邓滨:信号处理+深度学习才能实现语音交互

本文来自小鱼在家首席音频科学家邓滨在LiveVideoStackCon 2018讲师热身分享,并由LiveVideoStack整理而成。邓滨认为,传统的信号处理与前沿的深度学习技术结合,才能实现准确的语音交互,缺一不可。
文 / 邓滨
整理 / LiveVideoStack
直播回放:
https://www.baijiayun.com/web/playback/index?classid=18082933304314&session_id=201808300&token=HK8TUrosMf1t681rrJ0J_R1l3G4xGeRN6oakZ-l2IE6PADGtWOcHnW7r6LCYJ0wMkavU9LZ3eZYKp0fXMnVKLQ
大家好,今天与大家分享的是新潮AI硬件中的传统语音信号处理技术。
主要内容分为以下四个部分:
1、智能硬件语音交互的现实障碍
2、什么是语音前处理
3、信号处理 & 深度学习
4、语音前处理的变革演进
1、 智能硬件语音交互的现实障碍

上图是美国著名科幻电影《钢铁侠》中的几个场景,可以说这部电影全面展现了未来先进人机语音交互的强大魅力。在电影中,主角托尼·斯塔克拥有一套名叫“贾维斯”的虚拟智能管家,无论是在家中还是户外,抑或是身披战甲时托尼都可随意与其对话并发号施令,而这位虚拟管家的回复之自然如同一位真实存在的伙伴,不仅对命令的理解准确无误,还能对托尼的一些比较无厘头的笑话做出与真人类似的回应,这种强大的交互能力让每一位看过此片的观众都期待能够在现实中也拥有一位这样的虚拟智能管家。实际上依赖当前的科技水平,在真实生活场景中实现如此自然的对话,仍是一件非常困难的事情。本次分享不会涉及太多有关深度学习、神经网络、知识图谱的技术范畴,也不会过多讨论诸如ASR、IOP等有关自然语言理解能力的技术,而是主要关注语音信号的拾取优化,能否进一步提升未来自然语音交互的识别能力。
以《钢铁侠》电影中的场景为例,在实际应用中,人机语音交互面临着诸多复杂的场景:
风噪、机械振动噪声:以钢铁侠战衣飞行为代表的应用场景,战衣飞行的速度越快,其产生的风噪与机械部件摩擦振动的噪声就越严重。
枪林弹雨的爆炸声:以钢铁侠作战为代表的特殊场景,战斗时周围环境中的爆炸声会对拾音系统产生严重干扰。
远场问题:以托尼的豪宅为代表的生活场景,如何保证托尼在宽敞大客厅中任何一个角落向虚拟管家下达的指令都能被准确拾取。
混响问题:以“钢铁侠战衣”的密闭空间为代表的应用场景,此场景中声音会产生反弹折射从而造成混响干扰声音拾取。
回声问题
如果以现实生活场景为例,用户与一个人工智能硬件设备进行人机对话会面临什么样的影响呢?

上图展示的是一个包括客厅、书房、阳台、各种家具在内的非常典型的普通家庭场景,其中存在多种能够为语音交互带来干扰的环境因素。例如来自厨房的包括水流声、油烟机噪声、炒菜洗碗杂声在内的各种噪声;客厅中的人交谈说话、儿童游戏打闹的噪声;还有因远场和房间角落造成的混响,房间中的家用电器如空调、风扇、吸尘器、电视、音响等等发出的强烈噪声,窗外传来的包括汽车声、风声、雨声雷声在内的户外噪声等等。即使我们实现了在理想环境中智能语音交互的强大性能,一旦在实际应用中涉及到如远场噪声、回声等问题,人机交互的性能就会急剧下降。
为了进一步验证以上环境因素对智能语音识别系统的影响,我们使用智能音响进行了测试。
