对于服务器程序,I/O是制约系统性能最关键的因素。对于需要处理大量连接的高并发服务器程序,异步I/O几乎是不二的选择。Linux和Windows都为异步I/O构建了大量的基础设施。本文总结了一下Linux和Windows下的异步I/O模型,并给出了一些使用这些模型的例子。
一般来说,服务器端的I/O主要有两种情况:一是来自网络的I/O;二是对文件(设备)的I/O。Windows的异步I/O模型能很好的适用于这两种情况。而Linux针对前者提供了epoll模型,针对后者提供了AIO模型(关于是否把两者统一起来争论了很久)。
1、Linux的异步I/O(AIO)
在传统的 I/O 模型中,有一个使用惟一句柄标识的 I/O 通道。在 UNIX中,这些句柄是文件描述符(这对等同于文件、管道、套接字等等)。在阻塞 I/O 中,我们发起了一次传输操作,当传输操作完成或发生错误时,系统调用就会返回。
在异步非阻塞 I/O 中,我们可以同时发起多个传输操作。这需要每个传输操作都有惟一的上下文,这样我们才能在它们完成时区分到底是哪个传输操作完成了。在 AIO 中,这是一个 aiocb(AIO I/O Control Block)结构。这个结构包含了有关传输的所有信息,包括为数据准备的用户缓冲区。在产生 I/O (称为完成)通知时,aiocb 结构就被用来惟一标识所完成的 I/O 操作。
1.1、核心数据结构和API
1.1.1、核心数据结构
结构体aiocb是AIO的核心数据结构,它与Windows的OVERLAPPED一样,是进行异步I/O的基础。

 代码
代码
struct aiocb
{
int aio_fildes; /* File desriptor. */
int aio_lio_opcode; /* Operation to be performed,Valid only for lio_listio (r/w/nop) */
int aio_reqprio; /* Request priority offset. */
volatile void * aio_buf; /* Location of buffer. */
size_t aio_nbytes; /* Length of transfer. */
struct sigevent aio_sigevent; /* Signal number and value. */
/* Internal members. */
struct aiocb * __next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[ sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */
#endif
char __unused[ 32 ];
};
sigevent 结构告诉 AIO 在 I/O 操作完成时应该执行什么操作。
1.1.2、API
AIO 接口的 API 非常简单,但是它为数据传输提供了必需的功能,并给出了两个不同的通知模型。
| API 函数 |
说明 |
| aio_read |
请求异步读操作 |
| aio_error |
检查异步请求的状态 |
| aio_return |
获得完成的异步请求的返回状态 |
| aio_write |
请求异步写操作 |
| aio_suspend |
挂起调用进程,直到一个或多个异步请求已经完成(或失败) |
| aio_cancel |
取消异步 I/O 请求 |
| lio_listio |
发起一系列 I/O 操作 |
1.1.3、aio_read
aio_read 函数请求对一个有效的文件描述符进行异步读操作。这个文件描述符可以表示一个文件、套接字甚至管道。aio_read 函数的原型如下:
int aio_read (struct aiocb *__aiocbp)
aio_read 函数在请求进行排队之后会立即返回。如果执行成功,返回值就为 0;如果出现错误,返回值就为 -1,并设置 errno 的值。
要执行读操作,应用程序必须对 aiocb 结构进行初始化。下面这个简短的例子就展示了如何填充 aiocb 请求结构,并使用 aio_read 来执行异步读请求(现在暂时忽略通知)操作。
使用 aio_read 进行异步读操作的例子:
代码
...
