爬虫字体替换(一)天眼查
1、网址
https://www.tianyancha.com
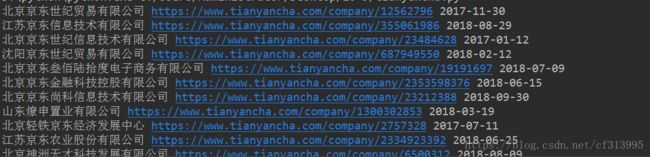
2、打开天眼查,搜索京东的页面,看到一堆关键词为京东的公司信息。
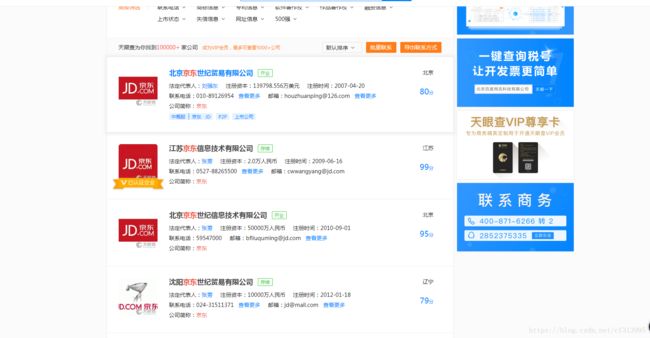
现在我们需要获取每个公司的核准日期信息,点进去查看,发现其信息做了字体的反爬措施。

3、继续查看其它公司的信息,发现他们都是经过加密替换的。且每个的class属性都是 tyc-num。通过查看网页源代码,找寻引用tyc-num这个class的css样式。发现源代码中的css样式是通过外部链接引用的。细看之下,发现了一个与font有关的css文件。
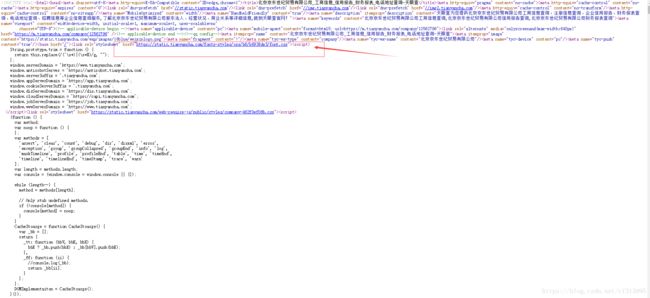
猜想是它。点击进去查看,找寻到我们想要的结果。
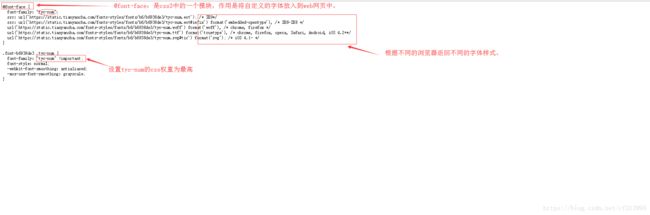
4、在开发者工具中找到network----->font,然后找到这个文件,发现作出了改变。
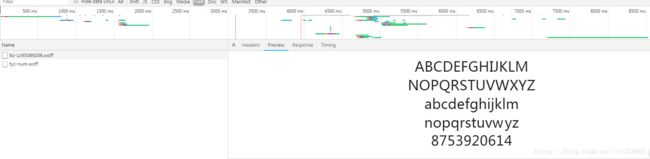
此时用我们的第三方工具打开这个文件(从headers中找到这个文件对应的网址,直接请求这个网址下载文件),发现他作出了如下改变。

