leetcode刷题笔记-string
809. Expressive Words
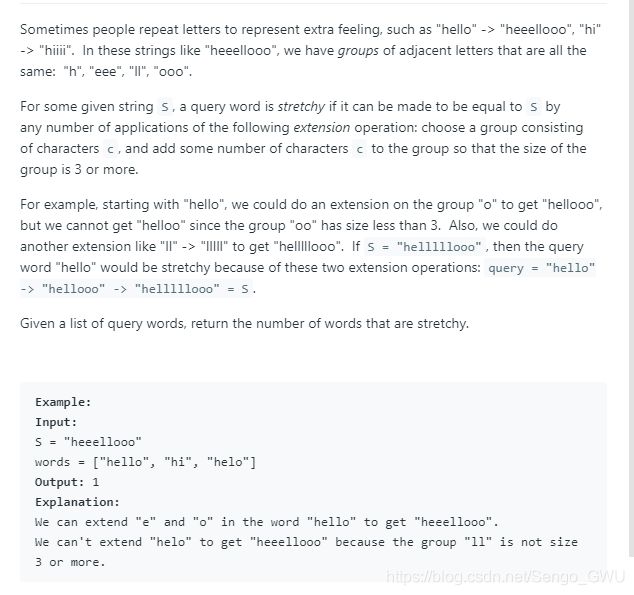

class Solution(object):
def expressiveWords(self, S, words):
re = 0
def check(W, S):
i, j, s, w = 0, 0, len(S), len(W)
for i in xrange(s):
if j < w and S[i] == W[j]: j += 1
elif S[i-1: i+2] != S[i] * 3 != S[i-2: i+1]: return False
return j == w
for word in words:
re += check(word, S)
return re
722. Remove Comments
题目太长 https://leetcode.com/problems/remove-comments/description/
class Solution(object):
def removeComments(self, source):
res = []
block = False
cur = ''
for line in source:
i = 0
while i < len(line):
c = line[i]
if c == '/' and i + 1 < len(line) and line[i+1] == '/' and not block: # //
i = len(line)
elif c == '/' and i + 1 < len(line) and line[i+1] == '*' and not block: # /*
block = True
i += 1
elif c == '*' and i + 1 < len(line) and line[i+1] == '/' and block: # */
block = False
i += 1
elif not block and i < len(line):
cur += c
i += 1
if cur and not block:
res.append(cur)
cur = ''
return res186. Reverse Words in a String II
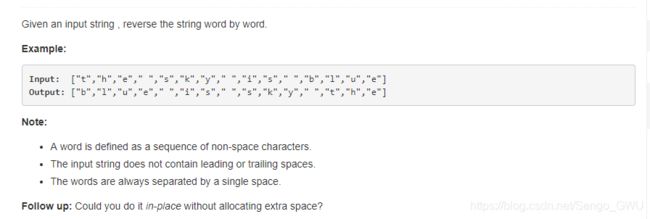
先reverse 整个string,再reverse 每个word
class Solution(object):
def reverseWords(self, s):
def reverse(s, start, end):
while start < end:
s[start], s[end] = s[end], s[start]
start += 1
end -= 1
# reverse the whole string
reverse(s, 0, len(s)-1)
# reverse word by word
start = 0
for i, c in enumerate(s):
if c == ' ':
reverse(s, start, i-1)
start = i + 1
elif i == len(s) - 1:
reverse(s, start, i)
68. Text Justification