int fd, ret;
struct aiocb my_aiocb;
fd = open( " file.txt " , O_RDONLY );
if (fd < 0 ) perror( " open " );
/* Zero out the aiocb structure (recommended) */
bzero( ( char * ) & my_aiocb, sizeof ( struct aiocb) );
/* Allocate a data buffer for the aiocb request */
my_aiocb.aio_buf = malloc(BUFSIZE + 1 );
if ( ! my_aiocb.aio_buf) perror( " malloc " );
/* Initialize the necessary fields in the aiocb */
my_aiocb.aio_fildes = fd;
my_aiocb.aio_nbytes = BUFSIZE;
my_aiocb.aio_offset = 0 ;
ret = aio_read( & my_aiocb );
if (ret < 0 ) perror( " aio_read " );
// 做其它操作
// … …
// 等待I/O完成
while ( aio_error( & my_aiocb ) == EINPROGRESS ) ;
if ((ret = aio_return( & my_iocb )) > 0 ) {
/* got ret bytes on the read */
} else {
/* read failed, consult errno */
}
注意使用这个 API 与标准的库函数从文件中读取内容是非常相似的。除了 aio_read 的一些异步特性之外,另外一个区别是读操作偏移量的设置。在传统的 read 调用中,偏移量是在文件描述符上下文中进行维护的。对于每个读操作来说,偏移量都需要进行更新,这样后续的读操作才能对下一块数据进行寻址。对于异步 I/O 操作来说这是不可能的,因为我们可以同时执行很多读请求,因此必须为每个特定的读请求都指定偏移量。
1.1.4、aio_error
aio_error 函数被用来确定请求的状态。其原型如下:
int aio_error (__const struct aiocb *__aiocbp)
这个函数可以返回以下内容:
•EINPROGRESS,说明请求尚未完成
•ECANCELLED,说明请求被应用程序取消了
•-1,说明发生了错误,具体错误原因可以查阅 errno
1.1.5、aio_return
异步 I/O 和标准块 I/O 之间的另外一个区别是我们不能立即访问这个函数的返回状态,因为我们并没有阻塞在 read 调用上。在标准的 read 调用中,返回状态是在该函数返回时提供的。但是在异步 I/O 中,我们要使用 aio_return 函数。这个函数的原型如下:
__ssize_t aio_return (struct aiocb *__aiocbp)
只有在 aio_error 调用确定请求已经完成(可能成功,也可能发生了错误)之后,才会调用这个函数。aio_return 的返回值就等价于同步情况中 read 或 write 系统调用的返回值(所传输的字节数,如果发生错误,返回值就为 -1)。
1.1.6、 aio_suspend
我们可以使用 aio_suspend 函数来挂起(或阻塞)调用进程,直到异步请求完成为止,此时会产生一个信号,或者发生其他超时操作。调用者提供了一个 aiocb 引用列表,其中任何一个完成都会导致 aio_suspend 返回。 aio_suspend 的函数原型如下:
int aio_suspend (__const struct aiocb *__const __list[], int __nent,
__const struct timespec *__restrict __timeout)
aio_suspend 的使用非常简单。我们要提供一个 aiocb 引用列表。如果任何一个完成了,这个调用就会返回 0。否则就会返回 -1,说明发生了错误。
使用aio_suspend 函数阻塞异步I/O:
代码
/* Clear the list. */
bzero( ( char * )cblist, sizeof (cblist) );
/* Load one or more references into the list */
cblist[ 0 ] = & my_aiocb;
ret = aio_read( & my_aiocb );
ret = aio_suspend( cblist, MAX_LIST, NULL );
注意,aio_suspend 的第二个参数是 cblist 中元素的个数,而不是 aiocb 引用的个数。cblist 中任何 NULL 元素都会被 aio_suspend 忽略。如果为 aio_suspend 提供了超时,而超时情况的确发生了,那么它就会返回 -1,errno 中会包含 EAGAIN。
1.1.7、lio_listio
最后,AIO 提供了一种方法使用 lio_listio API 函数同时发起多个传输。这个函数非常重要,因为这意味着我们可以在一个系统调用(一次内核上下文切换)中启动大量的 I/O 操作。从性能的角度来看,这非常重要,因此值得我们花点时间探索一下。lio_listio API 函数的原型如下:
int lio_listio (int __mode,
struct aiocb *__const __list[__restrict_arr],
int __nent, struct sigevent *__restrict __sig)
使用 lio_listio 函数发起一系列请求:
代码
struct aiocb * list[MAX_LIST];
...
