Java——String对象探索
- 概述
- String 的使用方式
- 解析
- String 的拼接
- Java中仅有的重载运算符
- 引用拼接
- 字符串常量拼接
- final引用拼接
- 参考
- Java中仅有的重载运算符
- intern方法
- 已存储字符串再intern
- 池中无对应字符串
- 总结
- 参考
概述
String 对于日常代码来说是一个使用频率很高的对象,因为它的一些使用数据和基本数据类型有些相似,所以很容易把String 混淆为基本数据类型。
public final class String
implements java.io.Serializable, Comparable, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
public String() {
this.value = new char[0];
}
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
``````
} 打开Jdk 1.8String的源码 我们可以看到String 是一个被 final修饰的类,并且它的本质是使用字符数组来存储的数据 。
那么为何String要被声明成final类型呢,原因简单的说有两点: (更详细点击查看)
- 安全
class Test {
//不可变的String
public String changeStr(String s) {
s += "bbb";
return s;
}
// 可变的StringBuilder
public StringBuilder changeSb(StringBuilder sb) {
return sb.append("bbb");
}
public static void main(String[] args) {
//String做参数
String s = new String("aaa");
String ns = changeStr(s);
System.out.println("String aaa >>> " + s.toString());
// StringBuilder做参数
StringBuilder sb = new StringBuilder("aaa");
StringBuilder nsb = changeSb(sb);
System.out.println("StringBuilder aaa >>> " + sb.toString());
}
}
// Output:
//String aaa >>> aaa
//StringBuilder aaa >>> aaabbb
如果程序员不小心像上面例子里,直接在传进来的参数上加”bbb”,因为Java对象参数传的是引用,所以可变的的StringBuffer参数就被改变了。
可以看到变量sb在changeSb(sb)操作之后,就变成了”aaabbb”。有的时候这可能不是程序员的本意。所以String不可变的安全性就体现在这里。
基本数据类型传递与引用传递区别详解
当传递方法参数类型为基本数据类型时,方法不会修改基本数据类型的参数。(值拷贝)
当传递方法参数类型为引用数据类型时,方法会修改引用数据类型的参数所指向对象的值。(堆的值)
所以正是因为不可变性,String对于方法中形参值更多的是像基本数据类型属于值拷贝,正是由于String不可变的安全特征,它可以用来作为Map键值的唯一性。并且String也是使用最频繁的对象,也避免开发者的错误使用和继承,工程师们设计了完美的String类供大家使用。
- 效率/性能
在jdk 1.7之后,方法区的字符串常量池移至堆中
常量池是为了避免频繁的创建和销毁对象而影响系统性能。例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中,常量池的优点就是数据共享,例如下面代码中,我们定义了2个String类型的字符串,那么在字符串常量池中,只会存在1份”java”字面量对象。(new String(“”)情况另外下面会继续分析)
String a="java";
String b="java";这样在大量使用字符串的情况下,可以节省内存空间,提高效率。但之所以能实现这个特性,String的不可变性是最基本的一个必要条件。要是内存里字符串内容能改来改去,这么做就完全没有意义了。
String 的使用方式
相信很多 JAVA 程序员都做做类似 String s = new String(“abc”)这个语句创建了几个对象的题目。 这种题目主要就是为了考察程序员对字符串对象的常量池掌握与否。上述的语句中是创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在JAVA Heap中的 String 对象。
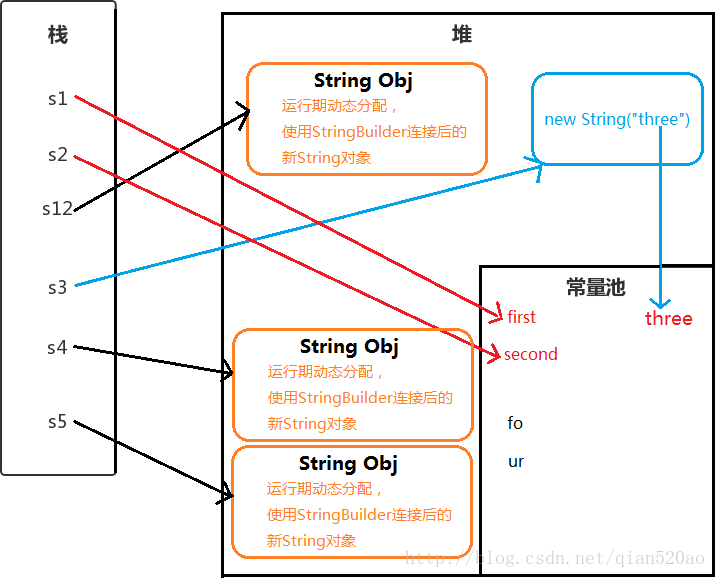
- 使用 ” ” 双引号创建 : String s1 = “first”;
- 使用字符串连接符拼接 : String s2=”se”+”cond”;
- 使用字符串加引用拼接 : String s12=”first”+s2;
- 使用new String(“”)创建 : String s3 = new String(“three”);
- 使用new String(“”)拼接 : String s4 = new String(“fo”)+”ur”;
