新建网站提升曝光率设置集合(边使用边更新)(包括:SEO优化,Robots设置,CDN加速,防盗链)
目前处于边学习边记录的状态,将自己建站中遇到的问题记录下来,以供大家参考,最终效果可以访问我的主页进行查看:alvincr.com
Table of Contents
1.1 SEO优化目的(搜索引擎优化)
1.2什么是robots.txt
1.3 设置Robots.txt注意事项
1.4 设置Robots.txt
1.5 设置Robots.txt注意事项
1.6查看是否被收录
1.7 手动提交网站
2 其它提升曝光方法
3 优化自己的服务器
CDN加速
防盗链
4.学习中遇到的名词
3.1 盗链
3.2 网站地图
3.3 爬取与反爬取策略
3.4 PPC,PPC推广
1.1 SEO优化目的(搜索引擎优化)
方法:设置robots.txt以自定义网页是否可以被抓取。
允许爬取的利弊:
优:通过做SEO,进行优化使网站排名靠前,这样只要搜索相关关键词就能找到自己的网站。
为查找引擎供给一个简洁明了的索引环境
制止某些文件被查找引擎索引,能够节约服务器带宽和网站拜访速度
疾速增加网站权重和拜访量;
劣:反向优点
1.2什么是robots.txt
robots.txt是搜索引擎爬行网页要查看的第一个文件,当搜索机器人访问一个站点时,它首先会检查根目录是否存在robots.txt,如果有就确定抓取范围,没有就按链接顺序抓取。
为何需要用robots.txt这个文件来告诉搜索机器人不要爬行我们的部分网页,比如:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等等。说到底了,这些页面或文件被搜索引擎收录了,用户也看不了,多数需要口令才能进入或是数据文件。既然这样,又让搜索机器人爬行的话,就浪费了服务器资源,增加了服务器的压力,因此我们可以用robots.txt告诉机器人集中注意力去收录我们的文章页面,增强用户体验。
1.3 设置Robots.txt注意事项
1、作为搜索引擎最先访问的目录,过长的robots文件也会影响蜘蛛的爬取速度,所以对于禁止搜索引擎的网页,可以适度的去使用noffollow标记,使其不对该网站传递权重。
2、在robots设置当中关于Disallow当中/和//的区别。举例:Disallow; /a 与Disallow: /a/的区别,很多站长都见过这样的问题,为什么有的协议后加斜杠,有的不加斜杠呢?笔者今天要说的是:如果不加斜杠,屏蔽的是以a字母开头的所有目录和页面,而后者代表的是屏蔽当前目录的所有页面和子目录的抓取。
通常来讲,我们往往选择后者更多一些,因为定义范围越大,容易造成“误杀”。
3、对于Disallow和Allow的设置是有先后顺序之分的,搜索引擎会根据第一个匹配成功的Allow与Disallow来确定首先访问那个url地址。
4、已经删除的目录屏蔽不建议使用Robots.txt文件屏蔽。很多站长往往删除一些目录后,怕出现404问题,而进行了屏蔽,禁止搜索引擎再抓取这样的链接。事实上,这样做真的好吗?即使你屏蔽掉了,如果之前的目录存在问题,那么没有被蜘蛛从库中剔除,同样会影响到网站。
济南文汇传媒作为公司建议,将对应的主要错误页面整理出来,做死链接提交,以及自定义404页面的处理,彻底的解决问题,而不是逃避问题。
5、在robots设置当中“*”和“$”的设置,其中”$”匹配行结束符。”*”匹配0或多个任意字符。
1.4 设置Robots.txt
首先跳转到根目录 cd ~
使用find -name robots.txt 找到所有名为robots.txt的位置
![]()
使用 vi ./www/server/phpmyadmin/phpmyadmin_d6c29777ac46669a/robots.txt 进行设置
同时将robots.txt文件复制到自己页面根目录下,这样就可以直接通过输入域名+robots.txt看到文本了
2020.5.5补充:也可以不使用上面的操作,直接在下面的链接生成robots.txt放到域名的根目录下即可
http://tool.chinaz.com/robots/