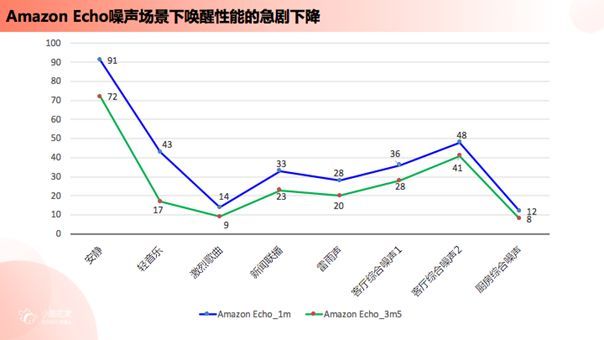
上图是我们使用世界上最著名的智能音箱之一 Amazon Echo 测试在不同噪声场景下唤醒性能波动的结果,测试方法如下:我们使用一百次100%可用的测试用例(在安静环境中距离设备非常近的条件下播放一百次唤醒指令并确保Echo唤醒成功率为100%。则视此测试用例是可用的),并分别测试了添加七种不同类型噪声:安静、轻音乐、激烈歌曲、新闻联播、雷雨声、客厅综合噪声、厨房综合噪声;同时把声源与Echo之间的距离控制在1m与3.5m两个距离量,进行唤醒测试并统计其唤醒成功率。通过测试可以发现,在安静的环境中,距离Echo 1m时唤醒成功率可保持91%左右,3.5m时则下降到72%;而在后续各种不同噪声环境中,Echo的唤醒性能急剧下降。实验结果基本验证了之前的推测:真实生活场景中的各种环境条件,的确会对人机交互识别造成不利影响。除了Amazon Echo,我们还测试了Google Home以及国内的一些智能助手。除了以上环境变量之外,我们还选择了回声、远场、混响、不同角度等干扰场景,得到的性能曲线都是类似的。
综上所述,生活中的种种干扰因素一定会对人机语音交互的性能造成很大的不利影响,而某些干扰因素就目前技术而言,是无法从根本上解决的。如果将近场、无噪声、无回声、无混响等理想环境下的语音识别作为天花板,那么不同厂商探索的在干扰环境下的高性能语音识别方案,则是致力于如何在恶劣环境下更接近这层天花板。
2、 什么是语音前处理
接下来介绍的技术是语音前处理。这种技术从何而来?因何而生的?其意义是什么?
2.1 原理
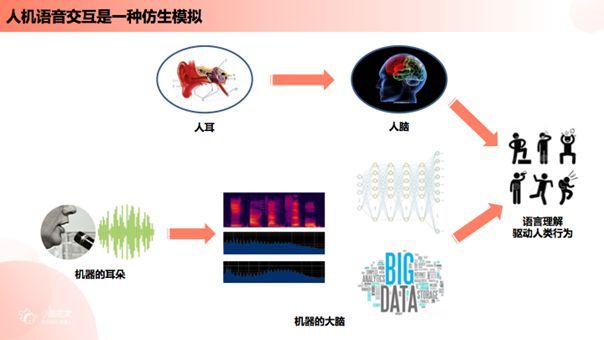
我们所谓的人机语音交互实际上是一种仿生模拟,上图第一条路径表示的是人类通过生理器官进行拾音的过程。人耳的生理构造包括耳廓、耳道、鼓膜等,外界的声波传播至耳朵,耳廓收集声波后通过耳道将其传播至鼓膜并引起鼓膜振动,鼓膜振动使声音信号通过听觉神经传递至大脑,并由大脑对接收到的声音进行辨别。这里需要强调的是,人的生理器官具有多种处理能力,例如人的耳廓与耳道具备滤波器的功能,而鼓膜与听觉神经则负责将信号放大,从而易于在声音中提炼有效信息;接下来的高级神经与大脑则具备了声纹识别、自然语言理解等语音识别的功能,最终经过大脑分捡出的有效信息则指导人类根据语言理解驱动正常的行为。
第二条路径表示的是机器进行声音拾取的过程,首先需要用于声音拾取的麦克风,在这里麦克风拾取的是模拟信号,系统需通过信号处理对模拟信号进行模数转换,从而获得声音的数字信号;与人类听觉系统类似,接下来通过数字信号领域的一系列放大、降噪、回声一致等处理,声音的清晰度与信噪比会得到显著提升,最终这些声学数字信号会被传输至机器的大脑,如深度学习或自然语言理解系统从而被转换成机器可以理解的指令。与人类的听觉系统不同,这里的麦克风明显不具备人耳的耳廓、耳道等特性,无法对声音信号进行有效的前期处理,只能最大限度地实现不失真拾音。因此我们需要在麦克风拾取原始声音的基础上进行相应的优化也就是语音“前”处理,才能得到有利于机器学习理解辨识并作出正确反馈的声学信号。
2.2 意义
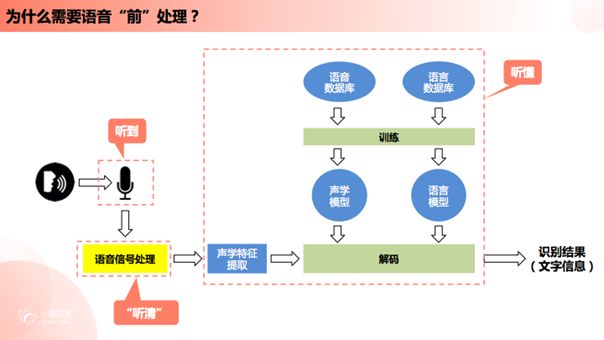
