hash实现--开放寻址方式
今天看了一下《算法导论》第十一章的散列表,里面有一节是关于开发寻址方式。
下面是我的简单的实现:
static const int __stl_num_primes = 28; static const unsigned long __stl_prime_list[__stl_num_primes] = { 53, 97, 193, 389, 769, 1543, 3079, 6151, 12289, 24593, 49157, 98317, 196613, 393241, 786433, 1572869, 3145739, 6291469, 12582917, 25165843, 50331653, 100663319, 201326611, 402653189, 805306457, 1610612741, 3221225473ul, 4294967291ul }; unsigned int m = __stl_prime_list[0]; int Hash_Key(int key) { return key % m; } int Hash_Key1(int key) { return 1 + key % (m-1); } /* int Hash_Key(int key, int i) { return (Hash_Key(key) + i) % m; } */ int Hash_Key(int key, int i) { return (Hash_Key(key) + i * Hash_Key1(key)) % m; } int Hash_Create(int *&hashTable) { if(0 == m) { hashTable = NULL; return -1; } hashTable = new int[m]; if (NULL == hashTable) { return -1; } for(unsigned int i = 0; i < m; i++) hashTable[i] = -1; return 1; } int Hash_Insert(int *hashTable, int value) { int key = Hash_Key(value, 0); for(unsigned int i = 1; i < m; i++) { if (-1 == hashTable[key]) { hashTable[key] = value; return key; } key = Hash_Key(value, i); } return -1; } int Hash_Find(int *hashTable, int value) { int key = Hash_Key(value, 0); for(unsigned int i = 1; i < m; i++) { if(-1 == hashTable[key]) { return -1; } if(value == hashTable[key]) { return key; } key = Hash_Key(value, i); } return -1; } void Hash_Delete(int *hashTable) { delete []hashTable; }
下面是测试:
int main() { srand(time(NULL)); unsigned int k; unsigned int i; clock_t begin, finish; cin >> k; for(i = 0; i < __stl_num_primes && k > __stl_prime_list[i]; i++); m = __stl_prime_list[i]; int *hap; try { Hash_Create(hap); } catch(bad_alloc &e) { cout << "create wrong" << endl; return -1; } begin = clock(); for(unsigned int i = 0; i < m / 10; i++) { int d = Random32()%m; if( -1 == Hash_Insert(hap, d)) { cout << "insert wrong" << endl; } } finish = clock(); cout << "insert time"; cout << (double)(finish - begin)/CLOCKS_PER_SEC << endl; begin = clock(); for(unsigned int i = 0; i < m / 10; i++) { int d = Random32()%m; if( -1 == Hash_Find(hap, d)) { //cout << d << " find wrong" << endl; } } finish = clock(); cout << (double)(finish - begin)/CLOCKS_PER_SEC << endl; Hash_Delete(hap); }
其中的Random32()的实现是:
unsigned int Random32(void) { static const unsigned long x[55] = { 1410651636UL, 3012776752UL, 3497475623UL, 2892145026UL, 1571949714UL, 3253082284UL, 3489895018UL, 387949491UL, 2597396737UL, 1981903553UL, 3160251843UL, 129444464UL, 1851443344UL, 4156445905UL, 224604922UL, 1455067070UL, 3953493484UL, 1460937157UL, 2528362617UL, 317430674UL, 3229354360UL, 117491133UL, 832845075UL, 1961600170UL, 1321557429UL, 747750121UL, 545747446UL, 810476036UL, 503334515UL, 4088144633UL, 2824216555UL, 3738252341UL, 3493754131UL, 3672533954UL, 29494241UL, 1180928407UL, 4213624418UL, 33062851UL, 3221315737UL, 1145213552UL, 2957984897UL, 4078668503UL, 2262661702UL, 65478801UL, 2527208841UL, 1960622036UL, 315685891UL, 1196037864UL, 804614524UL, 1421733266UL, 2017105031UL, 3882325900UL, 810735053UL, 384606609UL, 2393861397UL }; static int init = 1; static unsigned long y[55]; static int j, k; unsigned long ul; if (init) { int i; init = 0; for (i = 0; i < 55; i++) y[i] = x[i]; j = 24 - 1; k = 55 - 1; } ul = (y[k] += y[j]); if (--j < 0) j = 55 - 1; if (--k < 0) k = 55 - 1; return((unsigned int)ul); }
c函数rand()产生的数在0~RAND_MAX之间(在我的机器,RAND_MAX的大小是32767),比较小,不利于测试,Random32函数
能产生0到unsigned int最大之间的数。
开放寻址的方式相对链表方式节省了空间(省了一个指针),但加大了插入和查找时间,特别如果插入的数重复太多的话,那么时间会有一个很大的提升。
下面是测试结果:
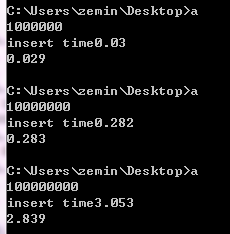
如果用rand代替Random32,测试结果是:
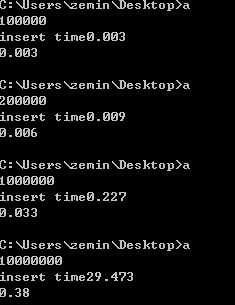
当到了10000000,对比一下就知道,那时间是花花的上去了。