这里可以看到我的服务器是不允许所有人爬取的,由于我的网站目前是个人学习网站,所以我将改变这个情况以供大家爬取,同时也能是百度谷歌爬取到我的网站,使得更容易收录在数据库中。也可以按照自己的需求设置。
我将所有Disallow全部改成Allow(注意:首字母一定要大写,这里我允许所有爬虫爬取以供学习使用)
补充注意:如果设置成Disallow: 则允许爬取,一定要加 /
Disallow: /wp-*.php表示禁止搜索引擎抓取 WordPress 网站根目录的以 wp 开头的文件。

User-agent:定义搜索引擎,其中*表示所有,Baiduspider表示百度蜘蛛,Googlebot表示谷歌蜘蛛。
也就是说User-agent:*表示定义所有蜘蛛,User-agent:Baiduspider表示定义百度蜘蛛。
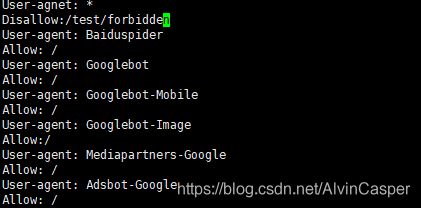
目前自己使用爬虫爬取会显示没有找到站点,还未找到原因:(更新:已找到原因,可以参考https://mp.csdn.net/console/editor/html/105913759)

如果要设置更为具体,可以参照下面的格式(下面格式禁止大部分爬虫,若允许改为Allow即可,或去掉/)
- User-agent: Baiduspider
- Disallow: /
- User-agent: Googlebot
- Disallow: /
- User-agent: Googlebot-Mobile
- Disallow: /
- User-agent: Googlebot-Image
- Disallow:/
- User-agent: Mediapartners-Google
- Disallow: /
- User-agent: Adsbot-Google
- Disallow: /
- User-agent:Feedfetcher-Google
- Disallow: /
- User-agent: Yahoo! Slurp
- Disallow: /
- User-agent: Yahoo! Slurp China
- Disallow: /
- User-agent: Yahoo!-AdCrawler
- Disallow: /
- User-agent: YoudaoBot
- Disallow: /
- User-agent: Sosospider
- Disallow: /
- User-agent: Sogou spider
- Disallow: /
- User-agent: Sogou web spider
- Disallow: /
- User-agent: MSNBot
- Disallow: /
- User-agent: ia_archiver
- Disallow: /
- User-agent: Tomato Bot
- Disallow: /
- User-agent: *
- Disallow: /
robots.txt的语法:
a、User-agent: 应用下文规则的漫游器,比如Googlebot,Baiduspider等。
b、Disallow: 要拦截的网址,不允许机器人访问。
c、Allow: 允许访问的网址
d、”*” : 通配符—匹配0或多个任意字符。
e、”$” : 匹配行结束符。
f、”#” : 注释—说明性的文字,不写也可。
g、Googlebot: 谷歌搜索机器人(也叫搜索蜘蛛)。
h、Baiduspider: 百度搜索机器人(也叫搜索蜘蛛)。
i、目录、网址的写法:都以以正斜线 (/) 开头。如:
1.5 设置Robots.txt注意事项
写robots.txt文件时语法一定要用对,User-agent、Disallow、Allow、Sitemap这些词都必须是第一个字母大写,后面的字母小写,而且在:后面必须带一个英文字符下的空格。
网站上线之前切记写robots.txt文件禁止蜘蛛访问网站,如果不会写就先了解清楚写法之后再写,以免给网站收录带来不必要的麻烦。
robots.txt文件生效时间在几天至一个月之间,站长自身无法控制。但是,站长可以在百度统计中查看网站robots.txt文件是否生效。
1.6查看是否被收录
- 可以直接使用http://seo.chinaz.com/查询收录情况

