聚类 | Map-Equation多级网络聚类模型——InfoMap
受苏神的《最小熵原理(五):“层层递进”之社区发现与聚类》启发,拿来做词聚类,看苏神的贴出来的效果蛮好,就上手试了试,感觉确实不错。
最新的v1.0版本还有专门网站:https://mapequation.github.io/infomap/

文章目录
- 1 简单的理论
- 2 Benchmark
- 3 安装
- 3.1 v0.x版本
- 3.2 v1.0版本
- 4 基于infomap的词聚类
- 4.1 v0.x版本
- 4.2 v1.0版本
- 5 v1.0版本其他的一些尝试
- 5.1 Infomap + NetworkX 画图
- 5.2 v1.0版本分层infoMap——Multilayer
- 5.2.1 infomap直接初始化
- 5.2.2 network初始化
1 简单的理论
Infomap 的双层编码方式把群组识别(社区发现)同信息编码联系到了一起。一个好的群组划分,可以带来更短的编码。所以,如果能量化编码长度,找到使得长度最短的群组划分,那就找到了一个好的群组划分。
Infomap 在具体做法上,为了区分随机游走从一个群组进入到了另一个群组,除了群组的名字之外,对于每个群组的跳出动作也给予了一个编码。比如,下图(c)中红色节点部分是一个群组,群组名的编码是 111,跳出编码是 0001。这样在描述某个群组内部的一段随机游走路径的时候,总是以群组名的编码开头,以跳出编码结束。

总结一下,Infomap 算法的大体步骤如下(看起来跟 Louvain 有些许类似):
(1)初始化,对每个节点都视作独立的群组;
(2)对图里的节点随机采样出一个序列,按顺序依次尝试将每个节点赋给邻居节点所在的社区,取平均比特
下降最大时的社区赋给该节点,如果没有下降,该节点的社区不变;
(3)重复直到步骤 2 直到 L(M)不再能被优化。
2 Benchmark
参考:Source code for multilevel community detection with Infomap
该聚类方法刚好可以顺着词向量做一些词间发现,相比Kmeans之类的效果确实好不少。相比其他network 方法(Louvain)实验结果也要好一些,来看一下对比:
-
速度:运行时长
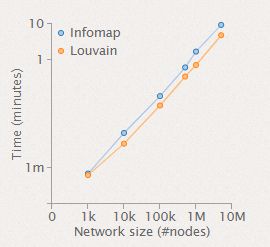
-
精确度:精度以输出群集和参考群集之间的标准化互信息(NMI)进行衡量。基准网络由5000个节点组成,社区规模在20到200之间。
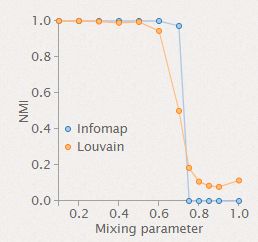
-
分层精度:该图显示了该算法很好地揭示了不同级别的三角网络中节点的层次结构(请参见下图)。
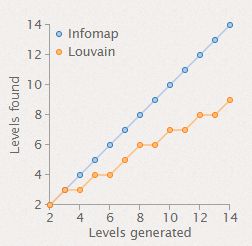
3 安装
苏神v0.x的结果和v1.0的结果有一些差异的。v0.x要比v1.0多出很多算法,而v1.0只有最简单的一种。
而且,github上挂的example都是v0.x的版本,所以如果照着example好像还得切换回去。
3.1 v0.x版本
苏神博客中所述:
wget -c https://github.com/mapequation/infomap/archive/6ab17f8b18a6fdf34b2a53454f79a3b976a49201.zip
unzip 6ab17f8b18a6fdf34b2a53454f79a3b976a49201.zip
cd infomap-6ab17f8b18a6fdf34b2a53454f79a3b976a49201
cd examples/python
make
# 编译完之后,当前目录下就会有一个infomap文件夹,就是编译好的模块;
# 为了方便调用,可以复制到python的模块文件夹(每台电脑的路径可能不一样)中
python example-simple.py
cp infomap /home/you/you/python/lib/python2.7/site-packages -rf
笔者电脑安装的时候,还要安装一个apt-get install swig
3.2 v1.0版本
pip install infomap
4 基于infomap的词聚类
两个版本中,
from infomap import infomap是v0.x版本,import infomap是v1.0版本
其中,还有一些差异:
v0.x版本还有:
node.physIndex- v0.x版本的词编号node.moduleIndex- v0.x版本的聚类编号infomapWrapper = infomap.MemInfomap("--two-level")这个好像是v0.x中特有的算法(Memory networks)tree.leafIter()- 树状结构infomapWrapper.addTrigram(3, 2, 3),v1.0没有这种形态,Trigrams represents a path from node A through B to C.
