python爬虫学习笔记
爬虫基础
目录
- 爬虫基础
- day01
- 爬虫基础知识
- 模块一:
- 模块二
- 模块三 循环抓取页面
- day02
- 模块四 抓取豆瓣排行榜信息
- 模块五 爬取百度翻译
- 模块六 人人网实现代码登录
- 代理 IP 的原理
- day03
- 模块七 分析拉钩网的 json 格式数据
- 正则表达式
- 模块八
- day04
- xpath
- bs4
- day05
- 多线程
- day06
- 反爬思路分析
- 额外添加
- 小结
day01
爬虫学习来源:(逆风学习网:买的 2019年3月份黑马爬虫阶段课程,很遗憾没有文档。。。)(获取方法:自行百度)
先给出爬虫的总目录:

爬虫基础知识





在自己电脑上设置爬虫的时候,需要注意几个点:
- 首先确认电脑是安装了 python2 和 python3 的吗?如果两个都安装了,而且你还想用 pip 来自动安装库,请使用 链接

- 安装的库需要看自己是否需要了,现在先安装了 repuests库,注意本文章现在只用了 python3 !!! 如果更新了库,使用的软件还是 pycharm,请更新 pycharm 的 python3 的信息,只需要在下图刷新一下就行了。

模块一:

尝试爬取网站信息:
如果结果出现乱码,注意设置编码为 UTF-8
代码:
from urllib import request
base_url = 'http://www.baidu.com'
req = request.Request(base_url)
response = request.urlopen(req)
html = response.read()
print(html)
with open('baidu.html ','wb') as f:
f.write(html)
f.close()
爬取结果:

模块二

这个是各种请求对象的使用:
代码:
import requests
if __name__ == '__main__':
url = 'http://www.baidu.com'
response = requests.get(url)
data = response.content
data_str = data.decode('utf-8')
#状态码
code = response.status_code
print(code)
print(type(code))
#请求头
requests_headers = response.request.headers
print(requests_headers)
#响应头
response_headers = response.headers
print(response_headers)
#请求 cookies——RequestsCookieJar 对象 有时是 _cookies
request_cookies = response.request._cookies
print(request_cookies)
#响应的 cookie
response_cookies = response.cookies
print(response_cookies)
#保存文件
# with open('02baidu.html','w') as f:
# f.write(data_str)
print('结束')
结果:

模块三 循环抓取页面
import requests
class TieBaSpider(object):
def __init__(self):
self.tiebaName = input('输入贴吧名字:')
self.startPage = int(input('开始页数:'))
self.endPage = int(input('结束页数:'))
self.base_url = 'http://tieba.baidu.com/f'
self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24'}
# 1.发请求
def send_request(self,tieba_params):
response = requests.get(url=self.base_url, headers=self.headers, params=tieba_params)
data = response.content
print(555)
return data
# 2.保存数据
def write_file(self, data, page):
file_pat = 'TieBa/' + str(page) + '.html'
print('正在抓取{}页...'.format(page))
with open(file_pat, 'wb') as f:
print('666')
f.write(data)
# 3.调度方法
def run(self):
for page in range(self.startPage, self.endPage + 1):
# 1.拼接参数
tieba_params = {
'kw': self.tiebaName,
'pn': (page - 1) * 50
}
# 2.发请求
data = self.send_request(tieba_params)
# 3.保存数据
self.write_file(data, page)
tool = TieBaSpider()
tool.run()
到这里就算是爬虫的基本应用了。



day02

模块四 抓取豆瓣排行榜信息
先分析网站:
很明显我们要获取的信息是放到数据库中的,我们需要去请求服务器的接口。在网页里面用到的技术是 ajax ,异步的 JavaScript 和 XML。
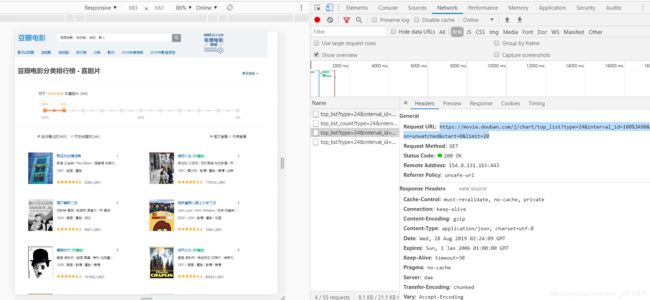
然后就去请求接口就行了。
模块五 爬取百度翻译
都是请求服务器的接口。
首先看到的是百度翻译的电脑端:

详细的分析前端代码就不分析了。
因为:

电脑端的接口需要的字段较多,需要在前端代码中分析出每个字段的意思,其中 sign 涉及的算法较多,这里就不贴出来了。然后在网上看到了这个:
Python破解百度翻译反爬机制:自制翻译器
(假破解)
然后根据视频的换位思考,就去考虑手机端的接口。
视频中的:

实际中的:

