout << to_string( Hello World! ) << endl;
2、##:连结##前后的内容.
例如, 命令
#define concatenate( x, y ) x ## y
...
int xy = 10;
...
将会使编译器把
cout << concatenate( x, y ) << endl;
解释为
cout << xy << endl;
理所当然,将会在标准输出处显示’10’.
1.1.2 #define
语法:
#define macro-name replacement-string
#define命令用于把指定的字符串替换文件中的宏名称 . 也就是说, #define使编译器把文件中每一个macro-name替换为replacement-string. 替换的字符串结束于行末.
这里是一个经典的#define应用 (至少是在C中):
#define TRUE 1
#define FALSE 0
...
int done = 0;
while( done != TRUE ) {
...
}
#define命令的另外一个功能就是替换参数,使它 假冒创建函数一样使用. 如下的代码:
#define absolute_value( x ) ( ((x) < 0) ? -(x) : (x) )
...
int x = -1;
while( absolute_value( x ) ) {
...
}
当使用复杂的宏时,最好使用额外的圆括号. 注意在以上的例子中, 变量"x"总是出现在它自己的括号中. 这样, 它就可以在和0比较,或变成负值(乘以-1)前计算值. 同样的, 整个宏也被括号围绕, 以防止和其它代码混淆. 如果你不注意的话, 你可能会被编译器曲解你的代码.
1.1.3 #error
语法:
#error message
#error命令可以简单的使编译器在发生错误时停止. 当遇到一个#error时,编译器会自动输出行号而无论message的内容. 本命令大多是用于调试.
1.1.4 #if, #ifdef, #ifndef, #else, #elif, #endif
这些命令让编译器进行简单的逻辑控制. 当一个文件被编译时, 你可以使用这些命令使某些行保留或者是去处.
#if expression
如果表达式(expression)的值是"真"(true),那么紧随该命令的代码将会被编译.
#ifdef macro
如果"macro"已经在一个#define声明中定义了, 那么紧随该命令的代码将会被编译.
#ifndef macro
如果"macro"未在一个#define声明中定义, 那么紧随命令的代码将会被编译.
一些小边注: 命令#elif是"elseif"的一种缩写,并且他可以想你所意愿的一样工作. 你也可以在一个#if后插入一个"defined"或者"!defined"以获得更多的功能.
这里是一部分例子:
#ifdef DEBUG
cout << "This is the test version, i=" << i << endl;
#else
cout << "This is the production version!" << endl;
#endif
你应该注意到第二个例子比在你的代码中插入多个"cout"进行调试的方法更简单.
1.1.5 #include
语法:
#include
#include “filename”
本命令包含一个文件并在当前位置插入. 两种语法的主要不同之处是在于,如果filename括在尖括号中,那么编译器不知道如何搜索它. 如果它括在引号中, 那么编译器可以简单的搜索到文件. 两种搜索的方式是由编译器决定的,一般尖括号意味着在标准库目录中搜索, 引号就表示在当前目录中搜索. The spiffy new 整洁的新C++ #include目录不需要直接映射到filenames, 至少对于标准库是这样. 这就是你有时能够成功编译以下命令的原因
#include
1.1#line
语法:
#line line_number “filename”
#line命令是用于更改__LINE__ 和 __FILE__变量的值. 文件名是可选的. LINE 和 FILE 变量描述被读取的当前文件和行. 命令
#line 10 "main.cpp"
更改行号为10,当前文件改为"main.cpp".
举例:
C语言中的__FILE__用以指示本行语句所在源文件的文件。
例如:
#include
int main()
{
printf("%s\n",__FILE__);
}
在gcc编译生成a.out,执行后输出结果为:
test.c
在windows的VS2013下编译执行结果为:
d:\work\c&c++\project\project1\project1\main.cpp
C语言中的__LINE__用以指示本行语句在源文件中的位置信息,举例如下:
#include
main()
{
printf("%d\n",__LINE__);
printf("%d\n",__LINE__);
printf("%d\n",__LINE__);
};
该程序在linux用gcc编译,在windows的VS2013下编译都可以通过,执行结果都为:
7
8
9
还可以通过语句#line来重新设定__LINE__的值,举例如下:
#include
#line 200 //指定下一行的__LINE__为200
main()
{
printf("%d\n",__LINE__);
printf("%d\n",__LINE__);
printf("%d\n",__LINE__);
};
编译执行后输出结果为:
202
203
204
另外gcc还支持__func__,它指示所在的函数,但是这个关键字不被windows下的vc6.0支持,举例如下:
#include
void main()
{
printf("this is print by function %s\n",__func__);
}
其编译后输出结果为
this is print by function main
注意: “#line”、 “LINE”、 “FILE" 及 “func" 都是大小写敏感的。
参考链接:https://blog.csdn.net/SoaringLee_fighting/article/details/62050165
1.1.7 #pragma
#pragma命令可以让编程者让编译器执行某些事. 因为#pragma命令的执行很特殊,不同的编译器使用有所不同. 一个选项可以跟踪程序的执行.