为什么需要语音“前”处理?上图表示一个比较典型的语音信号处理过程:首先,我们将麦克风拾取声音信号的过程称为“听到”,此过程的作用是将声音信息由声波形式转换成数字信号形式;随后声音信息被传输至“语音信号处理”模块,此语音数字信号处理模块的功能是“听清”,也就是对接收到的声音信号进行清晰化处理;经过清晰化处理之后的声音信号会被继续传输至文字信息识别系统,我们将文字信息识别系统中的处理过程称为“听懂”——从“听到”、“听清”到“听懂”的整体流程就是机器模拟人听觉生理活动的过程。在“听懂”部分,系统首先会对信号中的声学特征进行提取,随后根据之前整个深度学习系统经过大量标准语言训练训练得到的声学模型与语音模型进行匹配与解码,最终得到一个较为准确的文字识别结果。如果在“听到”阶段没有清晰拾得目标音频,麦克风拾取到的信号中就会包含我们上文介绍到的各种恶劣环境影响因子例如混响声音、外界噪声、回声、远场声音、衰减声音等等,倘若不处理这些混有噪音的声音信号而是直接将其送到文字识别系统就难以根据之前的标准语言训练得到的声学模型对目标声音进行识别与匹配,识别效果一定会大打折扣。因而我们必须在其中添加一个“听清”的过程,在语音识别之前加入语音信号处理模块,通常我们会把这部分流程我们称为“语音前处理”。
3、 信号处理VS深度学习
接下来我将会讲述信号处理与深度学习的关系。可以说这两者中的前者算是传统学科,后者算是前沿学科。首先需要提出以下几个问题:深度学习+大数据能否解决所有的语音干扰问题?深度学习时代的前端数字信号处理技术是否已经过时?深度学习是数字信号处理的终结吗?仅针对干扰的模型训练能够有效识别并去除干扰吗?之前我参与了有关深度学习时代信号处理没有意义的讨论,对此观点的结论是否定的。
为什么深度学习不可能代替信号处理?我们在现实生活中面临以下几大问题:
第一大问题是噪声问题。噪声分为平稳噪声与非平稳噪声,平稳噪声指的是特性相对平稳,以日常生活中的一些如白噪声、驾驶汽车匀速行驶时发动机的声音、风噪等频率特性、时变特性比较平稳的理想噪声为例;而非平稳噪声则与之相反,比较典型的例子是人说话声、KTV音乐等等。
第二大问题是回声问题,例如一个智能音箱正在播放歌曲,此时音响上的麦克风也正在工作并处于随时等待被主人唤醒的待命状态。这时,用户会希望与智能音箱进行语音交互时麦克风不会混淆拾取到的自己发出的指令声与音响喇叭放出的音乐声,此时对于用户发出的语音指令来说此音箱喇叭发出的声音就被称为“回声”;在实践中音响必须滤除此回声并保留来自用户有效的指令声才能对用户的指令做出正确反应。也许有些人会认为这与噪声类似,实际上二者并不一样,处理方法也不尽相同。
第三大问题是远场问题。用户距离智能音响比较近时可获得较为准确的语音识别体验;而一旦用户距离智能音响较远,其语音交互的性能就会急剧下降并影响用户使用智能音箱的良好体验。
第四大问题是混响问题。当将此设备摆放在墙角或较为空旷的房间时,用户发出的有效指令声经过此房间的墙壁折射反弹多次后被设备的麦克风拾取,麦克风会收到混合在一起的多个不同时间延迟下的指令声音,这种混响多次的指令也会为语音识别带来巨大干扰。
第五大问题是声音定位。围绕在此设备周围360度空间内的任何方位都有可能成为用户指令的声源位置,声音定位的目的就是瞄准用户指令声源所在的角度并进行波束集中,有效提高声音拾取的准确性。
那么这些问题可以用深度学习来有效解决吗?