- 使用new String(“”)拼接 : String s5 = new String(“fo”)+new String(“ur”);
解析
Java 会确保一个字符串常量只有一个拷贝。
s1 : 中的”first” 是字符串常量,在编译期就被确定了,先检查字符串常量池中是否含有”first”字符串,若没有则添加”first”到字符串常量池中,并且直接指向它。所以s1直接指向字符串常量池的”first”对象。
s2 : “se”和”cond”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,并且s2是常量池中”second”的一个引用。
s12 : JVM对于字符串引用,由于在字符串的”+”连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即
("first"+s2)无法被编译器优化,只有在程序运行期来动态分配使用StringBuilder连接后的新String对象赋给s12。
(编译器创建一个StringBuilder对象,并调用append()方法,最后调用toString()创建新String对象,以包含修改后的字符串内容)s3 : 用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
但是”three”字符串常量在编译期也会被加入到字符串常量池(如果不存在的话)s4 : 同样不能在编译期确定,但是”fo”和”ur”这两个字符串常量也会添加到字符串常量池中,并且在堆中创建String对象。(字符串常量池并不会存放”four”这个字符串)
s5 : 原理同s4。
Java堆.栈和常量池 笔记
String 的拼接
因为String对象是不可变的。String类中每一个看起来会修改String值的方法,实际上都是创建一个StringBuilder对象,并调用append()方法,最后调用toString()创建新String对象,以包含修改后的字符串内容。
Java中仅有的重载运算符
在Java中,唯一被重载的运算符就是字符串的拼接相关的。+,+=。除此之外,Java设计者不允许重载其他的运算符。
引用拼接
public class StringConcat {
String a = "hello";
String b = "moto";
String result = a + b + "2018";
}当Java编译器遇到字符串拼接的时候,会创建一个StringBuilder对象,后面的拼接,实际上是调用StringBuilder对象的append()方法。
(1)”hello” + “moto” 首先创建新的StringBuilder对象,使用append()添加”hello”和”moto”;
(2)append() 拼接”2018”;
(3)引用result 指向最终生成的String。
因为有字符串引用存在,而引用的值在程序编译期是无法确定的。另外小提示 : “hello”、”moto”和”2018”都会添加到字符串常量池中(如果没有的话),因为它们都是编译期确定的字符串常量,但是最后的”hellomoto2018”并不会添加到字符串常量池。
有兴趣的可以尝试拼接null。即String a=null;
字符串常量拼接
但是如果是下面这种拼接情况 :
public class StringConcat {
String result = "hello" + "moto" + "2018";
}“hello”、”moto”、”2018”都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以result也同样在编译期就被解析为一个字符串常量。
final引用拼接
public class StringConcat {
final String a = "hello";
final String b = "moto";
String result = a + b + "2018";
}和引用拼接中唯一不同的是a和b这两个局部变量加了final修饰。
对于final修饰的局部变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。
所以此时的(a + b + “2018”)和(“hello” + “moto” + “2018”)效果是一样的。
参考
梦工厂的简书
技术小黑屋
字符串常量池的几个问题
intern()方法
String.intern()是一个Native方法,它的作用是 : 如果字符串常量池已经包含一个等于此String对象的字符串,则返回代表字符串常量池中这个字符串的String对象;否则将此String对象的引用地址(堆中)添加到字符串常量池中。
jdk 1.7 后的字符串常量池存在于堆中。
要注意的是,String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。
在 jdk 1.6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在jdk 1.7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
已存储字符串,再intern
String aa=new String("abcdef");//"abcdef"字符串对象,创建在字符串常量池