1.1.8 #undef
#undef命令取消一个先前已定义的宏变量, 譬如一个用#define定义的变量.
1.1.9 预定义变量
语法:
LINE
FILE
DATE
TIME
_cplusplus
STDC
下列参数在不同的编译器可能会有所不同, 但是一般是可用的:
LINE 和 FILE 变量表示正在处理的当前行和当前文件.
DATE 变量表示当前日期,格式为month/day/year(月/日/年).
TIME 变量描述当前的时间,格式为hour:minute:second(时:分:秒).
_cplusplus 变量只在编译一个C++程序时定义.
STDC 变量在编译一个C程序时定义,编译C++时也有可能定义.
1.2 函数定义
int main(int x,int y)
int main() 或 int main(void)
每个数据声明与语句最后必须要有; 英文分号
同时,c语言不提供输入输出语句。输入输出由库函数scanf 和 printf 完成。
1.3 c程序运行步骤
1、编辑源程序
2、编译
- 先“预编译器”处理预处理指令,然后将处理的信息整合到程序的其他部分,形成一个整体,然后提交给编译系统编译
- 编译系统检查语法错误
- 编译系统将代码转化成二进制语言
3、 连接处理
- 将所有的 编译后的二进制模块,连接起来,在于函数库连接成整体,生成一个可供执行的目标函数,成为可执行程序(executive program)
- 该工作由“连接编辑程序(linkage editor)”完成
4、运行可执行程序,得到结果
1.3.1 cpp有点不同
ubuntu@ubuntu:~/Desktop/helloworldC$ ls
hello.c
ubuntu@ubuntu:~/Desktop/helloworldC$ gcc -E hello.c -o hello.i
ubuntu@ubuntu:~/Desktop/helloworldC$ ls
hello.c hello.i
ubuntu@ubuntu:~/Desktop/helloworldC$ gcc -S hello.i -o hello.s
ubuntu@ubuntu:~/Desktop/helloworldC$ gcc -c hello.s -o hello.o
ubuntu@ubuntu:~/Desktop/helloworldC$ ls
hello.c hello.i hello.o hello.s
ubuntu@ubuntu:~/Desktop/helloworldC$ gcc hello.o -o hello.exe
ubuntu@ubuntu:~/Desktop/helloworldC$ ./hello.exe
hello world!
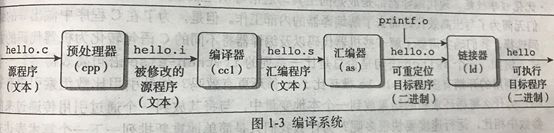
预处理阶段。预处理器(cpp)根据以字符#开头的命令,修改原始的C程序。比如hello.c中第一行的#include
编译阶段。编译器(ccl)将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。汇编语言程序中的每条语句都以一种标准的文本格式确切的描述了一条低级机器语言指令。
汇编阶段。汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种可重定位目标程序的格式,并将结果保存在目标文件hello.o中。hello.o文件是一个二进制文件,它的字节编码是机器语言指令而不是字符,如果我们在文本文件中打开hello.o文件,看到的将是一堆乱码。
链接阶段。链接器(ld)负责处理合并目标代码,生成一个可执行目标文件,可以被加载到内存中,由系统执行。
2. 入门:三种基本结构与设计方法
1、顺序结构
2、选择结构
3、循环结构
N-S 流程图
设计方法:
1、自顶而下
2、逐步细化
3、模块化设计
4、结构化编码
3. 入门:常量转义字符
常量转义字符
以下的转义字符使普通字符表示不同的意义.
转义字符 描述
\' 单引号
\" 双引号
\\ 反斜杠
\0 空字符
\a 响铃
\b 后退
\f 走纸
\n 换行
\r 回车
\t 水平制表符
\v 垂直制表符
\xnnn 表示十六进制数(nnn)
以下是使用转义字符的代码示例:
printf( “This\nis\na\ntest\n\nShe said, “How are you?”\n” );
输出:
This
is
a
test
She said, “How are you?”