- 可以直接在搜索框里搜索网站,可以看到目前我的网站还未被收录
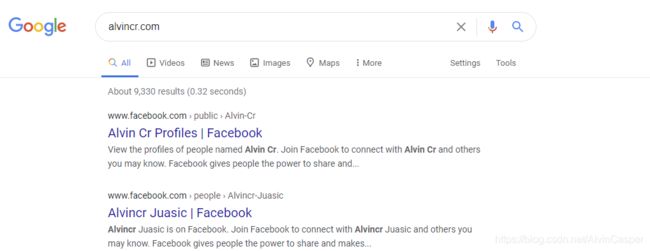
- 使用site alvincr.com命令,可以找到使用自己网站链接的网站(可查看总的收录量)

- 对于百度来说可以用百度搜索资源平台
1.7 手动提交网站
链接提交工具是网站主动向搜索推送数据的工具,可缩短爬虫发现网站链接时间,网站时效性内容建议使用链接提交工具,实时向搜索推送数据。本工具可加快爬虫抓取速度,无法解决网站内容是否收录问题
百度:http://zhanzhang.baidu.com/sitesubmit/index?sitename=http%3A%2F%2Falvincr.com
2 其它提升曝光方法
创造原创内容。想从搜索引擎获得流量,就该把所有时间集中在一件事上,努力添加原创内容。这是Google和公司都最为看重的,原创内容越多,更新越频繁,效果越好。
构建反向链接。想提升搜索排名获得自然流量第二重要的事是构建反向链接。需要有尽可能多的网站链接到你的网站,链接的权威性和相关性越高,效果越好。比如你有一个科技类博客,获得从TechCrunch或者其他权威科技博客的链接将会对SEO有着奇迹般的作用。
实施关键词研究。搜索引擎围绕关键词工作,了解人们使用什么关键词才能调整内容与之相匹配。比如,关键词“funny pictures”(搞笑图片)的搜索量是“funny images”(搞笑图像)的15倍,所以在标题中使用“funny pictures”更有帮助。使用谷歌AdWords关键词工具可以查询任何关键词的搜索量。
优化网页标题。网页标题是指网页的标题部分,位于HTML代码头部的标签
之间,访问网页时出现在浏览器顶端标题栏中。这是一项非常重要的页面SEO因素。应该确认网站每个网页都有独特的网页标题,而且关键词要出现在其中。WordPress用户可以装All in One SEO Pack的插件来自动实现。 创建一个HTML网站地图。一个HTML网站地图是一个链接到其他所有页面的网页(最好是也被其他所有网页链接)。HTML网站地图帮助搜索引擎抓取和索引网站,提高搜索排名。
使用图片。大多数站长都忘记了Google有个非常受欢迎的“图片搜索”,这意味着在网页中使用图片也可以增加从搜索引擎来的流量。确保利用相关关键词优化好图片的名字,记着在图片中经常使用ALT和TITLE属性。在网站sxc.hu上可以找到成千上万的版权免费图片。
翻译网站内容。根据网站的主题,翻译网站成其他语言网页可能在搜索引擎中获得倍增的流量。想达到这个目标还需要一个能使搜索引擎索引翻译后网页的插件。WordPres用户可以使用这个Global Translator。
3 优化自己的服务器
目的:防止其它人无法访问,或是百度谷歌爬虫无法爬取到自己的网站。
-
CDN加速
https://zhuanlan.zhihu.com/p/33359713
-
防盗链
个人认为非企业用户没必要设置防盗链,除非访问量巨大,服务器承担不住,或是被恶意攻击,导致其他人也无法访问。不过对于新建网站基本上访问量很小,即使有盗链也没太大影响。
宝塔防盗链方法:
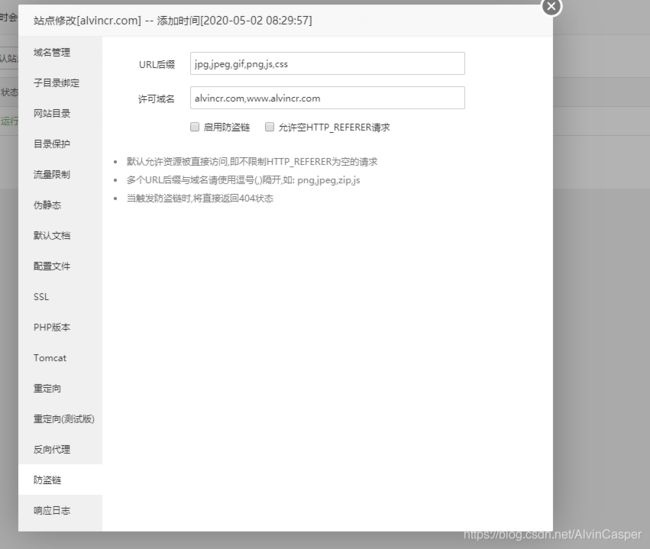
以下是其它目测可行的方案,由于个人不去设置,所以不列出自己的过程。
相关解释可跳转到3.1
nginx配置方式防盗链
主要是利用valid_referers指令防盗链,例如防止未经允许的网站盗链图片、文件等。
因为HTTPReferer头信息是可以通过程序来伪装生成的,所以通过Referer信息防盗链并非100%可靠,但是,它能够限制大部分的盗链
该指令"valid_referers"的语法:
valid_referers [none|blocked|server_names] ...默认值:none
使用环境:server,location
该指令会根据Referer Header头的内容分配一个值为0或1给变量$invalid_referer。
如果RefererHeader头不符合valid_referers指令设置的有效Referer,变量$invalid_referer
将被设置为1.