看来百度翻译已经更新了这种 “bug” 了,下面的内容就跳过了。。。
学习到:
python3 解析 json 格式的数据可以导入 json 包。
使用方式:
re = json.loads(data)['trans'][0]['result'][1]
模块六 人人网实现代码登录
import requests
# 多 user-agent 池子,账户一个人;浏览器
# 封帐号——多帐号——>多 cookies 池子
# 20账号
# 1. keaders={}
# 2. cookie={}
# 3. 代码模拟登录
# 1.html form(action='提交网址' method='请求方法') input select area
# 2.net_work —— >url-data--login 都是可以登录
#code 代码登录——cookies——>页面
def renren_login():
# 1.代码登录
# 1.1登录的网址 url
login_url = 'http://www.renren.com/PLogin.do'
# 1.2 登录的参数
login_data = {
'email':"",
'password':''
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24',
'Cookie':''
}
# 1.3 发送登录请求POST
#session 可以自动保存 cookies
session = requests.session()
login_response = requests.post(urll = login_url, data = login_data, headers=headers)
cookies_dice = requests.utils.dict_from_cookiejar(cookies)
#
#
profile_url = ''
data = session.get(profile_url, headers = headers).content.decode()
with open('03renren.html', 'w') as f:
f.write(data)
遇到有 ssl 不安全的问题、
解决方案:

将验证设置为 false。
代理 IP 的原理
是一种正向代理。反向代理是nginx那种。
代理分成三类:
- 透明
- 匿名:不知道真实IP
- 高匿


day03



数据提取方法:

主要使用 : $…book 这样的。

模块七 分析拉钩网的 json 格式数据
import jsonpath
import requests
import json
# 1.json_url
json_url = 'https://www.lagou.com/lbs/getAllCitySearchLabels.json'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24'}
# 2.发请求
response = requests.get(url = json_url,headers = headers)
data = response.content
print(data)
data_str = data.decode('utf-8') # 先解析成字符串
data_dict = json.loads(data_str) # 再解析成字典类型
print(data_dict)
# json()方法 必须返回的是 json 格式的数据
dice = response.json()
# 3.解析 jsonpath 接受的 dict/list
result_list = jsonpath.jsonpath(data_dict, '$..name' )
# 4.写入文件
print(result_list)
json.dump(result_list, open('02city.json', 'w', encoding='utf-8'))
结果:

正则表达式




模块八
爬取果壳页面下的

按照教程爬取结果:

然而教程得到的数据是20个。然后去翻前端代码,发现在第十几个的时候:

这玩意在前面是换行的,
但是其他都是不换行的:

很无奈很无奈。

代码:
import requests
import re
import json
class GuokrSpider(object):
def __init__(self):
self.base_url = 'https://www.guokr.com/ask/highlight/'
self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24'}
# 1.发送请求
def send_request(self):
data = requests.get(self.base_url, headers = self.headers).content.decode('utf-8')
return data
# 2.解析数据
def analysis_data(self, data):
"""
< a
target = "_blank"
href = "https://www.guokr.com/question/669761/" > 印度人把男人的生殖器叫林伽,把女人的生殖器叫瑜尼,林伽和瑜尼的交合,便是瑜伽。这是真还是假的 < / a >
"""
# 下面这个太广了,把一部分没用的也拉了进来。
# pattern = re.compile('(.*)')
pattern = re.compile('(.*)
')
result_list = pattern.findall(data)
print(result_list)
return result_list
# 3.保存数据
def write_file(self, data):
# with open('06guokr.html', 'w', encoding='utf-8') as f:
# f.write(data)
json.dump(data, open('06guokr.json', 'w', encoding='utf-8'))
# 4.调度
def run(self):
data = self.send_request()
analysis_data = self.analysis_data(data)
self.write_file(analysis_data)
GuokrSpider().run()
day04
xpath
xpath的学习可以看 https://www.w3school.com.cn/xpath/xpath_syntax.asp。




下面这个是进行xpath的简单运用(需要安装lxml)
from lxml import etree
html_str = """
"""
data = etree.HTML(html_str.encode())
print(data)
result_list = data.xpath('//li')
print(result_list)
result_list = data.xpath('//li[3]')
print(result_list)
result_list = data.xpath('//a[@href="link4.html"]/text()') # 用 text() 取 文本
print(result_list)
result_list = data.xpath('//li[3]/@class') # 用 @class 取属性
print(result_list)
result_list = data.xpath('//li[contains(@class,"item")]') # 用 contains 进行模糊查询
print(result_list)
result_list = data.xpath('//a[@href="link4.html"]')
print(result_list)
result_list = etree.tostring(data).decode()
print(result_list)
运行结果:


bs4
bs4的使用(比xpath简单)


