人工智能,从PyTorch到PyTorch Lightning简要介绍

这篇文章回答了有关使用PyTorch时为什么需要Lightning的最常见问题。
PyTorch非常易于使用,可以构建复杂的AI模型。但是一旦研究变得复杂,并且将诸如多GPU训练,16位精度和TPU训练之类的东西混在一起,用户很可能会引入错误。
PyTorch Lightning完全解决了这个问题。Lightning会构建您的PyTorch代码,以便可以抽象出训练的细节。这使得AI研究可扩展且可快速迭代。
PyTorch Lightning适用于谁?

PyTorch Lightning是为从事AI研究的专业研究人员和博士生创建的。
Lightning来自我的博士学位。人工智能研究的纽约大学CILVR和Facebook的AI研究。结果,该框架被设计为具有极强的可扩展性,同时又使最先进的AI研究技术(例如TPU训练)变得微不足道。
现在,核心贡献者都在使用Lightning推动AI的发展,并继续添加新的炫酷功能。
但是,简单的界面使专业的生产团队和新手可以使用Pytorch和PyTorch Lightning社区开发的最新技术。
Lightning拥有超过96名贡献者,由8名研究科学家,博士研究生和专业深度学习工程师组成的核心团队。
![]()
经过严格测试,
并彻底记录。

大纲
本教程将引导您构建一个简单的MNIST分类器,并排显示PyTorch和PyTorch Lightning代码。虽然Lightning可以构建任何任意复杂的系统,使用MNIST来说明如何将PyTorch代码重构为PyTorch Lightning。
典型的AI研究项目
在研究项目中,我们通常希望确定以下关键组成部分:数据、损失、优化器。
模型
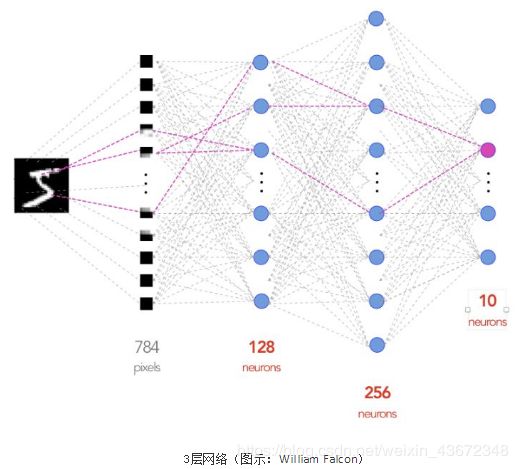
设计一个三层全连接神经网络,该网络以28x28的图像作为输入,并输出10个可能标签上的概率分布。
首先,在PyTorch中定义模型

该模型定义了计算图,以将MNIST图像作为输入,并将其转换为10至9位数字的概率分布。
要将模型转换为PyTorch Lightning,只需将pl.LightningModule替换为nn.Module

新的PyTorch Lightning类与PyTorch完全相同,只不过LightningModule提供了用于研究代码的结构。

Lightning为PyTorch代码提供了结构
看到?两者的代码完全相同!
这意味着可以像使用PyTorch模块一样完全使用LightningModule,例如预测

或将其用作预训练模型

数据:
在本教程中,使用MNIST。

生成MNIST的三个部分,即训练,验证和测试部分。同样,PyTorch中的代码与Lightning中的代码相同。数据集被添加到数据加载器中,该数据加载器处理数据集的加载,改组和批处理。
简而言之,数据准备包括四个步骤:
1)、下载图片;
2)、图像变换(这些是高度主观的);
3)、生成训练,验证和测试数据集拆分;
4)、将每个数据集拆分包装在DataLoader中。