重点是 中间的space怎么分配
class Solution(object):
def fullJustify(self, words, maxWidth):
length, res, temp = 0, [], []
for w in words:
if length + len(w) + len(temp)> maxWidth: # 要加上len(temp) 否则各个单词中间可能就没有空格了
for i in xrange(maxWidth - length):
temp[i % (len(temp)-1 or 1)] += ' ' # 这里要-1 因为只要中间有空格,最后一个不要. Or 1 是因为只有1个字符串的时候空格全部加在这个字符串后面
res.append(''.join(temp))
temp = []
length = 0
length += len(w)
temp.append(w)
return res + [' '.join(temp).ljust(maxWidth)] # ljust 左对齐,并用空格填充
12. Integer to Roman
这题太简单了,但是很有意思记录一下。
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
Symbol Value
I 1
V 5
X 10
L 50
C 100
D 500
M 1000For example, two is written as II in Roman numeral, just two one's added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
Ican be placed beforeV(5) andX(10) to make 4 and 9.Xcan be placed beforeL(50) andC(100) to make 40 and 90.Ccan be placed beforeD(500) andM(1000) to make 400 and 900.
Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
Input: 3
Output: "III"Example 2:
Input: 4
Output: "IV"Example 3:
Input: 9
Output: "IX"Example 4:
Input: 58
Output: "LVIII"
Explanation: C = 100, L = 50, XXX = 30 and III = 3.
Example 5:
Input: 1994
Output: "MCMXCIV"
Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.class Solution(object):
def intToRoman(self, num):
"""
:type num: int
:rtype: str
"""
nums = [1000, 900, 500, 400, 100, 90, 50, 40, 10, 9, 5, 4, 1]
romans = ['M', 'CM', 'D', 'CD', 'C', 'XC', 'L', 'XL', 'X', 'IX', 'V', 'IV', 'I']
i, res = 0, ""
while num:
if num - nums[i] >= 0:
num -= nums[i]
res += romans[i]
else:
i += 1
return res539. Minimum Time Difference
Given a list of 24-hour clock time points in "Hour:Minutes" format, find the minimum minutes difference between any two time points in the list.
Example 1:
Input: ["23:59","00:00"]
Output: 1
Note:
- The number of time points in the given list is at least 2 and won't exceed 20000.
- The input time is legal and ranges from 00:00 to 23:59.
class Solution(object):
def findMinDifference(self, timePoints):
"""
:type timePoints: List[str]
:rtype: int
"""
def countMinute(h, m):
return h*60 + m
minutes, res = [], 100000
for time in timePoints:
h, m = time.split(":")
minutes.append(countMinute(int(h), int(m)))
minutes = sorted(minutes)
hour24 = 24*60
for i in xrange(len(minutes)):
if i == len(minutes) - 1:
diff = minutes[i] - minutes[0]
else:
diff = minutes[i+1] - minutes[i]
diff = min(hour24 - diff, diff)
res = min(res, diff)
return res17. Letter Combinations of a Phone Number
Given a string containing digits from 2-9 inclusive, return all possible letter combinations that the number could represent.
A mapping of digit to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters.

