hadoop2.x之IO:序列化
序列化是指将结构化对象转化为字节流以便在网络上传输或写到磁盘进行永久存储的过程。
反序列化是指将字节流转回结构化对象的逆过程。
假设我们创建了一个类People,里面两个属性:name和age。在我们JVM没有关闭且该实例没有销毁的时候,我们可以调用这个实例。但是当我们关闭JVM等方式使该实例销毁的时候,我们将无法再使用该实例了。
而序列化实际上就是将其存储起来,例如:以JSON存储成文件,或者XML存储等方式。就是序列化的过程。当我们再次启动时,就可以读取该实例内容。
序列化在分布式数据处理的两大领域经常出现:进程间通讯和永久存储。在Hadoop中系统多节点之间的通讯是通过“远程过程调用”实现的。
1.Writable接口
Hadoop使用自己的序列化接口Writable,紧凑,速度快。
Writable定义了两个方法:
- 一个将其状态写到DataOutput二进制流。
- 一个将其DataInput二进制流中读取状态。
package org.apache.hadoop.io;
import java.io.DataOutput;
import java.io.DataInput;
import java.io.IOException;
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}通过这两个接口可以对对象进行序列化和反序列化
2. WritableComparable接口和WritableComparator类
WritableComparable继承了Writable接口和Comparable。能够实现序列化和排序。由于在MapReduce中结果都会进行排序操作,因此对于排序十分的重要。该接口允许实现直接的数据流记录排序。
WritableComparator是对WritableComparable接口的一个具体的实现。在这里我们举一个排序的列子:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparator;
public class TestWritable {
public static void main(String[] args) {
IntWritable writable = new IntWritable(10);
IntWritable writable2 = new IntWritable(20);
WritableComparator writableComparator = WritableComparator.get(IntWritable.class);
int compare = writableComparator.compare(writable, writable2);
System.out.println(compare);
}
}3. Writable实现类
Writable实现类,实现WritableComparable接口。Hadoop中有许多Writable实现类:
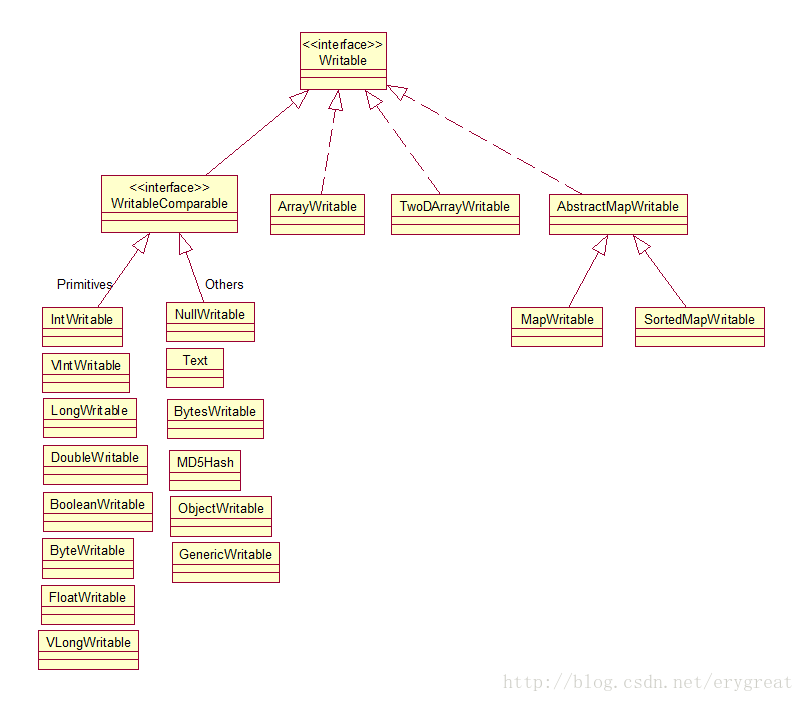
主要实现了对Java的基本类(char除外)、字符串、数组、集合等类的封装,可以使用get()和set()方法取值。
1. Java基本类
| Java基本类型 | Writable实现 | 序列化大小(字节) |
|---|---|---|
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| short | ShortWritable | 2 |
| int | IntWrtiable | 4 |
| int(变长) | VIntWriable | 1~5 |
| float | FloatWritable | 4 |
| long | LongWritable | 8 |
| long(变长) | VLongWritable | 1~9 |
| double | DoubleWritable | 8 |
对整数编码可以使用定长格式和不定长格式,不定长格式就是根据实际大小动态分配序列化的大小。
- 定长格式适合适用于到大小均匀的数值的编码,例如:都是哈希码,他的长度是固定的。
- 变长格式适用于不均匀分布的编码,这样会节省空间。另外变长的可以在VIntWritable和VLongWritabe之间
2.Text类型
Text类型是UTF-8化的Writable类。一般可以等于String类。
3.BytesWrtiable
对二进制数组数据的封装
4.NullWrtiable
他是一种特殊类型,序列化长度为0,主要用来充当占位符。
5.自定义Wrtiable
假如上面的都不满足我们的需要,我们可以自定义一个Wrtiable。例如:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
public class CustomWritable implements WritableComparable {
private IntWritable year;
private IntWritable id;
public CustomWritable(){}
public CustomWritable(int year,int id){
set(year, id);
}
public void set(int year,int id) {
this.year = new IntWritable(year);
this.id = new IntWritable(id);
}
public int getYear() {
return year.get();
}
public int getId() {
return id.get();
}
@Override
public void write(DataOutput out) throws IOException {
year.write(out);
id.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
year.readFields(in);
id.readFields(in);
}
@Override
public int compareTo(CustomWritable cw) {
if(cw.getYear() != getYear()){
return cw.getYear() > getYear() ? -1:1;
} else {
return cw.getId() > getId() ? -1:cw.getId() == getId()? 0 : 1;
}
}
}
测试:
public static void main(String[] args) {
CustomWritable cw1 = new CustomWritable(1990, 158372);
CustomWritable cw2 = new CustomWritable(1991, 158372);
CustomWritable cw3 = new CustomWritable(1990, 154372);
CustomWritable cw4 = new CustomWritable(1990, 158372);
System.out.println(cw1.compareTo(cw2)); //-1
System.out.println(cw1.compareTo(cw3)); // 1
System.out.println(cw1.compareTo(cw4)); // 0
}4. 参考资料
[1] Hadoop:The Definitive Guide,Third Edition, by Tom White. Copyright 2013 Tom White,978-1-449-31152-0