能使用 javascript 的选择器,如果学习过前端,使用这个是最简单的了。
实例代码:
from bs4 import BeautifulSoup
import re
html_str = """
The Dormous's story
The Dormouse's story
Once upon a time there were three little sisters;
Elsie
Lacie
Tillie
...
"""
# 1.转解析类型
soup = BeautifulSoup(html_str, 'lxml')
# # 2.格式化输出
# result = soup.prettify()
# print(result)
# 2.解析数据
# 2.1 fin——获取符合条件 第一个
result = soup.find(name='a')
print(result)
result = soup.find(attrs={
"id":"link2"
})
print(result)
pattern = re.compile('^ht')
result = soup.find(pattern)
print(result)
result = soup.find(text="...")
print(result)
# 2.2 find_all ——list
# result = soup.findall('a')
# print(result)
# 2.3 select 选择器
# 类型有:标签选择器,类选择器,ID选择器,层级选择器,组选择器,属性选择器
result = soup.select('a')
result = soup.select('.title')
result = soup.select('#link3')
result = soup.select('head title')
result = soup.select('#link3,#link1')
result = soup.select('p[name="dromouse"]')
result = soup.select('#link3')
print(result)
# 标签包裹的内容
# result = result[0].get_text()
# print(result)
# 标签的属性(这个和上面那个不能一起用的)
result = result[0].get('href')
print(result)
保存数据采用下面的字典。

一个爬取实例:


day05
多线程


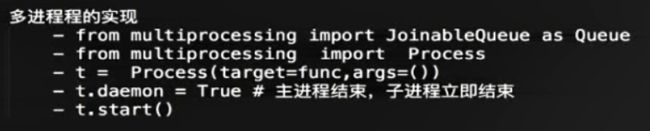


这章先跳了。。。
day06


反爬思路分析



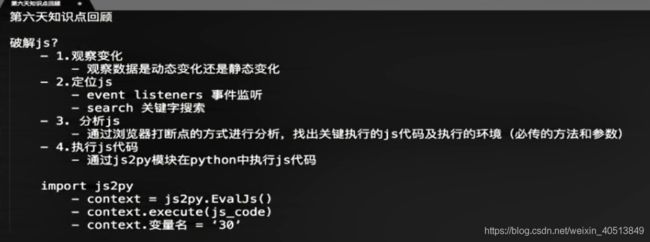
破解 js 的步骤:
不需要自己找,太费时间了,采用下面的:

可以在python里面运行 js 代码来解决这个问题。

可以用这个去找百度翻译的 sign 值,前面有提到过这个话题。








额外添加
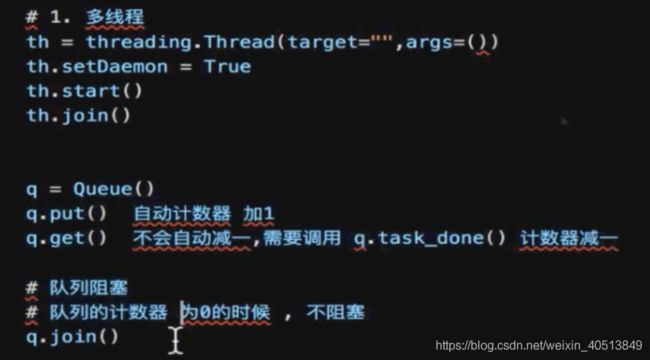
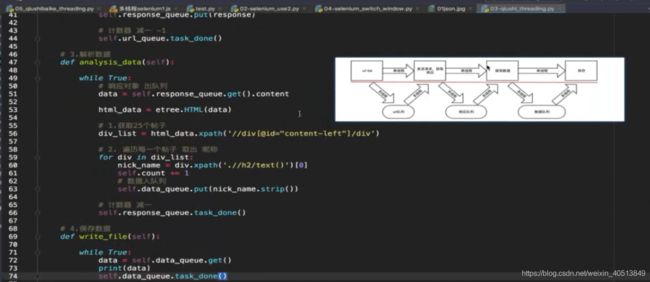
- 可以考录设置成为多线程

用个bitmap来存访问过的数据即可。然后询问是否拿过即可。




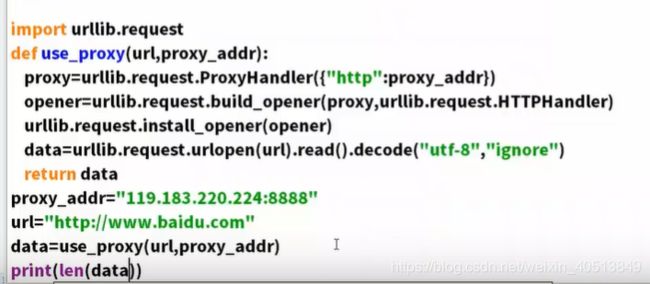
2. 使用代理服务器
小结
到这里就把爬虫的基础基本全部了解了。
后面还有8个day,一个是关于 mongodb 的使用,这个会在后面重新开一个文章。还有好几个day是关于 scrapy 框架的,这个就先不学习了,等以后决定深入学习爬虫再学习。
总结:
爬虫用起来是挺方便的,知识点主要是与网络相关的。反爬点很多,但是反反爬也不是太困难,毕竟只要花时间和心思在网站上,总能解决问题的。通过这个爬虫的学习,我更加的深入学习了网页的前端,对浏览器加载网页的数据和浏览器请求网站的数据也有了更加深入的理解吧。