Example:
Input: "23"
Output: ["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].class Solution(object):
def letterCombinations(self, digits):
"""
:type digits: str
:rtype: List[str]
"""
if not digits: return []
kvmaps = {"1":"", "2":"abc", "3":"def", "4":"ghi", "5":"jkl", "6":"mno", "7":"pqrs","8":"tuv","9":"wxyz","10":" "}
res = [""]
for i in digits:
chars = kvmaps[i]
newRes = []
for c in chars:
for r in res:
newRes.append(r+c)
res = newRes
return res767. Reorganize String
Given a string S, check if the letters can be rearranged so that two characters that are adjacent to each other are not the same.
If possible, output any possible result. If not possible, return the empty string.
Example 1:
Input: S = "aab"
Output: "aba"
Example 2:
Input: S = "aaab"
Output: ""- Sort the letters in the string by their frequency. (I used Counter of python.)
- Create the piles as many as the max frequency.
- Put the letter one by one from the sorted string onto the piles with cyclic order.
- Finally, concatenate the letters in each pile.
from collections import Counter
class Solution(object):
def reorganizeString(self, S):
counter = Counter(S).most_common() # 1
_, max_freq = counter[0]
if max_freq > (len(S)+1)//2:
return ""
else:
buckets = [[] for i in range(max_freq)] #2
begin = 0
for letter, count in counter:
for i in range(count):
buckets[(i+begin)%max_freq].append(letter) #3
begin += count
return "".join("".join(bucket) for bucket in buckets) #4522. Longest Uncommon Subsequence II
Given a list of strings, you need to find the longest uncommon subsequence among them. The longest uncommon subsequence is defined as the longest subsequence of one of these strings and this subsequence should not be any subsequence of the other strings.
A subsequence is a sequence that can be derived from one sequence by deleting some characters without changing the order of the remaining elements. Trivially, any string is a subsequence of itself and an empty string is a subsequence of any string.
The input will be a list of strings, and the output needs to be the length of the longest uncommon subsequence. If the longest uncommon subsequence doesn't exist, return -1.
Example 1:
Input: "aba", "cdc", "eae"
Output: 3最长的不重复子序列只可能是某整个单词。
class Solution(object):
def findLUSlength(self, strs):
"""
:type strs: List[str]
:rtype: int
"""
def subseq(w1, w2):
i = 0
for c in w2:
if i < len(w1) and c == w1[i]:
i += 1
return i == len(w1)
strs.sort(key=len, reverse=True)
for i, word1 in enumerate(strs):
if all(not subseq(word1, word2) for j, word2 in enumerate(strs) if j!=i):
return len(word1)
return -193. Restore IP Addresses
Given a string containing only digits, restore it by returning all possible valid IP address combinations.
Example:
Input: "25525511135"
Output: ["255.255.11.135", "255.255.111.35"]
思路,每次加1到3位,判断每次加的符不符合,加4次返回。
class Solution(object):
def restoreIpAddresses(self, s):
"""
:type s: str
:rtype: List[str]
"""
res = []
self.dfs(s, 0, "", res)
return res
def dfs(self, s, index, cur, res):
if index == 4:
if not s:
res.append(cur[:-1])
return
if len(s) >= 1:
# choose one digits
self.dfs(s[1:], index+1, cur+s[:1]+'.', res)
# choose two digits, the first one should not be 0
if len(s) >= 2 and s[0] != '0':
self.dfs(s[2:], index+1, cur+s[:2]+'.', res)
# choose 3 digits, the first one should not be 0, and should not bigger than 255
if len(s) >= 3 and s[0] != '0' and int(s[:3]) < 256:
self.dfs(s[3:], index+1, cur+s[:3]+'.', res)556. Next Greater Element III
31. Next Permutation 两题一样的
Given a positive 32-bit integer n, you need to find the smallest 32-bit integer which has exactly the same digits existing in the integer nand is greater in value than n. If no such positive 32-bit integer exists, you need to return -1.
Example 1:
Input: 12
Output: 21
Example 2:
Input: 21
Output: -1class Solution(object):
def nextGreaterElement(self, n):
"""
:type n: int
:rtype: int
"""
n = list(str(n))
length = len(n)
firstSmall = -1
for i in xrange(length-1-1, -1,-1):
if n[i] < n[i+1]:
firstSmall = i
break
if firstSmall == -1:
return -1
firstLarge = -1
for i in xrange(length-1, -1, -1):
if n[i] > n[firstSmall]:
firstLarge = i
break
n[firstSmall], n[firstLarge] = n[firstLarge], n[firstSmall]
res = n[:firstSmall+1] + n[-1:firstSmall:-1]
res = int("".join(res))
return res if res < 2**31 else -1 6. ZigZag Conversion
The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N
A P L S I I G
Y I R
And then read line by line: "PAHNAPLSIIGYIR"
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows);Example 1:
Input: s = "PAYPALISHIRING", numRows = 3
Output: "PAHNAPLSIIGYIR"
Example 2:
Input: s = "PAYPALISHIRING", numRows = 4
Output: "PINALSIGYAHRPI"
Explanation:
P I N
A L S I G
Y A H R
P Iclass Solution(object):
def convert(self, s, numRows):
"""
:type s: str
:type numRows: int
:rtype: str
"""
if numRows == 1 or numRows >= len(s):
return s
res = [""] * numRows
index, step = 0, 0
for c in s:
res[index] += c
if index == 0:
step = 1
elif index == numRows - 1:
step = -1
index += step
return "".join(res)71. Simplify Path
Given an absolute path for a file (Unix-style), simplify it.
For example,
path = "/home/", => "/home"
path = "/a/./b/../../c/", => "/c"
class Solution(object):
def simplifyPath(self, path):
"""
:type path: str
:rtype: str
"""
stack = []
for p in path.split('/'):
if p in ('', '.'):
pass
elif p == '..':
if stack: stack.pop()
else:
stack.append(p)
return "/" + "/".join(stack)3. Longest Substring Without Repeating Characters

第一次解法,超时,意料之中,不过帮助理了下思路接着就想到避免重复计算的解法。
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
if not s:
return 0
res = []
for i, c in enumerate(s):
self.helper(s, res, [], s[i], i)
return max(res)
def helper(self, s, res, cur, c, index):
if c in cur:
res.append(len(cur))
return
else:
cur.append(c)
if index == len(s) - 1:
res.append(len(cur))
elif index + 1 < len(s):
self.helper(s, res, cur, s[index + 1], index + 1)第二次:
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
longest = start = 0
used = {}
for i, c in enumerate(s):
if c in used and start <= used[c]:
start = used[c] + 1
used[c] = i
longest = max(longest, i-start+1)
return longest165. Compare Version Numbers

class Solution(object):
def compareVersion(self, version1, version2):
"""
:type version1: str
:type version2: str
:rtype: int
"""
v1, v2 = version1.split('.'), version2.split('.')
l1, l2 = len(v1), len(v2)
if l1 < l2:
v1 += [0] * (l2-l1)
else:
v2 += [0] * (l1-l2)
for i in xrange(len(v1)):
if int(v1[i]) > int(v2[i]):
return 1
elif int(v1[i]) < int(v2[i]):
return -1
return 0468. Validate IP Address


class Solution(object):
def validIPAddress(self, IP):
"""
:type IP: str
:rtype: str
"""
def isIPv4(s):
try:
return s == str(int(s)) and 0 <= int(s) < 256
except:
return False
def isIPv6(s):
if not 1 <= len(s) <= 4:
return False
try:
return int(s, 16) >= 0 and s[0] != '-'
except:
return False
if IP.count('.') == 3 and all(isIPv4(s) for s in IP.split('.')):
return 'IPv4'
if IP.count(':') == 7 and all(isIPv6(s) for s in IP.split(':')):
return 'IPv6'
return 'Neither'151. Reverse Words in a String

