机器学习入门(六):支持向量机(SVM),支持向量回归(SVR)及pipeline的使用
关于支持向量机的理论和证明都非常多,这里主要想讲一下代码实现及各参数的含义及作用。
SVM的主要目的是找到一个平面,使得支持向量离这个平面尽量的远,所以常用于分类问题,而支持向量回归(SVR)的主要目的是找到一个平面近可能离所有的点都很近,从而实现回归。
1)SVM:
首先看下其各项参数,详细地址见sklearn.svm


一般调以下几个参数:
kernel: 核,选项有’linear’ 线性核,‘poly’ 多项式核, ‘rbf’ 高斯核, 'sigmoid’等。
C: 惩罚系数,英文写的是Regularization parameter,默认值1。C越大,对错误的容忍越低,会减小与训练集的差值,但同时也会使得margin变小,泛化能力降低,会导致过拟合。反之,C越小,会适当忽略一些差值较大的点,但泛化能力较好,容易导致欠拟合。所以C太大和太小都不好。
gamma:主要用在rbf, poly和sigmoid,gamma越大,样本的接受度和影响也会下降,从而导致对错误的容忍度降低。所以当欠拟合的时候gamma应该增加。相反,小的gamma容忍度较高,适合在过拟合的时候使用。
degree:多项式核的度数。
probability: 是否采用概率估计?.默认为False
cache_size: 运行内存使用大小,默认为200M,如果设备允许可以设多一点。
shrinking:是否采用shrinking heuristic方法,默认为true
class_weight: 类别权重。
由于有GridSearch,所以有时候调参可以让它帮我们完成,这里不再过多讲解,关于GridSearchCV的使用可以参考这篇文章的最后部分GridSearchCV。
直接代码演示SVM,先导入需要的包,然后用make_moons生成数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
import random
np.random.seed(22)
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, noise=0.15, random_state=22)
def plot_dataset(X, y, axes):
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs")
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "g^")
plt.axis(axes)
plt.grid(True, which='both')
plt.xlabel(r"$x_1$", fontsize=20)
plt.ylabel(r"$x_2$", fontsize=20, rotation=0)
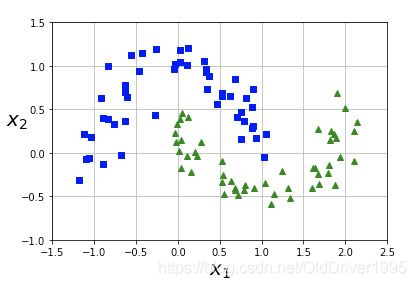
plot_dataset(X, y, [-1.5, 2.5, -1, 1.5])
plt.show()
生成的数据长这个样子:
(2020.04.04添加)画分界线的代码长这样, 他将利用decision_function来画出更加细致的图:
def plot_boundary(clf, axes):
x1= np.linspace(axes[0], axes[1], 100)
x2= np.linspace(axes[0], axes[1], 100)
xx, yy = np.meshgrid(x1, x2)
x_new = np.c_[xx.ravel(), yy.ravel()]
y_pred = clf.predict(x_new).reshape(xx.shape)
y_decision=clf.decision_function(x_new).reshape(xx.shape)
plt.contourf(xx, yy, y_pred, alpha = 0.4, cmap=plt.cm.brg)
plt.contourf(xx,yy,y_decision, alpha=0.3, cmap=plt.cm.brg)
这里直接使用rbf,其他几种核稍微修改一下参数即可查看。
选取几种不同的gamma和C的组合进行演示
gamma1, gamma2 = 0.1, 5
C1, C2 = 0.001, 1000
hyperparams = (gamma1, C1), (gamma1, C2), (gamma2, C1), (gamma2, C2)
svm_clfs = []
for gamma, C in hyperparams:
rbf_kernel_svm_clf = Pipeline([
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=gamma, C=C))
])
rbf_kernel_svm_clf.fit(X, y)
svm_clfs.append(rbf_kernel_svm_clf)#这里会产生四个clf
#将画布分成四块
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10.5, 7), sharex=True, sharey=True)
for i, svm_clf in enumerate(svm_clfs):
plt.sca(axes[i // 2, i % 2])
plot_boundary(svm_clf, [-1.5, 2.45, -1, 1.5])
plot_dataset(X, y, [-1.5, 2.45, -1, 1.5])
gamma, C = hyperparams[i]
plt.title(r"$\gamma = {}, C={}$".format(gamma, C), fontsize=16)
if i in (0, 1):
plt.xlabel("")
if i in (1, 3):
plt.ylabel("")
plt.show()
运行结果如图:

