Logback体系架构
本文翻译自:Logback Architecture
Logback的基本架构足够通用,以适用于不同的环境。目前,Logback分为三个模块,logback-core、logback-classic和logback-access。
core模块为其他两个模块奠定了基础。classic模块扩展了core模块,相当于log4j的一个显著改进版本。logback-classic原生实现了SLF4J API,可以和其他日志系统随意地来回切换,诸如log4j、JUL等。access模块与Servlet容器集成以提供HTTP访问日志的功能。
记录器、附着器、布局
Logback建立在三个主要类的基础上:Logger、Appender、Layout。三种类型的组件协同工作,使开发人员能够根据消息类型和级别记录消息,并在运行时控制这些消息的格式和报告位置。
Logger类是classic模块的一部分,Appender和Layout接口是core模块的一部分,core作为一个通用模块,没有记录器的概念。
Logger上下文
任何日志API优于普通System.out.println的优势在于它能够禁用某些日志语句,与此同时让其他的语句不受影响地打印。该功能假设日志空间(即所有可能的日志记录语句的空间)根据某些开发人员选择的标准进行分类。在classic模块中,分类是记录器的固有部分。每一个记录器都附加到一个LoggerContext上,该LoggerContext负责生成记录器并将它们安排在层次结构树中。
记录器是命名的实体,名字大小写敏感并且遵循层次命名规则:
Named Hierarchy
A logger is said to be an ancestor of another logger if its name followed by a dot is a prefix of the descendant logger name. A logger is said to be a parent of a child logger if there are no ancestors between itself and the descendant logger.
例如:名为com.foo的记录器是名为com.foo.bar记录器的父记录器。
根记录器在记录器层次结构的顶端,它是每个层级的一部分。可以通过名字来检索记录器,如下:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);所有的记录器都可以通过org.slf4j.LoggerFactory类的静态方法getLogger来检索,方法以期望的记录器名字作为参数。Logger接口的部分基础方法如下:
package org.slf4j;
public interface Logger {
// Printing methods
public void trace(String message);
public void debug(String message);
public void info(String message);
public void warn(String message);
public void error(String message);
}有效级别和级别继承
记录器可以被赋予不同的级别。ch.qos.logback.classic.Level类定义了一个可能的级别集合,包括TRACE、DEBUG、INFO、WARN和ERROR。如果一个给定的记录器没有被分配一个级别,那么它从它最近的分配了级别的祖先继承一个级别。规则如下:
The effective level for a given logger L, is equal to the first non-null level in its hierarchy, starting at L itself and proceeding upwards in the hierarchy towards the root logger.
为确保所有的记录器最终都会继承一个级别,根记录器总时会分配一个级别,默认为DEBUG。
根据继承规则,分配级别与有效级别如下所示:
Example 1
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | none | DEBUG |
| X.Y | none | DEBUG |
| X.Y.Z | none | DEBUG |
Example 2
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | ERROR | ERROR |
| X | INFO | INFO |
| X.Y | DEBUG | DEBUG |
| X.Y.Z | WARN | WARN |
Example 3
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | INFO | INFO |
| X.Y | none | INFO |
| X.Y.Z | ERROR | ERROR |
Example 4
| Logger name | Assigned level | Effective level |
|---|---|---|
| root | DEBUG | DEBUG |
| X | INFO | INFO |
| X.Y | none | INFO |
| X.Y.Z | none | INFO |
打印方法与基础选择规则
根据定义,打印方法决定了日志记录请求的级别。例如:logger是一个记录器实例,logger.info("...")是级别为INFO的日志记录语句。
当日志记录请求的级别高于或等于记录器的有效级别时,称日志记录请求是允许的,反之请求是不允许的。基础选择规则如下:
A log request of level p issued to a logger having an effective level q, is enabled if p >= q.