/* Prepare the first aiocb */
aiocb1.aio_fildes = fd;
aiocb1.aio_buf = malloc( BUFSIZE + 1 );
aiocb1.aio_nbytes = BUFSIZE;
aiocb1.aio_offset = next_offset;
aiocb1.aio_lio_opcode = LIO_READ;
...
bzero( ( char * )list, sizeof (list) );
list[ 0 ] = & aiocb1;
list[ 1 ] = & aiocb2;
ret = lio_listio( LIO_WAIT, list, MAX_LIST, NULL );
对于读操作来说,aio_lio_opcode 域的值为 LIO_READ。对于写操作来说,我们要使用 LIO_WRITE,不过 LIO_NOP 对于不执行操作来说也是有效的。
1.2、AIO通知
Linux,可以通过信号和函数回调来实现异步函数的通知机制(这里不再介绍,详细见参考文献;另外,关于AIO的实例,可以见InnoDB的源码,这里就不给例子了)。
2、Windows的异步I/O
当线程向设备发起一个I/O异步I/O请求后,这个I/O请求传递到设备驱动程序,后者在完成I/O后通知线程。所以,线程不用等待I/O完成而挂起,可以继续做其它的事情(当然,最终它会在某个点等待I/O完成,比如,当它必须需要数据时)——这是异步I/O的精髓所在。
2.1、核心数据结构与API
2.1.1、OVERLAPPED结构
代码
DWORD Internal; // [out] Error code
DWORD InternalHigh; // [out] Number of bytes transferred
DWORD Offset; // [in] Low 32-bit file offset
DWORD OffsetHigh; // [in] High 32-bit file offset
HANDLE hEvent; // [in] Event handle or data
} OVERLAPPED, * LPOVERLAPPED;
Offset与OffsetHight
这两个成员构成64位的偏移量,表示访问进行I/O的物理位置。
2.1.2、API
代码
HANDLE hFile,
PVOID pvBuffer,
DWORD nNumBytesToRead,
PDWORD pdwNumBytes,
OVERLAPPED * pOverlapped);
BOOL WriteFile(
HANDLE hFile,
CONST VOID * pvBuffer,
DWORD nNumBytesToWrite,
PDWORD pdwNumBytes,
OVERLAPPED * pOverlapped);
这两个函数调用时,会检查hFile参数标识的设备有没有设置FILE_FLAG_OVERLAPPED。如果设置了该标识,就进行异步I/O。
2.2、接收I/O请求完成通知
相对于Linux的AIO,Windows提供了4种不同的方法来接收I/O请求已经完成的通知:触发设备内核对象、触发事件内核对象、可提醒I/O和I/O完成端口(详细可以见参考文献,这里就不一一介绍了)。这里主要关注第2种和第4种方式,因为这两种方式是性能和可伸缩性最好的方式。
2.2.1、触发事件内核对象
代码
BYTE bReadBuffer[ 10 ];
OVERLAPPED oRead = { 0 };
oRead.Offset = 0 ;
oRead.hEvent = CreateEvent(...);
ReadFile(hFile, bReadBuffer, 10 , NULL, & oRead);
BYTE bWriteBuffer[ 10 ] = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 };
OVERLAPPED oWrite = { 0 };
oWrite.Offset = 10 ;
oWrite.hEvent = CreateEvent(...);
WriteFile(hFile, bWriteBuffer, _countof(bWriteBuffer), NULL, & oWrite);
...
