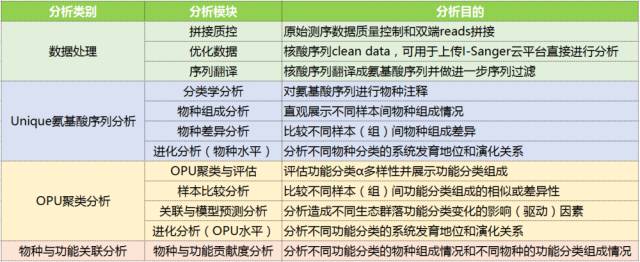
本方案整体的分析流程如下所示
功能基因多样性研究概述
本文转载自“美吉生物”,已获授权。
不知道各位从事或即将从事微生物群落功能生态学研究的大虾有没有留意到,通过功能基因扩增子测序技术研究微生物群落功能的文章,一般多会将测序获得的核酸序列通过特定软件翻译成氨基酸序列后,再进行聚类、组成、比较、差异、关联和进化等一系列分析。
比如这篇文章:

DOI:10.1038/ismej.2017.97
或者这篇:
DOI:10.3389/fmicb.2016.01894
又或者这篇:
DOI:10.1111/1462-2920.12366
那么问题来了,为什么功能基因扩增子测序可(hai)以(yao)使用氨基酸序列做分析呢?原因有如下几点:
功能生态学关注的是功能类群的多态性
对核酸序列进行有效翻译后可以进一步降低分析数据的复杂度
提高功能基因的分辨率
序列翻译过程中能够去除(矫正)4种错误序列
嵌合体序列
测序带来的插入/缺失导致的移码突变(Frame shift)
包含终止子的序列
非目的功能基因序列
因此,功能基因使用氨基酸序列分析相较于使用核酸序列分析优势尽显!
怎么做呢?Follow me!
下面小美就给大家隆重介绍一下结合科研前沿自主研发的功能基因使用氨基酸序列分析的思路!