3.1 补充:空字符 和 空格字符
3.1.1 字符
(1)首先必须明确字**符型(char)**是整数类型,其在内存单元是以整数形式存放。
(2)其次,char类型的产生是为了用于:存储字母、数字、标点字符、非打印字符。
(3) 为方便处理字符,用特定的整数表示特定字符,即我们看到的编码。实质上就是一种转化代替的思想,用这种编码从而去描述字符,最常用的是ASCII码。
3.1.1.1 空字符 空格字符
空字符: 字符串结尾的标志(‘\0’),实际上他的数值是0。 可以理解为标志性字符型,其使命主要是为了表明字符串已经结束。
空格字符: 空格字符( ‘’单引号中间有一个空格)的ASCII码10进制32,16进制的0X20
两者区别:
- 最直观的区别:值不同两者的ASCII不同,空(NUL)字符码值是0,而空格字符的码值是32。再者,空字符人为规定了它的使命。
附:‘0’ 的ASCII是48,不要跟前面两个混为一团。3者是完全不同的概念,其本身的整型值不同,代表的字符也不同。

参考链接:https://blog.csdn.net/jin13277480598/article/details/48088725
3.2 补充 字符串
字符串:字符串属于字符类型的派生类型(char数组)。用于字符串一定要以空字符(‘\0’)结束,故所有的字符串里面一定有一个空字符。当然空字符串(“”)也不例 外。
字符与字符串因为是两种不同的类型
3.3 补充 NULL
NULL:值为0,空值。NULL是空地址,不占用任何字节,主要是是用来给指针赋值的。其实就是0地址,这个地址在C语言里面是不允许访问的,访问会出异常。NULL一般用来初始化指针变量。
例如:
char *str = NULL; 表明该变量不指向任何有效的内存区域,避免野指针。
注意以下几点:
(1)从Stdio.h 中我们可以看出:C++中 NULL为(int)0 ,而在 C中NULL为( void* )0。据此可知在C和C++中NULL宏的值有所不同。
(2)C程序中NULL == ‘\0’为真 , 只是因为’\0’也是数值0而已,两者并不是一个意思,千万别搞混了。
(3)NULL 可以赋值给任意类型变量,相应值为空
(4)为编程规范,在定义指针时,一般需要初始化,常用NULL来初始化。
- int *p = NULL
相比直接定义int *p 而言,int *p未初始化,p是一个野指针,保存的是一个随机值 ;
int *p=NULL 已经初始化,指向一个空指针。
int *p = NULL等价于于 int *p= 0,p的值是 0x00;
int * p ,p的值是一个随机值。
参考链接:https://blog.csdn.net/jin13277480598/article/details/48088725
4. C/C++ 数据类型
C语言包含5个基本数据类型: void, integer, float, double, 和 char.
类型 描述
void 空类型
int 整型
float 浮点类型
double 双精度浮点类型
char 字符类型
C++ 定义了另外两个基本数据类型: bool 和 wchar_t.
类型 描述
bool 布尔类型, 值为true 或 false
wchar_t 宽字符类型
类型修饰符
一些基本数据类型能够被 signed, unsigned, short, 和 long 修饰. 当类型修饰符单独使用的时候, 默认的类型是 int. 下表是所有可能出现的数据类型:
bool
char
unsigned char
signed char
int
unsigned int
signed int
short int
unsigned short int
signed short int
long int
signed long int
unsigned long int
float
double
long double
wchar_t
类型大小和表示范围
基本数据类型的大小以及能够表示的数据范围是与编译器和硬件平台有关的.
“cfloat” (或者 “float.h”) 头文件往往定义了基本数据类型能够表示的数据的最大值和最小值.
你也可以使用 sizeof 来获得类型的大小(字节数) .
然而, 很多平台使用了一些数据类型的标准大小,如. int 和 float 通常占用 32位, char 占用 8位, double 通常占用64位. bools 通常以 8位 来实现.