HANDLE h[ 2 ];
h[ 0 ] = oRead.hEvent;
h[ 1 ] = oWrite.hEvent;
// 等待事件内核对象
DWORD dw = WaitForMultipleObjects( 2 , h, FALSE, INFINITE);
switch (dw – WAIT_OBJECT_0) {
case 0 : // Read completed
break ;
case 1 : // Write completed
break ;
}
这种方式允许一个线程发出I/O请求,另一个线程处理结果。能够很好的处理同时多个I/O请求。由于该方式能够同时处理多个I/O请求,而且也可以在多个线程之间进行负载均衡,所以,该方式是一种具有高性能和可伸缩性的I/O模型。一种具体编程模型可以如下(这也是我个人比较喜欢的模型):
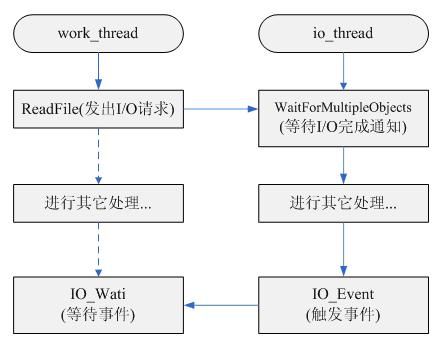
2.2.2、 I/O完成端口(I/O Completion Ports)
I/O完成端口和线程池是该I/O模型的基础。一般来说,应用程序在启动时,首先会通过CreateIoCompletionPort创建一个I/O完成端口,并将其与一个或者多个文件句柄关联起来;然后创建一个线程池,线程池是线程为一个死循环,在循环中调用GetQueuedCompletionStatus将线程阻塞,等待与完成端口关联的某个文件句柄上的I/O请求完成。
当操作系统内核完成I/O后,将线程池中的某个线程唤醒,使其从GetQueuedCompletionStatus返回,然后,该线程就可以针对读取的数据进各种处理。然后,又阻塞在GetQueuedCompletionStatus处。
代码
HANDLE FileHandle,
HANDLE ExistingCompletionPort,
ULONG_PTR CompletionKey,
DWORD NumberOfConcurrentThreads
);
BOOL GetQueuedCompletionStatus(
HANDLE CompletionPort,
LPDWORD lpNumberOfBytes,
PULONG_PTR lpCompletionKey,
LPOVERLAPPED * lpOverlapped,
DWORD dwMilliseconds
);
为了完整,写一个简单的使用I/O完成端口的例子:
代码
#include < Winsock2.h >
#include < windows.h >
#include < process.h >
#define DATA_BUFSIZE 4096
typedef struct
{
WSAOVERLAPPED overlap;
WSABUF DataBuf;
char buffer[DATA_BUFSIZE];
DWORD NumberOfBytesRecvd;
DWORD Flags;
}PER_IO_OPERATION_DATA, * LPPER_IO_OPERATION_DATA;
void err_sys(
char * err
)
{
fprintf(stderr, err);
WSACleanup();
exit( - 1 );
}
unsigned __stdcall WorkThread(
void * param
);
int main( int argc, char * argv[])
{
HANDLE CompletionPort;
WSADATA WsaData;
int clilen = sizeof (sockaddr_in);
sockaddr_in seraddr,cliaddr;
SOCKET listenfd, connfd;
int opt = 1 ;
SYSTEM_INFO systeminfo;
unsigned i;
int ret;
LPPER_IO_OPERATION_DATA lpPerIOData = NULL;
HANDLE hWorkThread;
unsigned threadID;
if (WSAStartup ( 0x0101 , & WsaData) == SOCKET_ERROR)
err_sys( " WSAStartup Failed\n " );
CompletionPort = CreateIoCompletionPort(INVALID_HANDLE_VALUE, NULL, 0 , 0 );
if (CompletionPort == NULL)
err_sys( " create port error!\n " );
seraddr.sin_family = AF_INET;
seraddr.sin_addr.s_addr = INADDR_ANY;
seraddr.sin_port = htons( 9877 );
listenfd = WSASocket(AF_INET, SOCK_STREAM, 0 , NULL, 0 , WSA_FLAG_OVERLAPPED);
if (listenfd == INVALID_SOCKET)
err_sys( " socket error!\n " );
if (setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, ( char * ) & opt, sizeof (opt)) < 0 )
err_sys( " setsockopt error!\n " );
if (bind(listenfd, (SOCKADDR * ) & seraddr, sizeof (seraddr)) == SOCKET_ERROR)
err_sys( " bind error\n " );
if (listen(listenfd, 5 ) == SOCKET_ERROR)
err_sys( " listen error!\n " );