(2020.04.04更新)下面是画出了decision_function之后的图像:
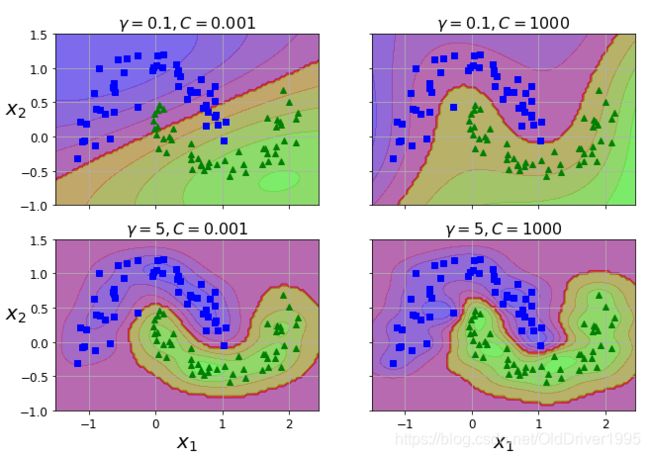
(2020.04.04添加)通过对比右上角和右下角两张图,在C相同的情况下,gamma更大缺失导致了更加复杂紧致的边界,说明他的容忍度有所降低。同时也能看出decision_function的边界有所变小。
可以发现当gamma=5时,C的值对分类结果影响不是很大。
2)SVR:
使用方式和SVM相似,这一次我们会和多项式回归进行对比,代码如下:
#支持向量回归
from sklearn.svm import SVR
#用于多项式回归
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
#生成数据
X = np.sort(3 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
# 噪音
y[::5] += 2.5 * (0.5 - np.random.rand(8))
然后建立对应的模型,这里一共参考四个模型,分别是gamma=10,C=100的SVR,gamma=100,C=100的SVR,gamma=1,C=10的SVR以及多项式回归。
利用pipeline快速构建多项式回归,pipeline一般的标准流程如下图(数据处理,降维,训练模型,预测):

代码如下:
nonLinearRegr = Pipeline([
('poly',PolynomialFeatures(degree=2)),
('clf',LinearRegression())
])
nonLinearRegr.fit(X, y)
然后构建三个不同的SVR:
svr_gamma100 = SVR(kernel='rbf',gamma=100, C=100)
svr_gamma100.fit(X, y)
svr_gamma10 = SVR(kernel='rbf',gamma=10, C=100)
svr_gamma10.fit(X,y)
svr_C10 = SVR(kernel='rbf',gamma=1,C=10)
svr_C10.fit(X,y)
然后生成对应图像:
plt.scatter(X, y,color='lightblue',label='data')
plt.plot(X, nonLinearRegr.predict(X),c='red',label='poly reg')
plt.plot(X, svr_gamma100.predict(X), c='green',label='SVR_ga100')
plt.plot(X, svr_gamma10.predict(X), c='orange',label='SVR_ga10')
plt.plot(X,svr_C10.predict(X), c='black', label='svr_C10')
plt.legend(loc='upper right')
plt.show()
运行结果如图:

这里就不再对各个模型进行评分比较,直接从图像上最直观的感受,可以发现当gamma=100时(绿线),模型对偏离出去的值都非常重视,模型容错率较低。而gamma=10时,黄线就没那么曲折了,很多偏离点直接忽视。而gamma=1,C=10的时候(黑线),基本上跟多项式回归(红线)差不多了。
参考文献:Python Machine Learning(作者Sebastian Raschka)