该指令的参数可以为下面的内容:
none:表示无Referer值的情况。
blocked:表示Referer值被防火墙进行伪装。
server_names:表示一个或多个主机名称。从Nginx0.5.33版本开始,server_names中可以使用通配符"*"号。实例演示:
修改nginx.conf:
- 第一行:
location ~ .*.(gif|jpg|jpeg|png|bmp|swf)$
其中“gif|jpg|jpeg|png|bmp|swf”设置防盗链文件类型,自行修改,每个后缀用“|”符号分开!
- 第三行:
valid_referers none blocked *.http://sosogoto.com sosogoto.com;
就是白名单,允许文件链出的域名白名单,自行修改成您的域名!*.http://sosogoto.com这个指的是子域名,域名与域名之间使用空格隔开!
- 第五行:
rewrite ^/ http://qita/cdn/404.jpg;
这个图片是盗链返回的图片,也就是替换盗链网站所有盗链的图片。这个图片要放在没有设置防盗链的网站上,因为防盗链的作用,这个图片如果也放在防盗链网站上就会被当作防盗链显示不出来了,盗链者的网站所盗链图片会显示X符号。
这样设置差不多就可以起到防盗链作用了,上面说了,这样并不是彻底地实现真正意义上的防盗链!
我们来看第三行:valid_referers 里有 “none blocked”,我们把“none blocked”删掉,改成如下配置:
这样您在浏览器直接输入图片地址就不会再显示图片出来了,也不可能会再右键另存什么的。
第五行:
rewrite ^/ http://qita/cdn/404.jpg这个是给图片防盗链设置的防盗链返回图片。
如果文件也需要防盗链下载,把第五行:
rewrite ^/ http://qita/cdn/404.jpg改成一个链接,可以是您主站的链接,比如把第五行改成:
rewrite ^/ http://www.sosogoto.com;这样,当别人输入文件下载地址,由于防盗链下载的作用就会跳转到您设置的这个链接!
最后,重启nginx生效!


4.学习中遇到的名词
3.1 盗链
“盗链”的定义是:此内容不在自己服务器上,而通过技术手段,绕过别人放广告有利益的最终页,直接在自己的有广告有利益的页面上向最终用户提供此内容。 常常是一些名不见经传的小网站来盗取一些有实力的大网站的地址(比如一些音乐、图片、软件的下载地址)然后放置在自己的网站中,通过这种方法盗取大网站的空间和流量。
为什么会产生盗链
一般浏览有一个重要的现象就是一个完整的页面并不是一次全部传送到客户端的。如果请求的是一个带有许多图片和其它信息的页面,那么最先的一个Http请求被传送回来的是这个页面的文本,然后通过客户端的浏览器对这段文本的解释执行,发现其中还有图片,那么客户端的浏览器会再发送一条Http请求,当这个请求被处理后那么这个图片文件会被传送到客户端,然后浏览器回将图片安放到页面的正确位置,就这样一个完整的页面也许要经过发送多条Http请求才能够被完整的显示。基于这样的机制,就会产生一个问题,那就是盗链问题:就是一个网站中如果没有起页面中所说的信息,例如图片信息,那么它完全可以将这个图片的连接到别的网站。这样没有任何资源的网站利用了别的网站的资源来展示给浏览者,提高了自己的访问量,而大部分浏览者又不会很容易地发现,这样显然,对于那个被利用了资源的网站是不公平的。一些不良网站为了不增加成本而扩充自己站点内容,经常盗用其他网站的链接。一方面损害了原网站的合法利益,另一方面又加重了服务器的负担。