这题似曾相识,之前在网上看到的阿里巴巴的面试题。但是Python,java没办法做到O(1)space因为字符串是无法修改的,修改只会生成新的对象。
class Solution(object):
def reverseWords(self, s):
"""
:type s: str
:rtype: str
"""
s = s[::-1]
word = words = ""
for i, c in enumerate(s):
if c != ' ' and word != '' and i > 0 and s[i - 1] == ' ':
words += word + ' '
word = c
elif c != ' ':
word = c + word
words += word
return words8. String to Integer (atoi)
这道题题目很傻逼,题目讲的很不清楚,例子也不清楚,你不一直试错根本不知道哪些情况没考虑。
class Solution(object):
def myAtoi(self, string):
if not string:
return 0
res = ""
s = [c for c in string.split(' ') if c]
if not s:
return 0
word = s[0]
if word[0] not in ('+', '-') and not ('0' <= word[0] <= '9'):
return 0
word = word.split('.')[0]
if word in ('+', '-'): return 0
if len(word) > 1 and word[0] in ('+', '-') and not ('0' <= word[1] <= '9'): return 0
for i, c in enumerate(word):
if '0' <= c <= '9' or i == 0:
res += c
else:
break
word = int(res)
if word >= 2 ** 31:
word = 2 ** 31-1
elif word < -2 ** 31:
word = -2 ** 31
return word273. Integer to English Words

这题如果不看答案,不知道得话多少时间才能解出来。主要不是难,是对英语数字规则的不了解。
class Solution(object):
def __init__(self):
self.lessThan20 = ["", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine", "Ten", "Eleven",
"Twelve", "Thirteen", "Fourteen", "Fifteen", "Sixteen", "Seventeen", "Eighteen", "Nineteen"]
self.tens = ["", "Ten", "Twenty", "Thirty", "Forty", "Fifty", "Sixty", "Seventy", "Eighty", "Ninety"]
self.thousands = ["", "Thousand", "Million", "Billion"]
def numberToWords(self, num):
"""
:type num: int
:rtype: str
"""
if num == 0:
return 'Zero'
res = ''
for i in xrange(len(self.thousands)):
if num % 1000 != 0:
res = self.helper(num%1000) + self.thousands[i] + ' ' + res # 注意这里有空格
num = num / 1000
return res.strip()
def helper(self, num):
if num == 0:
return ""
if num < 20:
return self.lessThan20[num] + ' '
elif num < 100:
return self.tens[num/10] + ' ' + self.helper(num%10)
else:
return self.lessThan20[num/100] + ' Hundred ' + self.helper(num%100)681. Next Closest Time
Given a time represented in the format "HH:MM", form the next closest time by reusing the current digits. There is no limit on how many times a digit can be reused.
You may assume the given input string is always valid. For example, "01:34", "12:09" are all valid. "1:34", "12:9" are all invalid.
Example 1:
Input: "19:34"
Output: "19:39"
Explanation: The next closest time choosing from digits 1, 9, 3, 4, is 19:39, which occurs 5 minutes later. It is not 19:33, because this occurs 23 hours and 59 minutes later.Example 2:
Input: "23:59"
Output: "22:22"
Explanation: The next closest time choosing from digits 2, 3, 5, 9, is 22:22. It may be assumed that the returned time is next day's time since it is smaller than the input time numerically.思路:
一分钟一分钟的加,然后判断对不对。
class Solution(object):
def nextClosestTime(self, time):
"""
:type time: str
:rtype: str
"""
h, m = time.split(':')
nums = set(n for n in time.replace(':', ''))
while True:
if m == '59':
h = str(int(h) + 1)
m = '00'
else:
m = str(int(m) + 1)
# Fix overflow
if int(h) > 23:
h = '00'
# Fill 0
if len(h) < 2:
h = '0' + h
if len(m) < 2:
m = '0' + m
if all(num in nums for num in h+m):
return h + ':' + m387. First Unique Character in a String

class Solution(object):
def firstUniqChar(self, s):
"""
:type s: str
:rtype: int
"""
letters='abcdefghijklmnopqrstuvwxyz'
indexs = [ s.index(l) for l in letters if s.count(l) == 1]
return min(indexs) if len(indexs) > 0 else -1