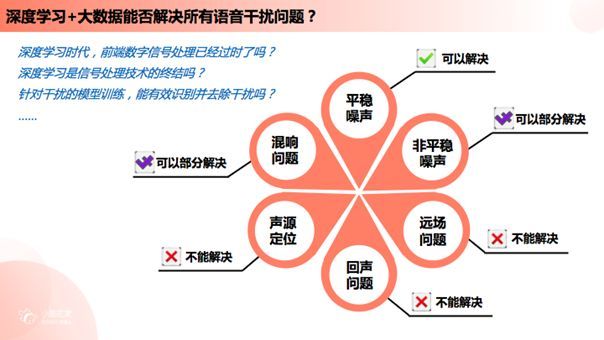
平稳噪声:可以解决
方法是针对一个干扰模型进行大量训练。例如在训练最初时向语音识别系统输入大量加噪的语料,这里的“加噪”是指加入明确希望去除的噪声类型如风噪、汽车噪声等。将此噪声提前模拟并加入训练后得到的识别系统可准确识别此噪声的声学特性,这样就可得到能够识别并处理真正含有此噪声语料的语音识别系统,增强它的鲁棒性,更有效地去除平稳噪声对有效语音的影响。
非平稳噪声:部分解决
即使绝大多数非平稳噪声无法被捕捉特性,但仍然存在少量非平稳噪声可被捕捉到特性,我们可以通过深度学习训练解决这部分非平稳噪声的干扰问题。
混响问题:部分解决
如果我们确定了某房间的混响模型,例如这间房间的空旷程度、长宽高、墙壁的材质、设备在房间中摆放的位置等,那么声音在此房间中传递、反弹再传递到设备的时长、混响效果与混响模型就是确定的,就能将其结合深度学习从而解决混响问题;如果这些场景发生了改变,那么相对应的混响模型就需要进行改变。
综上所述,深度学习可以解决平稳噪声问题与部分非平稳噪声和混响问题,但是丰富其语料模型从而达到良好训练效果的工作量很大;而通过深度学习并不能妥善解决并不具备恒定特性的远场、回声与声源定位问题,我们无法从这三者中提取有价值的模型特征的。语音识别问题归根结底是信噪比问题,我们可以把所有的干扰都视为影响原始语音信号信噪比的噪声,当信噪比不佳时系统无法从声音中提取有效信号的声音模型,语音识别就无法成功。
4、 语音前处理的变革演进
讲完了语音信号处理的前世,接下来我们谈一谈语音信号处理的今生。想必大家听完之前的分享,心中可能会产生一个疑问:我们知道语音信号处理是一个有着近百年历史的传统技术,那么传统的语音信号处理技术能否直接完美地运用于人机语音交互呢?
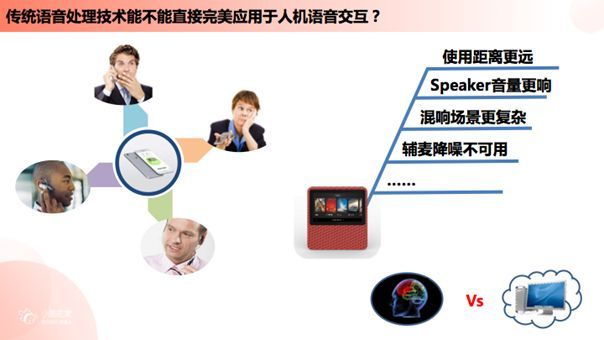
我们熟知的语音信号处理主要被应用于通信系统,而通信系统的设备处于一个较为可控的应用场景中,例如从最早的座机、固定电话到现在的移动电话,而移动电话也是从模拟信号发展到到数字电话时代,整体主要服务于包括军用步话机在内的通信场景。我们以手机为例,手机有四种通讯模式:手持、免提、插线耳机以及蓝牙耳机。对于语音信号处理来说,经过业界几十年的探索,这几种模式的发展都比较成熟,大家已经摸索出了应对这几种通讯模式较为典型的语音算法,例如免提模式下如何降噪,手持模式下可用手机多个麦克风进行降噪等。
业界应对这些传统方式都有比较成熟的方案,但是面对现在以智能音箱为例的新型人工智能硬件设备来说,其与手机的结构和应用场景完全不同,手机主要用于近场通讯,但智能音箱主要运用在中远距离通讯,且智能音箱上喇叭的功率与其播放的声音强度比手机高很多;使用距离较远就存在我之前提到的远场声音问题,与此同时麦克风所能识别到用户的指令音量也会更小而回声却会更恶劣;由于智能音箱摆放位置的多样性,其需要面临的混响环境也会更加复杂;即使智能音箱具备多个麦克风,但由于其是作为一个远场设备,我们无法使用副麦进行降噪处理。有信号处理经验的同学可能对此会比较了解,副麦降噪依赖于手持模式下主麦在用户嘴边而副麦在手机背面,只有当主麦副麦之间拾音差异在6dB以上才能实现副麦降噪,那么对于远场设备来说副麦降噪并无理论基础。