printf( " server is listening...\n " );
if (CreateIoCompletionPort((HANDLE)listenfd, CompletionPort, (DWORD)listenfd, 0 ) == NULL)
err_sys( " associate lisenfd error!\n " );
GetSystemInfo( & systeminfo);
// 创建工作线程
for (i = 0 ; i < systeminfo.dwNumberOfProcessors; i ++ )
{
hWorkThread = (HANDLE)_beginthreadex(NULL, 0 , & WorkThread, CompletionPort, 0 , & threadID);
CloseHandle(hWorkThread);
}
for (;;)
{
if ((connfd = accept(listenfd, ( struct sockaddr * ) & cliaddr, & clilen)) == SOCKET_ERROR )
{
int code = WSAGetLastError();
printf( " accept error!\n " );
continue ;
}
// 将连接句柄关联到I/O完成端口
if (CreateIoCompletionPort((HANDLE)connfd, CompletionPort, (DWORD)connfd, 0 ) == NULL)
{
printf( " associate connfd error!\n " );
closesocket(connfd);
continue ;
}
lpPerIOData = (LPPER_IO_OPERATION_DATA)malloc( sizeof (PER_IO_OPERATION_DATA));
ZeroMemory(lpPerIOData, sizeof (PER_IO_OPERATION_DATA));
lpPerIOData -> DataBuf.len = DATA_BUFSIZE;
lpPerIOData -> DataBuf.buf = lpPerIOData -> buffer;
ret = WSARecv(connfd, & lpPerIOData -> DataBuf, 1 , & lpPerIOData -> NumberOfBytesRecvd, \
& lpPerIOData -> Flags, & lpPerIOData -> overlap, NULL);
if (ret == SOCKET_ERROR)
{
ret = WSAGetLastError();
if (ret != WSA_IO_PENDING)
{
printf( " WSARecv error!\n " );
closesocket(connfd);
}
}
}
free(lpPerIOData);
CloseHandle(CompletionPort);
closesocket(listenfd);
WSACleanup();
return 0 ;
}
// 工作线程
unsigned __stdcall WorkThread( void * param)
{
int ret;
DWORD BytesTransferred;
SOCKET connfd;
LPPER_IO_OPERATION_DATA lpPerIOData = NULL;
HANDLE cport = (HANDLE) param;
printf( " In work thread...\n " );
for (;;)
{
// 等待I/O完成通知
ret = GetQueuedCompletionStatus(cport, & BytesTransferred, (LPDWORD) & connfd,\
(LPOVERLAPPED * ) & lpPerIOData, INFINITE);
if (ret == 0 || BytesTransferred == 0 )
{
// close connection
closesocket(connfd);
}
else
{
printf( " recv %d bytes!\n " , BytesTransferred);
ret = send(connfd, lpPerIOData -> buffer, BytesTransferred, 0 );
if (ret == SOCKET_ERROR)
{
printf( " send error!\n " );
closesocket(connfd);
continue ;
}
else
printf( " send %d bytes!\n " , ret);
ZeroMemory( & lpPerIOData -> overlap, sizeof (OVERLAPPED));
ret = WSARecv(connfd, & lpPerIOData -> DataBuf, 1 , & lpPerIOData -> NumberOfBytesRecvd,\
& lpPerIOData -> Flags, & lpPerIOData -> overlap, NULL);
if (ret == SOCKET_ERROR)
{
ret = WSAGetLastError();
if (ret != WSA_IO_PENDING)
{
printf( " WSARecv error!\n " );
closesocket(connfd);
}
}
}
}
_endthreadex( 0 );
return 0 ;
}
3、epoll
3.1、poll(select)的限制