String aaIntern=aa.intern();//aaIntern为字符串常量池的"abcdef"对象
System.out.println("aa==aaIntern "+(aa==aaIntern));//false
String aaStr="abcdef";
System.out.println("aaIntern==aaStr "+(aaIntern==aaStr));//true
System.out.println("aa==aaStr "+(aa==aaStr));//false aa在堆,aaStr在字符串常量池
首先我们要清楚这个概念 :
- 基本数据类型之间应用双等号,比较的是他们的数值。
- 复合数据类型(类)之间应用双等号,比较的是他们在内存中的存放地址。(即String中使用==对比的是内存地址)
我们先字面层来解析 :
通过new String(“abcdef”) ,创建了2个对象,堆中的String对象和存储在常量池的”abcdef”字符串(如果没有的话),aa内存地址为堆。
由于字符串常量池中存在刚刚存储的”abcdef”值,所以aa.intern()返回的是字符串常量池中”abcdef”这个字符串对象。
(aa==aaIntern),因为aa代表的是存放在堆的地址,而aaIntern是字符串常量池,所以两个值并不相等。
由于字符串常量池存在”abcdef”,所以aaStr直接指向字符串常量池。(并不会再次创建字符串对象,所以aaIntern==aaStr)
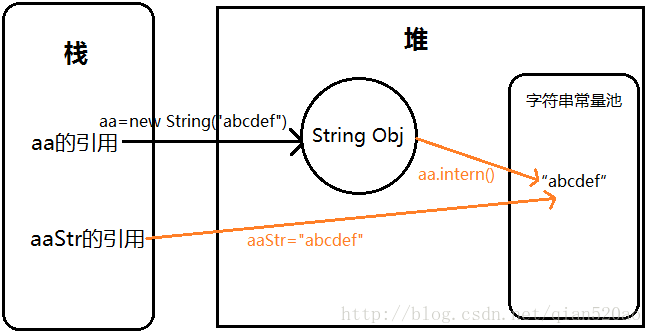
上面这个示例即已经有字符串存储于字符串常量池中了,所以intern()方法返回的是代表字符串常量池中这个字符串的String对象。
池中无对应字符串
String bb = new String("123") + "456";
String bbIntern = bb.intern();
System.out.println("bb==bbIntern " + (bb == bbIntern));// true,字符串常量池没有"123456"
String bbStr = "123456";
System.out.println("bb==bbStr " + (bb == bbStr));// true
System.out.println("bbIntern==bbStr " + (bbIntern == bbStr));// true
String cc = new String("1") + "23";
String ccIntern = cc.intern();// 字符串常量池已经有"123"
System.out.println("cc==ccIntern " + (cc == ccIntern));// false如果字符串常量池没有包含一个等于此String对象的字符串,则将此String对象的引用地址(堆中)添加到字符串常量池中。
我们先字面层来解析 :
1 . new String("123") + "456"通过拼接的方式,创建新的String对象位于堆中,并且”123”及”456”这两个字符串常量(字面量)存储至字符串常量池中。
2 . bb.intern();因为字符串常量池中没有”123456”这种拼接后的字符串,所以将堆中String对象的引用地址添加到字符串常量池中。
jdk 1.7 中字符串常量池不在 Perm (方法)区域了,字符串常量池这块做了调整。字符串常量池中不需要再存储一份字符串对象了,可以直接存储堆中的引用。这份引用指向栈中String引用的对象。也就是说引用地址是相同的。
3 . 因为bb.intern();指向的是存储在字符串常量池中bb的引用对象,所以(bb==bbIntern)
4 . 由于通过bb.intern()方法在字符串常量池中添加存在”123456”的引用,aaStr在字符串常量池中查找发现已经有该对象了(即bb的引用),所以aaStr直接指向该引用地址。
5 . String cc 是为了验证第一行代码String bb = new String("123") + "456";编译的时候已经将”123”和”456”添加至字符串常量池中了。
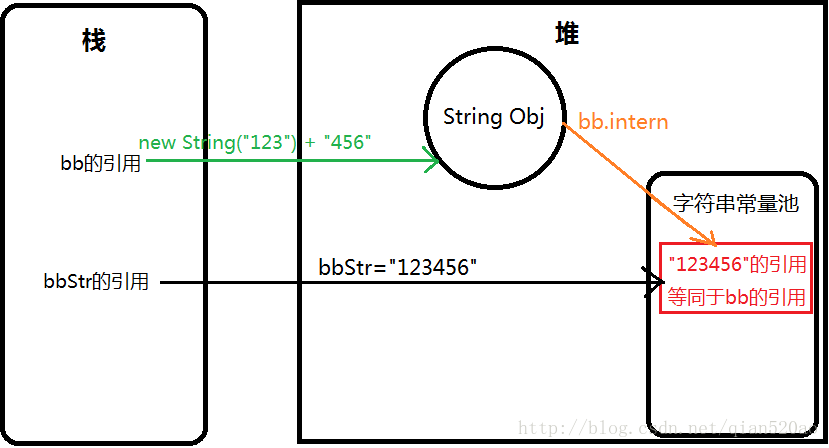
上面这个示例即通过intern()方法将对象引用添加到字符串常量池中,也就是说字符串常量池中只会存在一份String对象或者是String对象的引用。
因为字符串常量池在堆中,所以当对有这个对象的时候,没必要再多创建一份String对象。
美团点评技术团队
总结
可能有些人(包括我一开始)会觉得不就是一个String,没有必要大费周章的去研究,而且String的intern()方法很少有运用到项目中。
但是细节决定成败,但往往是这些奇技淫巧在关键时刻有着意想不到的作用。
例如 fastjson 中对所有的 json 的 key 使用了 intern 方法,缓存到了字符串常量池中,这样每次读取的时候就会非常快,大大减少时间和空间。而且 json 的 key 通常都是不变的。
但是这个地方没有考虑到大量的 json key 如果是变化的,那就会给字符串常量池带来很大的负担。
参考
String类为什么要设计成final
Java堆.栈和常量池 笔记
梦工厂的简书
技术小黑屋
字符串常量池的几个问题
美团点评技术团队