除了以上新型智能音箱人机对话与传统通讯工具手机电话之间的明显差异,人脑对语言的理解与机器之间也存在不小差异。传统的通信是人与人之间的交流,而语音识别则是人与机器之间的交流,二者本质上存在很大差别。任何的信号处理过程都会破坏语音信号声学特性,也许人能够成功识别这种破坏后的信息但机器却无法处理。因而我们需要在传统通信的语音信号处理基础上进行改进和创新,特别优化匹配语音识别的特性要求,从而让人工智能硬件既能听清楚也能讲明白,这也是所有人工智能硬件厂家核心科技之所在。
总结来说,就是从前端的信号处理与后端的识别两个层面进行系统性的综合优化,才能实现我们期待的与人工智能自然交流的美好愿景。
Q&A
Q:前端使用哪些去噪算法?
A:通常降噪有以下几类方法:
1)滤波器降噪:一种较为典型的方案,主要通过如维纳滤波这样的自适应滤波对声音进行降噪。
2)主副麦降噪:主要运用于手机等手持模式上,使用位于手机下方的主麦克风与手机背面的副麦克风进行降噪。
当用户使用手持模式拨打电话时主麦靠在嘴边而副麦朝向外界,当外界环境充斥噪声时主麦玉副麦都会收到有效语音与噪声的混合声音,但对比两个麦克风,主麦收到用户的有效语音信号更强而副麦收到外界的噪声更强,使用谱减法将主麦收到的声音减去副麦的噪声,留下的就是有效信号;再放大有效信号即可得到清晰的语音。而智能硬件无法使用副麦降噪,如果使用单麦那么我们可借助滤波与噪声估计,用估计出噪声的频谱与此噪声对比,并使用普减法从原始信号中消除噪声频谱。在这里需要强调的是我们的降噪处理最终的接收对象是谁。如果是给机器则不能破坏原始语音的声学特征,需要把降噪控制在一定的程度内。
Q:远场单通道降噪对于收益率有何影响?
A:两年前我们的小鱼在家产品就使用了单麦克风并实现降噪与语音信号放大、回声抑制、远场增强等一系列功能,提升十分明显。我们曾使用讯飞的语音识别引擎与标准接口进行对比实验,在没有添加任何其他处理算法的情况下使用讯飞识别引擎测试近场拾音,其准确率可达到100%,一旦将距离增加到1m~3m的远场,识别率会大幅度降低至50%~10%;而如果加上远场单通道语音增强算法,可将3m时10%的准确率提升至70%左右,收益十分明显。单麦算法的使用需要结合不同场景,如果现在绝大多数智能音箱为了比拼识别准确率都用麦克风阵列,在成本上则会带来很大压力,单麦算法在小型设备或低成本设备的应用前景十分广阔。
Q:智能音箱的扬声器音量是否不能过大,否则会造成强非线性影响AEC?
A:是的,这涉及到硬件的选型问题。我们知道较昂贵的扬声器其声音特性也会更出色,主要体现在线性优秀、底噪更低、失真更小、信噪比更高等。但由于受到产品的限制我们往往无法选择性能如此优秀的扬声器,因而扬声器的播放响度控制在不失真的范围内。如果一味地追求声音大而使播放出的声音信号被麦克风吸收使得频谱失真或造成非常强的非线性,那么从算法层面上来说很难解决由此带来的影响。我认为应该尽可能调试好扬声器的声学参数或从硬件选型进行控制从而达到一个音量与音质的平衡。