备注:图片记录的是存储地址,而通过这个存储地址找到的是第一个服务器,因此不占用自己的资源,又是既得利益者。
3.2 网站地图
站点地图(英语:Sitemap)描述了一个网站的架构。[1] 它可以是一个任意形式的文档,用作网页设计的设计工具,也可以是列出网站中所有页面的一个网页,通常采用分级形式。这有助于访问者以及搜索引擎的爬虫找到网站中的页面。
网站地图的好处:
网站地图对于提高用户体验有好处:它们为网站访问者指明方向,并帮助迷失的访问者找到他们想看的页面。对于SEO,网站地图的好处就更多了:
- 为搜索引擎爬虫提供可以浏览整个网站的链接;
- 为搜索引擎爬虫提供一些链接,指向动态页面或者采用其他方法比较难以到达的页面;
- 如果访问者试图访问网站所在域内并不存在的URL,那么这个访问者就会被转到“无法找到文件”的错误页面,而网站地图可以作为该页面的“准”内容。
3.3 爬取与反爬取策略
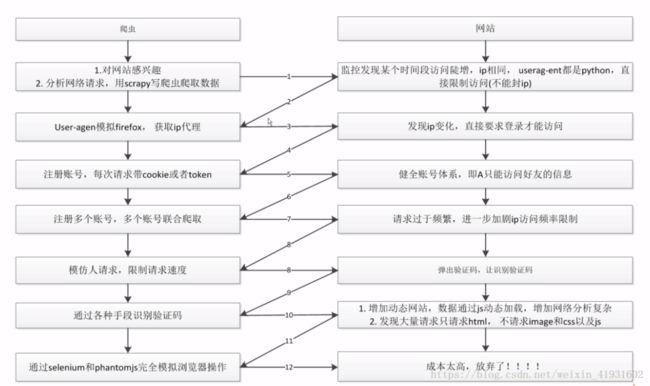
3.4 PPC,PPC推广
PPC是英文Pay Per Click的缩写形式,其中文本意思就是点击付费广告,又称竞价排名或关键词广告。点击付费广告是大公司最常用的网络广告形式。这种方法费用很高,但效果也很好。比如百度推广,搜狐和新浪首页上的banner广告。这种形式的广告是这样收费的:起价+点击数x每次点击的价格。越是著名的搜索引擎,起价越高,最高可达数万甚至数十万。而每次点击的价格在0.30元左右。提供点击付费的网站非常多,主要有各大门户网站(如搜狐、新浪)搜索引擎(Google和百度),以及其他浏览量较大的网站。
我们常说的PPC是指搜索引擎营销中的PPC推广,PPC(Pay-Per-Click)搜索引擎营销,亦被称作PFP(Pay-For-Performance:按业绩付费),即是根据点击广告或者电子邮件信息的用户数量来付费的一种网络广告定价模式。PPC广告服务的最大特色就在于客户只需为实际的访问付钱。也就是说,只有当客户的网站广告链接被实际点击后才会产生费用。因而保证了访问量的高度目标性。
PPC广告服务的第二个特色就是网站排名的可操控性,即客户可以通过调整每次点击付费价格来控制自己在特定关键字搜索结果中的网站排名。
同时,PPC搜索引擎的前3到5页搜索结果往往也会被其搜索合作伙伴站点所引用。例如Overture广告服务的前三个客户的网站也会同时出现在MSN,Yahoo等著名站点的首页位置。
此外,较一些大型搜索引擎的付费收录服务和全页广告而言,PPC广告的费用相对要低一些。因而该服务不失为一项既能够为网站带来目标访问量,同时规避了投资的风险性的有效途径。其不足之处在于:对一些中小型公司来说其费用还是有些偏高,且管理上有一定难度。
参考:
如何正确设置使用robots.txt文件
https://www.sohu.com/a/31881192_230028
如何设置网站的robots.txt
http://www.mamicode.com/info-detail-2756627.html.
笔记-爬虫-robots.txt
https://www.bbsmax.com/A/WpdK6bGN5V/
什么是PPC,PPC推广是什么?
http://blog.sina.com.cn/s/blog_b9d518d20101e2xi.html
100种增加网站流量的方法
http://www.woshipm.com/operate/1791.html