原始数据质控拼接后获得核酸序列优化数据既可以上传I-Sanger平台直接进行36项含金量十足的交互分析;也可将核酸优化序列可以翻译成氨基酸序列,后续以氨基酸序列为数据基础分别进行Unique氨基酸序列分析和OPU聚类分析等32项前沿的线下功能基因使用氨基酸分析。
Unique氨基酸序列:使用Framebot软件将核苷酸序列翻译成氨基酸序列后,去除完全重复后的氨基酸序列,直接用于物种注释和OPU聚类分析。
OPU:即Operational Protein Unit,将Unique氨基酸序列按照一定的相似性阈值进行聚类后获得的功能分类单元,挑选每一类中丰度最高的氨基酸序列作为该OPU的代表序列并进行后续各类分析。
产品结构设置
典型分析结果展示
指数组间差异检验分析
 指数组间差异检验分析通过比较不同组间指数的差异显著性,进而评估不同组间微生物群落的丰度和多样性差异。每条柱子代表一个分组。两组样本比较结果(左图),多组样本比较结果(右图)。
指数组间差异检验分析通过比较不同组间指数的差异显著性,进而评估不同组间微生物群落的丰度和多样性差异。每条柱子代表一个分组。两组样本比较结果(左图),多组样本比较结果(右图)。
OPU多度PCA分析
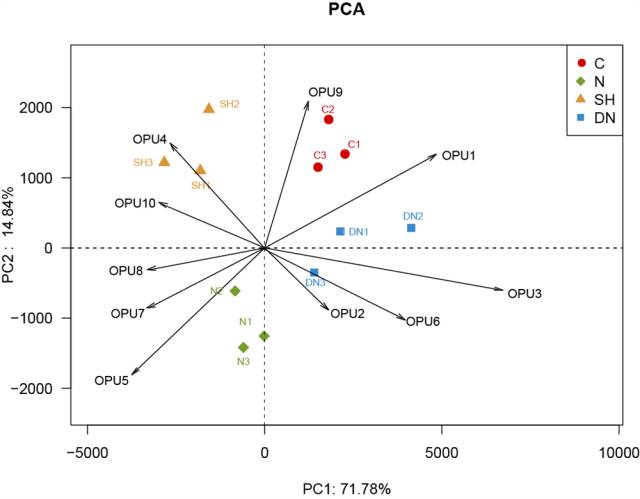
选取高丰度或感兴趣的关键OPU,在PCA分析的基础上增加OPU信息,比较该OPU在各样本中的多度(多度指群落中功能分类的频率分布)排序情况。由不同的样本向各OPU箭头做垂线,如果样本的投影点在箭头的反向延长线上,则表示该OPU在此样本中内多度小于平均值;反之,则大于平均值。
VPA分析
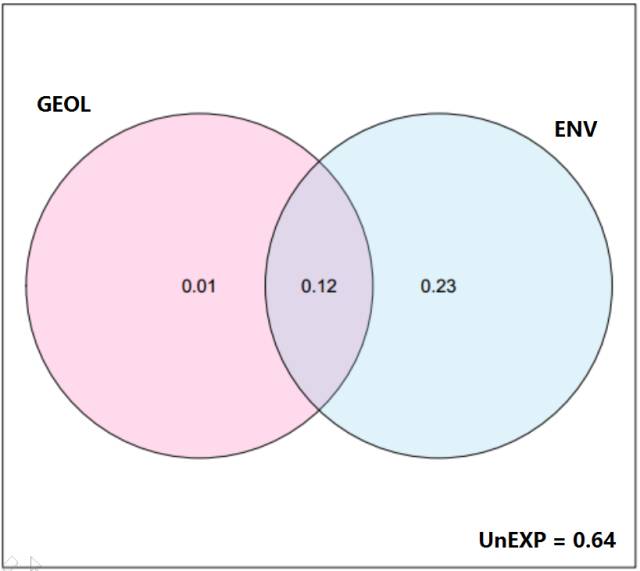
通过VPA分析,土壤性质(ENV)与地理因素(GEOL)两类环境因子各自单独对微生物群落变化的解释度分别为1%和23%,二者共同的解释度为12%,两者未解释的比例是64%。
Network网络分析
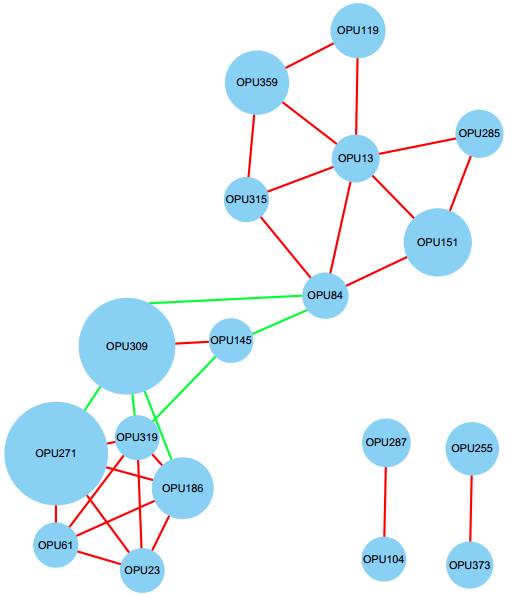
OPU相关性网络图中蓝色节点表示OPU,节点的大小表示OPU的相对丰度大小。两个节点间连接有线段时,表示这两个OPU存在一定的相关性,红色表示正相关,绿色表示负相关。
系统发生进化树(OPU水平)分析

选取特定OPU代表序列,并调取该序列在相应功能基因数据库中的Best hit序列共同构建系统发育进化树,进化树中每条树枝代表一个物种或OPU。进化分枝上的OPU后的括号中的数字为该OPU的丰度信息,物种进化分枝上后的括号中的数字为该物种对应序列的Accession Number。树枝上数字为bootstrap值。
猜你喜欢
10000+:菌群分析 宝宝与猫狗 梅毒狂想曲 提DNA发Nature Cell专刊 肠道指挥大脑
系列教程:微生物组入门 Biostar 微生物组 宏基因组
专业技能:学术图表 高分文章 生信宝典 不可或缺的人
一文读懂:宏基因组 寄生虫益处 进化树
必备技能:提问 搜索 Endnote
文献阅读 热心肠 SemanticScholar Geenmedical
扩增子分析:图表解读 分析流程 统计绘图
16S功能预测 PICRUSt FAPROTAX Bugbase Tax4Fun
在线工具:16S预测培养基 生信绘图
科研经验:云笔记 云协作 公众号
编程模板: Shell R Perl
生物科普: 肠道细菌 人体上的生命 生命大跃进 细胞暗战 人体奥秘
写在后面
为鼓励读者交流、快速解决科研困难,我们建立了“宏基因组”专业讨论群,目前己有国内外1800+ 一线科研人员加入。参与讨论,获得专业解答,欢迎分享此文至朋友圈,并扫码加主编好友带你入群,务必备注“姓名-单位-研究方向-职称/年级”。技术问题寻求帮助,首先阅读《如何优雅的提问》学习解决问题思路,仍末解决群内讨论,问题不私聊,帮助同行。

学习16S扩增子、宏基因组科研思路和分析实战,关注“宏基因组”