同样,除了将PyTorch代码组织为4个函数之外,代码完全相同:
prepare_data
此功能处理下载和任何数据处理。此功能可确保当您使用多个GPU时,不会下载多个数据集或对数据进行多重操作。这是因为每个GPU将执行相同的PyTorch,从而导致重复。所有在Lightning的代码可以确保关键部件是从所谓的仅一个GPU。
train_dataloader,val_dataloader,test_dataloader
每一个都负责返回适当的数据拆分。Lightning以这种方式进行构造,因此非常清楚如何操作数据。如果曾经阅读用PyTorch编写的随机github代码,则几乎看不到如何操纵数据。Lightning甚至允许多个数据加载器进行测试或验证。
优化器
现在选择如何进行优化。将使用Adam而不是SGD,因为它在大多数DL研究中都是很好的默认设置。

同样,这两者完全相同,只是它被组织到配置优化器功能中。
Lightning极为可扩展。例如,如果想使用多个优化器(即GAN),则可以在此处返回两者。

还会注意到,在Lightning中,传入了self.parameters() 而不是模型,因为LightningModule是模型。
损失
对于n向分类,要计算交叉熵损失。交叉熵与将使用的NegativeLogLikelihood(log_softmax)相同。

再次……代码是完全一样的!
训练和验证循环
汇总了训练所需的所有关键要素:
1)、模型(3层NN);
2)、数据集(MNIST);
3)、优化器;
4)、损失;
现在,执行一个完整的训练例程,该例程执行以下操作:
迭代多个时期(一个时期是对数据集D的完整遍历)
在数学上:

在代码中:

每个时期以称为批处理b的小块迭代数据集。
在数学上:
![]()
在代码中:
![]()
执行向前通过。
在数学上:
![]()
代码:
![]()
计算损失。
在数学上:

在代码中:
![]()
执行向后传递以计算每个权重的所有梯度。
在数学上:
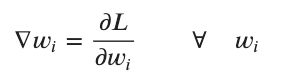
在代码中:
![]()
将渐变应用于每个权重。
在数学上:
![]()
在代码中:
![]()
在PyTorch和Lightning中,伪代码都看起来像这样。

但这是 Lightning不同的地方。在PyTorch中,自己编写了for循环,这意味着必须记住要以正确的顺序调用正确的东西-这为错误留下了很多空间。即使模型很简单,也不会像开始做更高级的事情那样,例如使用多个GPU,渐变裁剪,提早停止,检查点,TPU训练,16位精度等……代码复杂性将迅速爆炸。即使模型很简单,也不会一开始就做更高级的事情,这是PyTorch和Lightning的验证和训练循环。

这就是Lightning的美。它抽象化样板(不在盒子中的东西),但其他所有内容保持不变。这意味着您仍在编写PyTorch,除非您的代码结构良好。这增加了可读性,有助于再现性!
Lightning教练
训练师是抽象样板代码的方式。