v1.0版本还有:
node.physicalId- v1.0版本的词编号node.moduleIndex()- v1.0版本的聚类编号myInfomap.iterTree()- 树状结构network = myInfomap.network()好像是v1.0独有的算法模块- 1.0不能够使用
--overlapping这样的命令,一用就卡掉。。。
两者类似的是:
- tree.numTopModules() - 聚类之后的总数,2365个聚类
- tree.codelength() - 每个聚类中平均有多少个词
- addLink(self, n1, n2, weight=1.0) - _infomap.Infomap_addLink(self, n1, n2, weight),可以[点1,点2,权重]
4.1 v0.x版本
直接看苏神的代码即可,跟Word2Vec配合,跑一个词聚类的例子,代码位于:
https://github.com/bojone/infomap/blob/master/word_cluster.py
其中相关的代码为:
from infomap import infomap
infomapWrapper = infomap.Infomap("--two-level --directed")
# 如果重叠社区发现,则只需要:
# infomapWrapper = infomap.Infomap("--two-level --directed --overlapping")
for (i, j), sim in tqdm(links.items()):
_ = infomapWrapper.addLink(i, j, sim)
infomapWrapper.run()
tree = infomapWrapper.tree
word2class = {}
class2word = {}
for node in tree.leafIter():
if id2word[node.physIndex] not in word2class:
word2class[id2word[node.physIndex]] = []
word2class[id2word[node.physIndex]].append(node.moduleIndex())
if node.moduleIndex() not in class2word:
class2word[node.moduleIndex()] = []
class2word[node.moduleIndex()].append(id2word[node.physIndex])
infomap.Infomap初始化,关于这些指令,可以在Options中找到:
– two-level:两阶段网络,Optimize a two-level partition of the network.
– 对应的
– directed :有向
–overlapping:Let nodes be part of different and overlapping modules. Applies to ordinary networks by first representing the memoryless dynamics with memory nodes.
–undirected:无向
–expanded:打印记忆网络的节点,Print the expanded network of memory nodes if possible.
–silent:No output on the console,命令中不显示结果
输出结果为:

4.2 v1.0版本
官方的小案例(参考:https://mapequation.github.io/infomap/):
import infomap
# Command line flags can be added as a string to Infomap
infomapSimple = infomap.Infomap("--two-level --directed")
# Access the default network to add links programmatically
network = myInfomap.network()
# Add weight as optional third argument
network.addLink(0, 1)
network.addLink(0, 2)
network.addLink(0, 3)
network.addLink(1, 0)
network.addLink(1, 2)
network.addLink(2, 1)
network.addLink(2, 0)
network.addLink(3, 0)
network.addLink(3, 4)
network.addLink(3, 5)
network.addLink(4, 3)
network.addLink(4, 5)
network.addLink(5, 4)
network.addLink(5, 3)
# Run the Infomap search algorithm to find optimal modules
myInfomap.run()
print("Found {} modules with codelength: {}".format(myInfomap.numTopModules(), myInfomap.codelength()))
print("Result")
print("\n#node module")
for node in myInfomap.iterTree():
if node.isLeaf():
print("{} {}".format(node.physicalId, node.moduleIndex()))
来看一下v1.0版本,跟v0.x版本还不太一样呢。
#import uniout
import numpy as np
from gensim.models import Word2Vec
from tqdm import tqdm
#from infomap import infomap # v0.x
import infomap # v1.0
num_words = 10000 # 只保留前10000个词
min_sim = 0.6
word2vec = Word2Vec.load('baike_word2vec/word2vec_baike')
word_vecs = word2vec.wv.syn0[:num_words]
word_vecs /= (word_vecs**2).sum(axis=1, keepdims=True)**0.5
id2word = word2vec.wv.index2word[:num_words]
word2id = {j: i for i, j in enumerate(id2word)}
# 构造[wordA,wordB,相似性]
links = {}
# 每个词找与它相似度不小于0.6的词(不超过50个),来作为图上的边
for i in tqdm(range(num_words)):
sims = np.dot(word_vecs, word_vecs[i])
idxs = sims.argsort()[::-1][1:]
for j in idxs[:50]:
if sims[j] >= min_sim:
links[(i, j)] = float(sims[j])
else:
break
# 方式一(infomap模型初始化):Infomap直接addLink
infomapWrapper = infomap.Infomap("--two-level --directed")
#infomapWrapper = infomap.Infomap("--two-level")
# 如果重叠社区发现,则只需要:
# infomapWrapper = infomap.Infomap("--two-level --directed --overlapping")
for (i, j), sim in tqdm(links.items()):
#print(i, j,sim)