级别按如下排序:TRACE < DEBUG < INFO < WARN < ERROR。
检索记录器
使用相同的名字调用LoggerFactory.getLogger方法总是会返回同一个记录器对象。
Logger x = LoggerFactory.getLogger("wombat");
Logger y = LoggerFactory.getLogger("wombat");上例中,x和y指向同一个记录器对象。
因此,可以配置一个记录器对象,然后在其他地方检索相同的实例,而不用传递引用。与生物上的父子关系(父亲永远先于孩子)不同的是,logback记录器可以以任意的顺序创建并配置。特别的是,父记录器将查找并链接到它的后代,即使它在它的后代之后被实例化。
Logback环境的配置通常在应用程序初始化时完成,首选的方法是通过读取配置文件。
Logback让以软件组件命名记录器变得简单,可以通过在每个类中以类的全限定名初始化记录器来实现,这是一种有效并且直接的定义记录器的方式。由于日志输出带有生成记录器的名称,因此该命名策略可以轻松识别日志消息的来源。当然,这仅仅只是一种可能的,尽管是通用的命名记录器的策略。Logback不限制可能的记录器集合,开发者可以随意命名日志记录器。
尽管如此,在它们所在的类中命名日志记录器似乎是目前已知的最佳策略。
附着器和布局
有选择地启用或禁用基于日志记录器的日志请求的能力只是Logback的一部分,Logback允许将日志记录请求打印到不同的目的地,在Logback中,打印输出的目的地称作附着器(Appender)。目前,支持的附着器有控制台、文件、远程socket服务器、数据库、JMS、以及远程UNIX系统日志。
可以一个日志记录器上附加多个附着器。
addAppender方法将附着器添加到指定的记录器。指定记录器的每个启用的日志记录请求将被转发到该记录器中的所有附着器以及层次结构中较高的附着器。换一种说法,附着器是是在日志记录器层次中继承而来的。例如,如果控制台附着器被添加到根日志记录器,则所有启用的日志记录请求将至少被打印到控制台。此外,如果一个文件附着器被添加到L日志记录器上,则L记录器及其所有子记录器上启用的日志记录请求将会打印到文件和控制台。可以通过将记录器的可加性标志设置为false来使附着器的累积不再具有可加性,以此来覆盖默认行为。
附着器的可加性规则如下:
Appender Additivity
The output of a log statement of logger L will go to all the appenders in L and its ancestors. This is the meaning of the term “appender additivity”.
However, if an ancestor of logger L , say P , has the additivity flag set to false, then L’s output will be directed to all the appenders in L and its ancestors up to and including P but not the appenders in any of the ancestors of P .
Loggers have their additivity flag set to true by default.
示例如下:
| Logger Name | Attached Appenders | Additivity Flag | Output Targets | Comment |
|---|---|---|---|---|
| root | A1 | not applicable | A1 | Since the root logger stands at the top of the logger hierarchy, the additivity flag does not apply to it. |
| x | A-x1, A-x2 | true | A1, A-x1, A-x2 | Appenders of “x” and of root. |
| x.y | none | true | A1, A-x1, A-x2 | Appenders of “x” and of root. |
| x.y.z | A-xyz1 | true | A1, A-x1, A-x2, A-xyz1 | Appenders of “x.y.z”, “x” and of root. |
| security | A-sec | false | A-sec | No appender accumulation since the additivity flag is set tofalse. Only appender A-sec will be used. |
| security.access | none | true | A-sec | Only appenders of “security” because the additivity flag in “security” is set tofalse. |