同样,这是可能的,因为要做的就是将PyTorch代码组织到LightningModule中
PyTorch的完整训练循环
用PyTorch编写的完整MNIST示例如下:
import torchfrom torch
import nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader, random_split
from torch.nn import functional as F
from torchvision.datasets import MNIST
from torchvision import datasets, transforms
import os
# -----------------
# MODEL
# -----------------
class LightningMNISTClassifier(pl.LightningModule):
def __init__(self):
super(LightningMNISTClassifier, self).__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
def forward(self, x):
batch_size, channels, width, height = x.sizes()
# (b, 1, 28, 28) -> (b, 1*28*28)
x = x.view(batch_size, -1)
# layer 1
x = self.layer_1(x)
x = torch.relu(x)
# layer 2
x = self.layer_2(x)
x = torch.relu(x)
# layer 3
x = self.layer_3(x)
# probability distribution over labels
x = torch.log_softmax(x, dim=1)
return x
# ----------------# DATA# ----------------
transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform)
mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform)
# train (55,000 images), val split (5,000 images)
mnist_train, mnist_val = random_split(mnist_train, [55000, 5000])
mnist_test = MNIST(os.getcwd(), train=False, download=True)
# The dataloaders handle shuffling, batching, etc...
mnist_train = DataLoader(mnist_train, batch_size=64)
mnist_val = DataLoader(mnist_val, batch_size=64)
mnist_test = DataLoader(mnist_test, batch_size=64)
# ----------------
# OPTIMIZER
# ----------------
pytorch_model = MNISTClassifier()
optimizer = torch.optim.Adam(pytorch_model.parameters(), lr=1e-3)
# ----------------
# LOSS
# ----------------
def cross_entropy_loss(logits, labels):
return F.nll_loss(logits, labels)
# ----------------
# TRAINING LOOP
# ----------------
num_epochs = 1
for epoch in range(num_epochs):
# TRAINING LOOP
for train_batch in mnist_train:
x, y = train_batch
logits = pytorch_model(x)
loss = cross_entropy_loss(logits, y)
print('train loss: ', loss.item())
loss.backward()
optimizer.step()
optimizer.zero_grad()
# VALIDATION LOOP
with torch.no_grad():
val_loss = []
for val_batch in mnist_val:
x, y = val_batch
logits = pytorch_model(x)
val_loss.append(cross_entropy_loss(logits, y).item())
val_loss = torch.mean(torch.tensor(val_loss))
print('val_loss: ', val_loss.item())
Lightning中的完整训练循环
Lightning版本完全相同,除了:
核心成分由LightningModule组织
训练者/验证循环代码已由训练师抽象化
import torch
from torch import nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader, random_split
from torch.nn import functional as F
from torchvision.datasets import MNIST
from torchvision import datasets, transforms
import os
class LightningMNISTClassifier(pl.LightningModule):
def __init__(self):
super(LightningMNISTClassifier, self).__init__()
# mnist images are (1, 28, 28) (channels, width, height)
self.layer_1 = torch.nn.Linear(28 * 28, 128)
self.layer_2 = torch.nn.Linear(128, 256)
self.layer_3 = torch.nn.Linear(256, 10)
def forward(self, x):
batch_size, channels, width, height = x.size() # (b, 1, 28, 28) -> (b, 1*28*28) x = x.view(batch_size, -1) # layer 1 x = self.layer_1(x) x = torch.relu(x) # layer 2 x = self.layer_2(x) x = torch.relu(x) # layer 3 x = self.layer_3(x) # probability distribution over labels x = torch.log_softmax(x, dim=1) return x def cross_entropy_loss(self, logits, labels): return F.nll_loss(logits, labels) def training_step(self, train_batch, batch_idx): x, y = train_batch logits = self.forward(x) # we already defined forward and loss in the lightning module. We'll show the full code next loss = self.cross_entropy_loss(logits, y) logs = {'train_loss': loss} return {'loss': loss, 'log': logs} def validation_step(self, val_batch, batch_idx): x, y = val_batch logits = self.forward(x) loss = self.cross_entropy_loss(logits, y) return {'val_loss': loss} def validation_end(self, outputs): # outputs is an array with what you returned in validation_step for each batch # outputs = [{'loss': batch_0_loss}, {'loss': batch_1_loss}, ..., {'loss': batch_n_loss}] avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() tensorboard_logs = {'val_loss': avg_loss} return {'avg_val_loss': avg_loss, 'log': tensorboard_logs} def prepare_data(self): # prepare transforms standard to MNIST MNIST(os.getcwd(), train=True, download=True) MNIST(os.getcwd(), train=False, download=True) def train_dataloader(self): transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) mnist_train = MNIST(os.getcwd(), train=True, download=False, transform=transform) self.mnist_train, self.mnist_val = random_split(mnist_train, [55000, 5000]) mnist_train = DataLoader(self.mnist_train, batch_size=64) return mnist_train def val_dataloader(self): mnist_val = DataLoader(self.mnist_val, batch_size=64) return mnist_val def test_dataloader(self): transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) mnist_test = MNIST(os.getcwd(), train=False, download=False, transform=transform) mnist_test = DataLoader(mnist_test, batch_size=64) return mnist_test def configure_optimizers(self): # the lightningModule HAS the parameters (remember that we had the __init__ and forward method but we're just not showing it here) optimizer = torch.optim.Adam(self.parameters(), lr=1e-3) return optimizer # trainmodel = LightningMNISTClassifier()trainer = pl.Trainer() trainer.fit(model)
强调:指出一些关键点
如果没有Lightning,则可以将PyTorch代码分为任意部分。使用Lightning,这是结构化的。
除了在Lightning中进行结构化外,这两者的代码完全相同。(值得说两次大声笑)。
随着项目的复杂性增加,代码将不会因为Lightning提取其中的大部分内容。
保留了PyTorch的灵活性,因为可以完全控制训练中的关键点。例如,可以使用任意复杂的training_step,例如seq2seq
def training_step(self, batch, batch_idx):
x, y = batch
# define your own forward and loss calculation
hidden_states = self.encoder(x)
# even as complex as a seq-2-seq + attn model
# (this is just a toy, non-working example to illustrate)
start_token = ''
last_hidden = torch.zeros(...)
loss = 0
for step in range(max_seq_len):
attn_context = self.attention_nn(hidden_states, start_token)
pred = self.decoder(start_token, attn_context, last_hidden)
last_hidden = pred
pred = self.predict_nn(pred)
loss += self.loss(last_hidden, y[step])
#toy example as well
loss = loss / max_seq_len
return {'loss': loss}
5.在Lightning中,有很多免费赠品,例如病假的进度条