_ = infomapWrapper.addLink(int(i), int(j),sim)
# 方式二(infomap模型初始化):network 添加addLink
infomapWrapper = infomap.Infomap("--two-level --directed")
network = infomapWrapper.network()
for (i, j), sim in tqdm(links.items()):
network.addLink(int(i), int(j),sim)
# 聚类运算
infomapWrapper.run()
# 有多少聚类数
print("Found {} modules with codelength: {}".format(infomapWrapper.numTopModules(), infomapWrapper.codelength()))
# 聚类结果显示
word2class = {}
class2word = {}
# for node in tree.leafIter():
# if id2word[node.physIndex] not in word2class:
# word2class[id2word[node.physIndex]] = []
# word2class[id2word[node.physIndex]].append(node.moduleIndex())
# if node.moduleIndex() not in class2word:
# class2word[node.moduleIndex()] = []
# class2word[node.moduleIndex()].append(id2word[node.physIndex])
for node in tree.iterTree():
if id2word[node.physicalId] not in word2class:
word2class[id2word[node.physicalId]] = [] # node.physicalId 词的编号
word2class[id2word[node.physicalId]].append(node.moduleIndex()) # node.moduleIndex() 聚类的编号
if node.moduleIndex() not in class2word:
class2word[node.moduleIndex()] = []
class2word[node.moduleIndex()].append(id2word[node.physicalId])
for i in range(100):
print('---------------')
print (class2word[i][1:])
在infomap设置的时候,v1.0还有一种network的方式。
最后输出的结果,如果是Infomap直接addLink:

如果是network 添加addLink(感觉上,使用network要好一些):

5 v1.0版本其他的一些尝试
因为v1.0版本安装非常简单,如果作者会持续优化的情况下,虽然还不如v0.x算法全,但这个版本应该比较更好(PS:v1.0的教程太少了。。)
5.1 Infomap + NetworkX 画图
这个改编自官方example一个案例,不过不知道笔者有没有写对。。。
最终效果,不如之前的 版本。
import networkx as nx
import matplotlib.pyplot as plt
import matplotlib.colors as colors
%matplotlib inline
def findCommunities(G):
"""
Partition network with the Infomap algorithm.
Annotates nodes with 'community' id and return number of communities found.
"""
infomapWrapper = infomap.Infomap("--two-level --silent")
print("Building Infomap network from a NetworkX graph...")
for e in G.edges():
infomapWrapper.addLink(*e)
print("Find communities with Infomap...")
infomapWrapper.run();
tree = infomapWrapper
print("Found %d modules with codelength: %f" % (tree.numTopModules(), tree.codelength()))
communities = {}
#for node in tree.leafIter():
for node in tree.iterTree():
#communities[node.originalLeafIndex] = node.moduleIndex()
communities[node.physicalId] = node.moduleIndex()
nx.set_node_attributes(G, name='community', values=communities)
return tree.numTopModules()
def drawNetwork(G):
# position map
pos = nx.spring_layout(G)
# community ids
communities = [v for k,v in nx.get_node_attributes(G, 'community').items()]
numCommunities = max(communities) + 1
# color map from http://colorbrewer2.org/
cmapLight = colors.ListedColormap(['#a6cee3', '#b2df8a', '#fb9a99', '#fdbf6f', '#cab2d6'], 'indexed', numCommunities)
cmapDark = colors.ListedColormap(['#1f78b4', '#33a02c', '#e31a1c', '#ff7f00', '#6a3d9a'], 'indexed', numCommunities)
# Draw edges
nx.draw_networkx_edges(G, pos)
# Draw nodes
nodeCollection = nx.draw_networkx_nodes(G,
pos = pos,
node_color = communities,
cmap = cmapLight
)
# Set node border color to the darker shade
darkColors = [cmapDark(v) for v in communities]
nodeCollection.set_edgecolor(darkColors)
# Draw node labels
for n in G.nodes():
plt.annotate(n,
xy = pos[n],
textcoords = 'offset points',
horizontalalignment = 'center',
verticalalignment = 'center',
xytext = [0, 0],
color = cmapDark(communities[n])
)
plt.axis('off')
# plt.savefig("karate.png")
plt.show()
G=nx.karate_club_graph()
findCommunities(G)
drawNetwork(G)
最终输出:
Building Infomap network from a NetworkX graph...
Find communities with Infomap...