4.1 数据类型
- 基本类型和枚举类型 的值 都是数值,统称 算数类型(arithmetic type)
- 算数类型和指针类型 为纯量类型(scalar type)
- 枚举类型是用户自定的整数类型
- 数组类型和结构体统称组合类型(aggregate type)
- 共用体不属于组合类型,因为同一时间,只有一个成员有值
4.2 整型数据
(1) 基本整型 int
在存储单元单元中:用整数的补码(compelement)存放。正数就是存储本身,负数要先转换成补码(绝对值的二进制–> 按位取反–>再加1 )
更多:《计算机原理》
4.3 字符型数据character
(1) 字符 是按照代码(整型)形式存储。属于整数类型的一种
各种字符集(包括 ASCII 码表)包含数值在0-127之间的字符
- 字母A-Z a-z
- 数字 0-9
- 专门符号 29个
- 空格符号
- 不能显示的字符
c='?'
printf("%d %c \n",c,c)
5. C语句
(1) 控制语句 9种
if else
for
while
do while
continue;不执行接下来的语句,重新开始一个循环
break:跳出循环体
switch
return
goto
(2) 函数调用语句
(3)表达式语句
(4)空语句
(5) 复合语句
6. C提供的标准库的输入与输出
#include
- putchar
- getchar
- printf
- scanf
- puts
- gets
6.1 补充printf("%d %c",c,c)
- %d 是有符号的十进制整数,
%5d 输出指定“域宽(列数)”的
%ld 长整型
- %c 输出字符
char a='y';
int b=121;
int c =377;
printf(“%c,%c ,%c ”,a,b,c);
输出-> yyy
一个整数作为%c的输入也可以。取该整数的第一个字节作为%c的控制值。
- %s 字符串
- %f 格式符,输出实数(单精度,双精度),以小数形式输出
%f 默认是整数全部+小数6位
%7.2f 表示共7列,小数2列,四舍五入。
但是需要注意:double一般只能保证15位有效;float 只能是6位有效
%-7.2f 左对齐,右端补空格
%e 指数形式。通常的编译器会选择小数字部分6位,指数部分5位 :1.234560e+002
%13.2e 也可以用来规定小数个数2个,小数点. e + 算作3个列域宽。
%o 以八进制整型输出,因此输出的数值不带符号,它会将符号位也作为八进制的一部分输出
%x 以十六进制整数输出,无符号
%u 无符号输出
%g 自动输出浮点数 ,f或者e的方式,自动选择较短的格式
6.1 补充scanf("%d:%c",&a,&b)
与printf类似
7. 一维数组
int a[n];
int a[10];
类型符 数组名[常量表达式];
int a[10]={0,1,2,3,4,5,6,7,8,9};
int a{10}={1};其他部分全部位0;
- 算数类型 默认 补充0
- 字符类型 默认位‘\0’
- 指针 默认位NULL空指针
8. 二维数组
float pay[3][6]
一般,有初始化赋值的变量申明,第一个维度的长度指定可以省略,但是第二维度的不能省略
float pay[][6]={1,2,3,4,5,6};
pay 是一个一维数组由3个元素:pay[0] pay [1] pay[2]
每个元素又是一个一维数组,包含6个元素
内存中的存放:00,01,02,03,04,05,–> 10,12,13 …
是线性存放的。
多为数组按照二维数组的意思来。
9. 字符数组
1、字符型是以整数形式(ASCII)存放。可以用整型数组存放字符数据
int a[10];
a[0]=‘c’;
因为int占用的空间更大,因此这样浪费空间
2、字符数组的初始化
char a[10]={‘i’,‘a’,‘m’};
其他位置‘\0’
10. 字符串
C语言中,字符串作为字符数组处理。
C语言中规定。’\0’作为字符串结束符,把之前的字符组成一个字符串。
在存放字符串时,系统会自动加入’\0’;
字符数组的初始化
标准方式: char a[]={‘i’,’’,‘a’,‘m’};
现在可以: char a[]={“I am”};
注意这里是使用的“” 双引号 :
但是他们 并不等价
char a[]={“I am”}; 是char a[]={‘i’,’’,‘a’,‘m’,’\0’};
11. c标准库的字符串函数
略
12. 局部变量与全局变量的作用域
略
13. 变量的存储方式与生存期
静态存储,与 ,动态存储
(1)内存的划分
1、程序区
2、静态存储区
3、动态存储区
(2)一般,全局变量都存储在静态区。
(3)在C语言中,一个变量和函数都有两个属性:数据类型和数据存储类别。
- 数据类型:在定义和声明的时候会指定
- 存储方式:用户不指定,则会采取一种默认方式
C的存储类别包含四种方式:
- 自动auto
- 静态 static
- 寄存器 register
- 外部的extern
(4) 对局部变量的三种存储位置