也得到了漂亮的体重总结

tensorboard日志(是的!什么也没有得到)

和免费的检查站,并尽早停止。
全部免费!
附加功能
但是Lightning以开箱即用的东西(例如TPU训练等)而闻名。
在Lightning中,可以在CPU,GPU,多个GPU或TPU上训练模型,而无需更改PyTorch代码的一行。
还可以进行16位精度训练。

使用Tensorboard的其他5种替代方法进行记录

使用Neptune.AI进行日志记录(鸣谢:Neptune.ai)
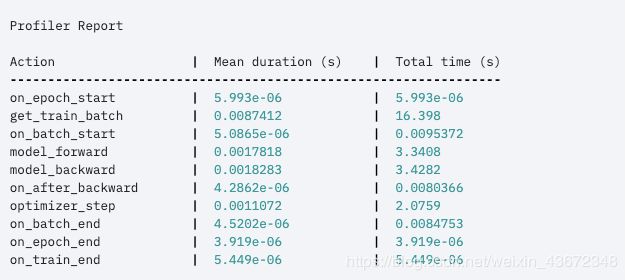
甚至有一个内置的探查器,可以告诉训练中瓶颈的位置。
![]()
将此标志设置为开将提供此输出
或更高级的输出(如果需要)。

还可以一次在多个GPU上进行训练而无需做任何工作(仍然必须提交SLURM作业)。

它支持大约40种其他功能,可以在文档中阅读这些功能。
带钩的可扩展性
可能想知道Lightning如何为做到这一点,又以某种方式做到这一点,以便完全掌控一切?与keras或其他高级框架不同,Lightning不会隐藏任何必要的细节。但是,如果确实需要自己修改训练的各个方面,那么有两个主要选择。首先是通过覆盖钩子的可扩展性。这是一个非详尽的清单:
1)、前传;
2)、向后传递;
3)、应用优化器;

进行分布式训练:

设置16位:

如何截断支柱:

需要配置的任何内容:
这些替代发生在LightningModule中。

回调的可扩展性
回调是希望在训练的各个部分执行的一段代码。在Lightning中,回调保留用于非必需的代码,例如日志记录或与研究代码无关的东西。这使研究代码保持超级干净和有条理。假设想在训练的各个部分打印或保存一些内容。这是回调的样子:

现在,将其传递给训练师,该代码将在任意时间被调用。
![]()
这种范例将研究代码组织在三个不同的存储库中:
1)、研究代码(LightningModule)(这是科学);
2)、工程代码(训练师);
3)、与研究无关的代码(回调);
如何开始
希望本指南向确切地介绍了如何入门。最简单的开始方法是运行带有MNIST示例的colab笔记本。或安装Lightning:

感谢您的阅读,如果有什么心得,请留言。