Found 3 modules with codelength: 4.311793

其中编号为0的点有错误,笔者也没深究。。
5.2 v1.0版本分层infoMap——Multilayer
分层指的是节点本身是有层次关系的,现在很多知识图谱本来就有非常多的等级。
从实验来看,初始化状态infomap和network,应该是没差别的。
5.2.1 infomap直接初始化
import infomap
infomapWrapper = infomap.Infomap("--two-level --directed")
# from (layer, node) to (layer, node) weight
# infomapWrapper.addMultiplexLink(2, 1, 1, 2, 1.0)
# infomapWrapper.addMultiplexLink(1, 2, 2, 1, 1.0)
# infomapWrapper.addMultiplexLink(3, 2, 2, 3, 1.0)
# from (layer, node) to (layer, node) weight
infomapWrapper.addMultilayerLink(2, 1, 1, 2, 1.0)
infomapWrapper.addMultilayerLink(1, 2, 2, 1, 1.0)
infomapWrapper.addMultilayerLink(3, 2, 2, 3, 1.0)
infomapWrapper.run()
tree = infomapWrapper
print("Found %d modules with codelength: %f" % (tree.numTopModules(), tree.codelength()))
for node in tree.iterTree():
print(node.stateId,node.physicalId,node.moduleIndex(),node.path(),node.data.flow,node.data.enterFlow,node.data.exitFlow)
输出:
Found 2 modules with codelength: 0.930233
0 0 0 () 0.9999999999999998 0.0 0.0
0 0 0 (0,) 0.9302325581395346 0.0 0.0
0 1 0 (0, 0) 0.4651162790697673 0.4651162790697673 0.4651162790697673
1 2 0 (0, 1) 0.4651162790697673 0.4651162790697673 0.4651162790697673
0 0 1 (1,) 0.06976744186046516 0.0 0.0
2 2 1 (1, 0) 0.0 0.0 0.06976744186046516
3 3 1 (1, 1) 0.06976744186046516 0.06976744186046516 0.0
5.2.2 network初始化
import infomap
infomapWrapper = infomap.Infomap("--two-level --directed")
# from (layer, node) to (layer, node) weight
# infomapWrapper.addMultiplexLink(2, 1, 1, 2, 1.0)
# infomapWrapper.addMultiplexLink(1, 2, 2, 1, 1.0)
# infomapWrapper.addMultiplexLink(3, 2, 2, 3, 1.0)
network = infomapWrapper.network()
# from (layer, node) to (layer, node) weight
network.addMultilayerLink(2, 1, 1, 2, 1.0)
network.addMultilayerLink(1, 2, 2, 1, 1.0)
network.addMultilayerLink(3, 2, 2, 3, 1.0)
infomapWrapper.run()
tree = infomapWrapper
print("Found %d modules with codelength: %f" % (tree.numTopModules(), tree.codelength()))
for node in tree.iterTree():
print(node.stateId,node.physicalId,node.moduleIndex(),node.path(),node.data.flow,node.data.enterFlow,node.data.exitFlow)
输出:
Found 2 modules with codelength: 0.930233
0 0 0 () 0.9999999999999998 0.0 0.0
0 0 0 (0,) 0.9302325581395346 0.0 0.0
0 1 0 (0, 0) 0.4651162790697673 0.4651162790697673 0.4651162790697673
1 2 0 (0, 1) 0.4651162790697673 0.4651162790697673 0.4651162790697673
0 0 1 (1,) 0.06976744186046516 0.0 0.0
2 2 1 (1, 0) 0.0 0.0 0.06976744186046516
3 3 1 (1, 1) 0.06976744186046516 0.06976744186046516 0.0
其中,node.stateId 在一般的网络之中就等于node.physicalId,在分层网络addMultilayerLink中两者 才有差异。
stateId
The state node id, equals physicalId for ordinary networks
Returns
-------
unsigned int
The state node id
其中,node.depth()是节点当前的深度。
The current depth from the start node in the iterator
Returns
-------
unsigned int
The current depth
node.depth()
其中,addMultilayerLink 包括:network.addMultilayerLink(layer1, n1, layer2, n2, weight)
其中,node.data,其中的这个flow与编码相关
"""
The flow data of the node that defines:
node.data.flow
node.data.enterFlow
node.data.exitFlow
Returns
-------
FlowData
The flow data
"""
node.data
参考:
1 机器学习-社区发现算法介绍(一):Infomap
Source code for multilevel community detection with Infomap
3 Multi-level network clustering based on the Map Equation
4 最小熵原理(五):“层层递进”之社区发现与聚类
mapequation/infomap