Poll函数起源于SVR3,最初局限于流设备,SVR4取消了这种限制。总是来说,poll比select要高效一些,但是,它有可移植性问题,例如,windows就只支持select。
一个poll的简单例子:
代码
#include < unistd.h >
#include < sys / poll.h >
#define TIMEOUT 5 /* poll timeout, in seconds */
int main ( void )
{
struct pollfd fds[ 2 ];
int ret;
/* watch stdin for input */
fds[ 0 ].fd = STDIN_FILENO;
fds[ 0 ].events = POLLIN;
/* watch stdout for ability to write (almost always true) */
fds[ 1 ].fd = STDOUT_FILENO;
fds[ 1 ].events = POLLOUT;
/* All set, block! */
ret = poll (fds, 2 , TIMEOUT * 1000 );
if (ret == - 1 ) {
perror ( " poll " );
return 1 ;
}
if ( ! ret) {
printf ( " %d seconds elapsed.\n " , TIMEOUT);
return 0 ;
}
if (fds[ 0 ].revents & POLLIN)
printf ( " stdin is readable\n " );
if (fds[ 1 ].revents & POLLOUT)
printf ( " stdout is writable\n " );
return 0 ;
}
select模型与此类例。内核必须遍历所有监视的描述符,而应用程序也必须遍历所有描述符,检查哪些描述符已经准备好。当描述符成百上千时,会变得非常低效——这是select(poll)模型低效的根源所在。考虑这些情况,2.6以后的内核都引进了epoll模型。
3.2、核心数据结构与接口
Epoll模型由3个函数构成,epoll_create、epoll_ctl和epoll_wait。
3.2.1创建epoll实例(Creating a New Epoll Instance)
epoll环境通过epoll_create函数创建:
#include
int epoll_create (int size)
调用成功则返回与实例关联的文件描述符,该文件描述符与真实的文件没有任何关系,仅作为接下来调用的函数的句柄。size是给内核的一个提示,告诉内核将要监视的文件描述符的数量,它不是最大值;但是,传递合适的值能够提高系统性能。发生错误时,返回-1。
例子:
epfd = epoll_create ( 100 ); /* plan to watch ~100 fds */
if (epfd < 0 )
perror ( " epoll_create " );
3.2.2、控制epoll(Controlling Epoll)
通过epoll_ctl,可以加入文件描述符到epoll环境或从epoll环境移除文件描述符。
代码
int epoll_ctl ( int epfd,
int op,
int fd,
struct epoll_event * event );
struct epoll_event {
_ _u32 events; /* events */
union {
void * ptr;
int fd;
_ _u32 u32;
_ _u64 u64;
} data;
};
epfd为epoll_create返回的描述符。op表示对描述符fd采取的操作,取值如下:
EPOLL_CTL_ADD
Add a monitor on the file associated with the file descriptor fd to the epoll instance associated with epfd, per the events defined in event.
EPOLL_CTL_DEL
Remove a monitor on the file associated with the file descriptor fd from the epollinstance associated with epfd.
EPOLL_CTL_MOD
Modify an existing monitor of fd with the updated events specified by event.
epoll_event结构中的events字段,表示对该文件描述符所关注的事件,它的取值如下:
EPOLLET
Enables edge-triggered behavior for the monitor of the file .The default behavior is level-
triggered.
EPOLLHUP
A hangup occurred on the file. This event is always monitored, even if it’s not specified.
EPOLLIN
The file is available to be read from without blocking.
EPOLLONESHOT
After an event is generated and read, the file is automatically no longer monitored.A new event mask must be specified via EPOLL_CTL_MOD to reenable the watch.
EPOLLOUT
The file is available to be written to without blocking.