此外,用户可以通过将布局(Layout)与附着器相关联来自定义日志的输出格式。布局负责根据用户的意愿格式化日志记录请求,而附着器负责将格式化的输出发送到目的地。布局模式(PatternLayout)是标准的logback的一部分,让用户根据类似于C语言printf函数的转换模式来指定输出格式。
参数化日志记录
鉴于logback-classic中的Logger实现了SLF4J的Logger接口,某些打印方法会接收多个参数。这些打印方法的变体主要是为了提高性能,同时最小化对代码可读性的影响。
对于日志记录器logger,以下语句
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
将会导致构造消息参数的成本,包括将整数i和entry[i]转换为字符串并拼接中间字符串,而不论这条消息最终是否会被日志记录。
一种可行的方法是通过测试来避免不必要的参数构造,如下:
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}这样,如果为logger禁用调试,就不会产生参数构建的成本。另一方面,如果日志记录器启用了调试级别,那么将会承担两次评估logger是否启用的成本,一次在isDebugEnabled中,一次在debug中。在实践中,这个开销是不重要的,因为评估日志记录器只需要花费不到1%的时间来实际记录请求。
更优的选择
存在基于消息格式的便利替代方案,如下:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);只有在评估是否记录之后,并且确定启用时,记录器实现才会格式化消息并用对象的字符串值替换{}对。即当日志记录语句被禁用时,将不会导致参数构造成本。
以下两行将产生完全相同的日志,但是在日志记录语句禁用时,第二种变体的性能比第一种高出30倍以上。
logger.debug("The new entry is " + entry + ".");
logger.debug("The new entry is {}.", entry);此外,还提供了双参数变体形式,以及数组对象变体形式,如下:
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);执行流程
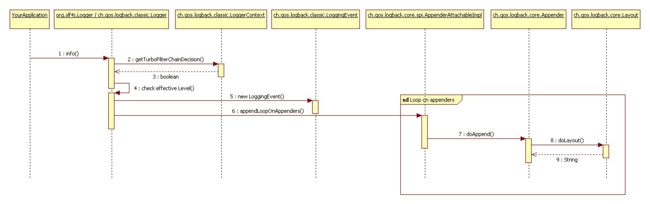
在介绍了logback的重要组件之后,接下来就可以描述当用户调用记录器的打印方法时logback框架所采取的步骤。以记录器调用info()方法为例,分析logback的执行步骤。
获取过滤器链
如果存在过滤器链,将会调用相应的方法进行过滤。如果过滤器链的返回值是
FilterReply.DENY,则日志记录请求被丢弃;如果返回值是FilterReply.NEUTRAL,则进入下一步,步骤2;如果返回值是FilterReply.ACCEPT,则跳过下一步,直接进入步骤3。运用基础选择规则
在该步中,logback比较日志记录器的有效级别与日志请求的级别,如果请求级别未启用,则丢弃请求并停止继续处理,否则进入下一步。
创建LoggingEvent对象
创建LoggingEvent对象,包含日志记录请求的所有相关参数,如请求的日志记录器、请求级别、消息本身、可能已经传递的异常、当前时间、当前线程、发出日志请求的类的各种数据以及MappedDiagnosticContext。
调用附着器
创建LoggingEvent对象后,logback会对所有可用的附着器调用
doAppend()方法。随logback一起发布的所有附着器都扩展了AppenderBase抽象类,并以同步的方式实现了doAppend()方法确保线程安全。如果自定义过滤器存在的话,AppenderBase的doAppend()方法也会调用连接到Appender的自定义过滤器。格式化输出
被调用的附着器负责格式化日志事件对象,一些(并非全部)附着器将格式化的任务委托给布局对象。布局格式化LoggingEvent实例并将结果作为字符串返回。有些附着器,如SocketAppender,不需要将日志时间对象转化为字符串,而是将其序列化,因此它们没有或者不需要布局。
发送LoggingEvent
日志记录事件在完全格式化之后,被各自的附着器发送到目的地。
以下UML时序图展示了整个执行流程。
性能
反对日志记录的常用论点之一就是其计算成本,这是合理的担忧,因为即使是中等规模的应用程序也可能产生数千个日志请求。大部分工作在于测试和调整logback的性能,此外,用户应该了解以下性能问题。
当日志记录完全关闭时,日志记录的性能
可以设置记录器级别为
Level.OFF来完全关闭日志记录,此时日志记录请求的成本包含一次方法调用和一次整数比较。对于参数构造等隐式成本,参数化日志记录小节中有描述如何提高性能。打开日志记录时,决定是否记录日志的性能
在logback中,不需要遍历记录器的层次结构,日志记录器知道它自己的有效级别。如果父日志记录器的级别被更改,则会联系所有的子日志记录器以注意更改。因此,在接受或拒绝基于有效级别的请求之前,日志记录器可以做出准瞬间决策,而无需查询其祖先。
实际的日志记录,格式化并写到输出设备
这是格式化日志输出并将其发送到目的地的成本,应努力使布局(格式化程序)尽可能快地执行,附着器亦是如此。在本地机器上,将日志记录到文件的典型成本为9~12微秒,当记录到远程数据库时成本上升到几毫秒。
虽然功能丰富,但logback的首要设计目标之一是执行速度,这是仅次于可靠性的第二大要求。