auto 自动分配:函数中的形参,不定义static的局部变量属于此类,程序调用结束后,自动释放。
在动态存储区
静态static 的:函数调用刚结束后也不会消失而保持数值,即占用存储单元不释放。其中,静态局部变量的值在调用结束后,依然存在,但是其他函数无法引用。
在静态存储区
寄存器 register:将局部变量存放在CPU的寄存器中,加速的存取速度。
register int f; 一般编译器会自动处理代码中频繁使用的变量,所以一般可以不去声明。
在CPU寄存器
(5)全局变量的存储位置
存放在静态存储区
但是:
- 作用域需要指定。这就要指定不同的存储类型。
一般来说:外部变量是在函数外部定义的全局变量,他的作用域是从变量的定义出开始,到程序文件的末尾。在此区域程序可以被各个函数引用。作战外部作用域,需要特殊处理。——外部变量
- extern 外部变量申明。可以从申明的地方开始,合法使用该外部变量。
该方法的使用需要慎重,因为可以通过操作改变另一个文件中的全局变量。
使用static 保护本文件的全局变量,不被其他文件引用。——静态外部变量
14. 指针的定义
1、通过变量名访问——直接访问
2、通过地址访问——间接访问
C语言中,除了定义整型,浮点型,字符变量们还可以定义一种特殊的变量,用来存放地址。
int i=10;
int *i_pointer;
i_pointer = &i;
定义指针需要指定基类型。因为需要知道数据的宽度,才能给个通过地址得到完整的数据。
&获取地址符号。&a表示a在内存中的存储地址
* 间接访问指针运算符。*p 标识指向的对象。
通过指针可以实现传过去形参,更改实参的功能,否则,你需要使用外部变量,或者使用返回值。外部变量更加繁琐,返回值的速度更慢。
15. 指针指向一维数组
1、下标法
p=&a[0];
2、指针法
p=a;
以上,是把第一个数组元素的地址赋给了p。
p+1 是把地址加上了一个数组元素的占用字节数的空间。
a+1与p+1是一样的意思。
16. 指针指向多维数组
float pay[3][6]
pay 是一个一维数组由3个元素:pay[0] pay [1] pay[2]
每个元素又是一个一维数组,包含6个元素
float *i_pointer;
i_pointer = &pay[0][0];
//等价 i_pointer = pay[0];
float (*i_pointerset)[4];
i_pointerset=pay;
//等价 i_pointerset= &pay[0];
以下四个是数组相同,但含义不相同
i_pointer :指向pay[0][0]元素的地址,通过*(p+0)访问元素
i_pointerset指向pay[0]元素的地址,通过*(*(p+0)+0)访问pay[0][0]元素
pay 指向pay[0]元素的地址
&pay[0][0]; 指向pay[0][0]元素的地址
&pay[0]; 指向pay[0]元素的地址
i_pointer+1 指向pay[0][1]的 地址
i_pointerset+1指向pay[1]的 地址
pay +1 指向pay[1]的(首)地址
pay+1=&pay[1]
所以:
*(pay+1) 和 pay[1]等价
*(pay+0) 和 pay[0]等价
虽然:
pay[0]==&pay[0] 数值上相等,但是含义不同
更确切的说:
1、pay[0] 是指向的pay[1][0]的地址,
2、恰巧pay[1][0]的地址等于pay[1]这个包含了三个小数组的元素的地址,即pay+1是pay[1] 的地址
3、导致了pay[0]==&pay[0] 数值上相等,但是含义不同
3、导致了pay[0]==pay 数值上相等,但是含义不同
3、导致了*pay==pay 数值上相等,但是含义不同
实际上:
*pay[1] 等于pay[1][0]的值
**(pay+1),是 *(*(pay+1)+0), 等于pay[1][0]的值
*(pay+1)是pay[1]
float pay[3][6]={{1},{2},{3}};
cout << pay[0] << " ";
cout << &pay[0] << " ";
cout << pay << " ";
cout << pay+1 << " ";
cout << pay[1] << " ";
cout << *(pay+1) << " ";
cout << *pay[1] << " ";
cout << **(pay+1) << " ";
cout << &pay[0] << " ";
cout << &pay[0][0] << " ";
cout << pay << " ";
cout << *pay << " ";
cout << *(&pay[0][0]) << " ";
cout << *(&pay[0]) << " ";
cout << *(pay[0]) << " ";
输出:
0x62fdbc
0x62fdbc
0x62fdbc
0x62fdd4
0x62fdd4
0x62fdd4
2
2
0x62fdbc
0x62fdbc
0x62fdbc
0x62fdbc
1
0x62fdbc
1