EPOLLPRI
There is urgent out-of-band data available to read.
而epoll_event结构中的fd是epoll高效的根源所在,当描述符准备好。应用程序不用遍历所有描述符,而只用检查发生事件的描述符。
将一个描述符加入epoll环境:
代码
int ret;
event .data.fd = fd; /* return the fd to us later */
event .events = EPOLLIN | EPOLLOUT;
ret = epoll_ctl (epfd, EPOLL_CTL_ADD, fd, & event );
if (ret)
perror ( " epoll_ctl " );
3.2.3、等待事件(Waiting for Events with Epoll)
#include
int epoll_wait (int epfd,
struct epoll_event *events,
int maxevents,
int timeout);
等待事件的产生,类似于select()调用。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有 说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
一个简单示例:
代码
struct epoll_event * events;
int nr_events, i, epfd;
events = malloc ( sizeof ( struct epoll_event) * MAX_EVENTS);
if ( ! events) {
perror ( " malloc " );
return 1 ;
}
nr_events = epoll_wait (epfd, events, MAX_EVENTS, - 1 );
if (nr_events < 0 ) {
perror ( " epoll_wait " );
free (events);
return 1 ;
}
// 只需要检查发生事件的文件描述符,而不需要遍历所有描述符
for (i = 0 ; i < nr_events; i ++ ) {
printf ( " event=%ld on fd=%d\n " ,
events[i].events,
events[i].data.fd);
/*
* We now can, per events[i].events, operate on
* events[i].data.fd without blocking.
*/
}
free (events);
3.2.4、epoll的典型用法
代码
for (;;) {
nfds = epoll_wait(kdpfd, events, maxevents, - 1 );
for (n = 0 ; n < nfds; ++ n) {
if (events[n].data.fd == listener) {
// 新的连接
client = accept(listener, ( struct sockaddr * ) & local,
& addrlen);
if (client < 0 ){
perror( " accept " );
continue ;
}
setnonblocking(client);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = client;
// 设置好event之后,将这个新的event通过epoll_ctl加入到epoll的监听队列里面
if (epoll_ctl(kdpfd, EPOLL_CTL_ADD, client, & ev) < 0 ) {
fprintf(stderr, " epoll set insertion error: fd=%d0,
client);
return - 1 ;
}
}
else
do_use_fd(events[n].data.fd);
}
}
3.3、综合示例
代码
#include " echo.h "
#include < sys / epoll.h >
#include < fcntl.h >
#define EVENT_ARR_SIZE 20
#define EPOLL_SIZE 20
void setnonblocking(
int sockfd
);
int
main( int argc, char ** argv)
{
int i, listenfd, connfd, sockfd, epfd;
ssize_t n;
char buf[MAXLINE];
socklen_t clilen;
struct sockaddr_in cliaddr, servaddr;
struct epoll_event ev, evs[EVENT_ARR_SIZE];
int nfds;
if ((listenfd = socket(AF_INET, SOCK_STREAM, 0 )) < 0 )
err_sys( " create socket error!\n " );
setnonblocking(listenfd);
epfd = epoll_create(EPOLL_SIZE);
ev.data.fd = listenfd;
ev.events = EPOLLIN | EPOLLET;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, listenfd, & ev) < 0 )
err_sys( " epoll_ctl listenfd error!\n " );
bzero( & servaddr, sizeof (servaddr));
servaddr.sin_family = AF_INET;
// servaddr.sin_addr.s_addr = INADDR_ANY;
servaddr.sin_addr.s_addr = inet_addr( " 211.67.28.128 " );
servaddr.sin_port = htons(SERV_PORT);
if (bind(listenfd, ( struct sockaddr * ) & servaddr, sizeof (servaddr)) < 0 )
