上午刚写完一篇关于一致性hash思想的举一反三,下午就去看redis的官方文档,就在我看到redis分区集群的原理的时候,哇那真是茅塞顿开把我多年对redis的疑惑都解开了,它分区的思想不就是我上篇文章的思想吗?接下来我用故事的形式来讲解redis集群,揭开它的面纱。
故事开始:小李是一家创业公司的后端开发,主要开发公司的新闻网站
第一年:小李和他的伙伴们一起吭呲吭呲把新闻网站开发好了,伙伴们都欢呼雀跃欣赏着自己作品,在上线后的一个月小李发现网站主页的新闻信息的加载速度有点慢,在用户多一点的时候更甚,作为后端扛把子小李经过仔细分析发现,每次加载新闻主页的时候有很多请求进来都去查询数据库,当用户量稍微一多,数据库就有点承受不住了,所以经过了解,小李决定给网站加一个redis用作缓存,和存储一些排名信息等,这样当有请求进来时直接先找缓存中有没有,没有再去查询数据库,加上redis是内存型数据库,网站的反应速度快了不少,小李露出了180度的微笑。
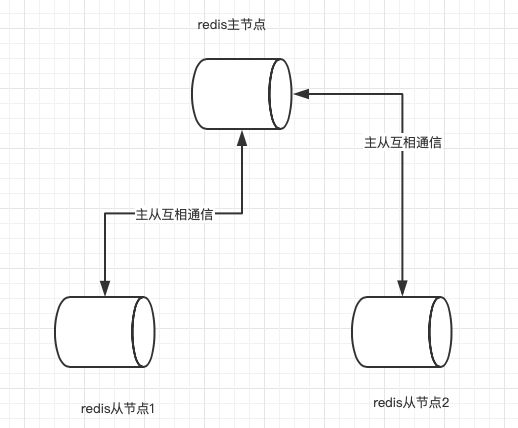
第二年:公司的发展一半靠开发一半靠运营,在运营同学的不断努力之下,网站一下有了不少人气,但在一个夜黑风高的晚上,我们的新闻网站崩了,进后台一查看原来是redis服务挂了,导致所有流量都打到了数据库上引起了一系列的反应,为此小李被运营同学骂成了马蜂窝,为了挽回尊严,小李刻苦看redis文档,马上找到一个解决方案,这次事故造成的原因主要是因为redis服务挂掉导致的,那我们就提升redis服务的可用性,于是小李按照文档搭建了一个redis主备集群,一个redis主节点,两个redis从节点,主从节点直接相互通信,从节点备份主节点的数据,当redis主节点挂了,集群会通过选举从剩余的两个从节点中选出一个来当redis主节点,这样redis集群照常对外提供服务,在客户端看来像什么都没有发生一样,就这样小李和运营同学又开始愉快的玩耍了。
第三年:运营同学不知从哪获得武功秘籍《增长黑客》,在一顿操作之下,我们的产品迎来了大量的用户,我们的新闻网站出现了有些内容加载缓慢的情况, 小李一查监控发现redis所在的服务器内存已经被用尽,有许多请求打到了数据库上,小李一查资料发现,当redis服务器内存快满时会使用操作系统的虚拟内存,这样导致出现了内存和磁盘swap区频繁切换的问题,导致效率下降。小李看完想,这不是我的锅啊,都怪用户太多了,但看着工资卡每年增长的金额,心一横就继续看redis文档,功夫不负有心人,redis分区集群不就可以完美解决问题吗,既然一台服务器的内存是4G那我们链接三台服务器不就有12G的内存了,于是小李按着文档搭建了如下集群(分区集群和主备集群的结合),果然网站再没出现过问题了,于是老板把小李给炒了。

离职时:小李收拾好东西,开始写交接文档,着重介绍关于分区集群的原理,在分区集群搭建完成后,redis会自动生成16543个槽点,然后根据我们分区的数量会把这些槽点平均分配给几个分区,如我们搭建的系统,我们建了三个分区A,B,C,那么redis会把0-5500分配给A区,5501-11001分配给B区,11002-16543分给C区,你可能会问这些槽点是什么作用,这样分配有什么效果,我们来举例,当我们往redis集群中存数据时,比方rediscl操作 set xiaoli 18,就会把往redis中存值,怎么存呢?首先reids会对key做hash运算,然后对槽点总数取模,如:hash(xiaoli)%16543=7800 运算过后我们求出取模后的值为7800,在B区的槽点范围,所以会把这对键值存取到B区,以此类推存取。如果对一致性hash有了解的话,其实这就是对一致性hash原理的一个扩展,不了解可以读我博客上一篇文章, 当分区要进行扩展时比方我们要增加D区,我们可以分别从A,B,C三个分区分别抽取1000个槽点到D区,以这种思想类推可以灵活增减分区。
以上redis分区是redis内部自己实现的,那我们客户端能不能帮他实现?答案是可以的, 不考虑主备模式的情况下, 我们在三台机器上分别起三个redis服务A,B,C, 然后我们的客户端编写这样的代码, 每次往redis中存数据前我们先对key值做hash运算,如:hash(xiaoli)%100=12,然后自己定义规则把数值等于0-33的分配给A区,34-67的分配给B区,68-100的分给C区, 我们在客户端就实现了,redis内部的功能,当我们需要增加redis服务器时原理一样修改分配规则就好了。当然更精密的可以根据一致性hash算法去实现分区的规则。
总结:理解分区集群的关键在于,了解什么是一致性哈希及其思想。