err_sys( " bind error!\n " );
if (listen(listenfd, LISTENQ) < 0 )
err_sys( " listen error!\n " );
printf( " server is listening....\n " );
for ( ; ; ) {
if ((nfds = epoll_wait(epfd, evs, EVENT_ARR_SIZE, - 1 )) < 0 )
err_sys( " epoll_wait error!\n " );
for (i = 0 ; i < nfds; i ++ )
{
if (evs[i].data.fd == listenfd)
{
clilen = sizeof (cliaddr);
connfd = accept(listenfd, ( struct sockaddr * ) & cliaddr, & clilen);
if (connfd < 0 )
continue ;
setnonblocking(connfd);
ev.data.fd = connfd;
ev.events = EPOLLIN | EPOLLET;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, & ev) < 0 )
err_sys( " epoll_ctl connfd error!\n " );
}
else if (evs[i].events & EPOLLIN)
{
sockfd = evs[i].data.fd;
if (sockfd < 0 )
continue ;
if ( (n = read(sockfd, buf, MAXLINE)) == 0 ) {
epoll_ctl(epfd, EPOLL_CTL_DEL, sockfd, & ev);
close(sockfd);
evs[i].data.fd = - 1 ;
}
else if (n < 0 )
err_sys( " read socket error!\n " );
else
{
printf( " write %d bytes\n " , n);
write(sockfd, buf, n);
}
}
else
printf( " other event!\n " );
}
}
return 0 ;
}
void setnonblocking(
int sockfd
)
{
int flag;
flag = fcntl(sockfd, F_GETFL);
if (flag < 0 )
err_sys( " fcnt(F_GETFL) error!\n " );
flag |= O_NONBLOCK;
if (fcntl(sockfd, F_SETFL, flag) < 0 )
err_sys( " fcon(F_SETFL) error!\n " );
}
// echo.h
#include < sys / types.h >
#include < sys / socket.h >
#include < netinet / in .h >
#include < arpa / inet.h >
#include < unistd.h >
#include < stdlib.h >
#include < string .h >
#include < stdio.h >
#include < errno.h >
#define SERV_PORT 9877
#define MAXLINE 4096
#define LISTENQ 5
void
err_sys( const char * fmt, ...);
ssize_t
readn( int fd, void * vptr, size_t n);
3.4、Edge-Triggered 与Level-Triggered Events
epoll有2种工作方式:LT和ET:
LT(level triggered)是缺省的工作方式,并且同时支持block和no-block socket。在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作。如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点。传统的select/poll都是这种模型的代表。
ET (edge-triggered)是高速工作方式,只支持no-block socket。在这种模式下,当描述符从未就绪变为就绪时,内核通过epoll告诉你。然后它会假设你知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知,直到你做了某些操作导致那个文件描述符不再为就绪状态了(比如,你在发送,接收或者接收请求,或者发送接收的数据少于一定量时导致了一个EWOULDBLOCK 错误)。但是请注意,如果一直不对这个fd作IO操作(从而导致它再次变成未就绪),内核不会发送更多的通知(only once),不过在TCP协议中,ET模式的加速效用仍需要更多的benchmark确认。
小结
如果考虑到socket编程,I/O完成端口与Linux的epoll模型(见下一节介绍)非常相似,CreateIoCompletionPort创建的I/O完成端口,与epoll_create创建的文件描述符的功能一样,当服务器接收到新的连接(connfd),可以继续调用CreateIoCompletionPort将其(connfd)与I/O完成端口关联起来。而GetQueuedCompletionStatus功能而相当于epoll模型的epoll_wait,阻塞线程,等待I/O发生。但是,I/O完成端口与epoll有一个显著的区别,就是当线程从GetQueuedCompletionStatus返回,Windows内核已经将实际的I/O完成;而当线程从epoll_wait返回,Linux内核只是告诉我们有数据到来,但并没有进行实际的读取,所以,需要我们自己调用read读取实际的数据。实际上,这与AIO更相似。
主要参考:
《Unix网络编程》
《Windows via C/C++》
《Windows网络编程》
http://www.ibm.com/developerworks/cn/linux/l-async/