用一张表展示他们之间的对应关系。

| 位置数字 | 真实数字 |
|---|---|
| 1 | 8 |
| 2 | 7 |
| 3 | 5 |
| 4 | 3 |
| 5 | 9 |
| 6 | 2 |
| 7 | 0 |
| 8 | 6 |
| 9 | 1 |
| 0 | 4 |
此时,再回到之前网页看到的。发现位置数字6792-99-47即表示真实数字2017-11-30。得到我们想要的结果。
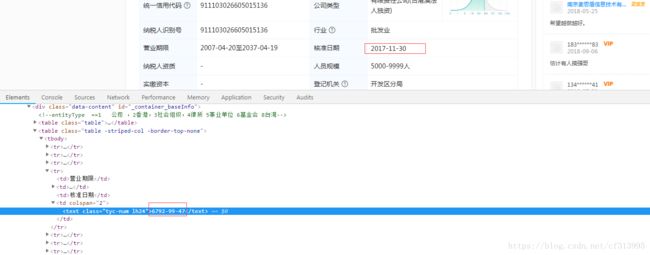
5、到这一步,已经可以获取核准日期了。但是存在一些问题。
1、字体的映射关系每刷新一次就有可能变化,也许现在这个公司的详情页是这一套,另一个公司的额详情页就变化为另一套。
2、字体的映射关系是定期更新(推测是24小时变化一次)。
3、cookie的访问次数如果过于频繁,就会弹出验证码。
4、而且同一个cookie是有时效性的,超过规定时间cookie是会过期的。
解决方案:
1、针对问题一,发现字体的映射关系共有两套,可以每一套建立一个字典。
2、针对问题二,字体的映射关系是定期更新的。
①如果爬取的数据量较小,在字体映射更新之前能完成爬取,那么直接定义一套/两套映射字典。当从源码中取到日期的时候(如以5/8开头的原始数据),直接进行判断,如果是以5开头的日期,就使用5对应的映射字典进行解析;如果是以8开头的日期,就使用8对应的映射字典进行解析。
②如果爬取的数据量很大,就不能将映射关系写死了。只能去找到映射关系,动态获取映射字典。因为字体文件是定期更新的,所以在根据字体文件获取映射关系时,不需要每次都去解析这种映射关系,只有当字体文件的url发生改变时,再去查找映射关系,如果字体文件没有发生改变,那么就使用之前的映射字典,不需要每次都进行解析映射。
3、针对问题三和四,如何管理cookie?
建立cookie池。
①可以先生成一定量的登陆后cookie,将其保存至redis数据库;
②定期检测cookie是否有效(携带cookie访问详情页,如果能够正常获取页面就是有效,如果获取的页面是要求重新登录的,说明cookie已失效)
③如果cookie失效,将失效的cookie从redis中删除,并重新使用该账户进行模拟登陆,生成新的cookie信息并保存到redis中。
4、 针对问题三和四,还可以使用代理ip。
6、此处附上问题二的解决方案之一。
import requests,re,pytesseract
from lxml.html import etree
from PIL import Image, ImageFont, ImageDraw, ImageColor
pytesseract.pytesseract.tesseract_cmd = 'D:\\tesseract\\Tesseract-OCR\\tesseract.exe' #若tesseract.exe安装在其他路径下,更改此处的指向路径
keyword = '京东'
headers = {
'Cookie': 'TYCID=e1e6efb0a5fc11e8af04cdd896ab5e5e; undefined=e1e6efb0a5fc11e8af04cdd896ab5e5e; ssuid=2739512828; _ga=GA1.2.1428665082.1536072517; RTYCID=1af95e55a4b54a88b4a9e12b0b316891; CT_TYCID=1e54f2e7bb7745f29ad8e0ef03c6de89; aliyungf_tc=AQAAABsd5kD4dgQAaMuedVOeS5fIGX2P; csrfToken=-l3eED3CM_gh3kqdYWzTNOCP; jsid=SEM-BAIDU-CG-SY-000700; tyc-user-info=%257B%2522token%2522%253A%2522eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxMzYwNzY2OTQwNyIsImlhdCI6MTUzOTA0NzY4OSwiZXhwIjoxNTU0NTk5Njg5fQ.xnOALGRt-xDfQwjKK2ha-srf9acGAKX2knmeaxJeLhk6ejWn-5uRF2iVRowGFnUwEUFtYSArvJwGnlxUnwDMdA%2522%252C%2522integrity%2522%253A%25220%2525%2522%252C%2522state%2522%253A%25220%2522%252C%2522redPoint%2522%253A%25220%2522%252C%2522vipManager%2522%253A%25220%2522%252C%2522vnum%2522%253A%25220%2522%252C%2522monitorUnreadCount%2522%253A%25221%2522%252C%2522onum%2522%253A%25220%2522%252C%2522mobile%2522%253A%252213607669407%2522%257D; auth_token=eyJhbGciOiJIUzUxMiJ9.eyJzdWIiOiIxMzYwNzY2OTQwNyIsImlhdCI6MTUzOTA0NzY4OSwiZXhwIjoxNTU0NTk5Njg5fQ.xnOALGRt-xDfQwjKK2ha-srf9acGAKX2knmeaxJeLhk6ejWn-5uRF2iVRowGFnUwEUFtYSArvJwGnlxUnwDMdA; Hm_lvt_e92c8d65d92d534b0fc290df538b4758=1539004455,1539047679,1539055612,1539070815; Hm_lpvt_e92c8d65d92d534b0fc290df538b4758=1539070858; cloud_token=485d7821a19942fd9263c43cd7583486; bannerFlag=true',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Host': 'www.tianyancha.com'}
Map_Dict={}
def get_list_page(page_num):
'''
请求列表页,提取企业详情页地址
:param page_num: 页码
:return:
'''
list_url = 'https://www.tianyancha.com/search/p{}?key={}'.format(page_num, keyword)
response = requests.get(list_url, headers=headers)
return response.text
def parse_list_page(list_page_source):
'''
根据列表页源代码,提取detail_url
:param list_page_source: 列表页源代码
:return:
'''
obj = etree.HTML(list_page_source, parser=etree.HTMLParser(encoding='utf8'))
divs = obj.cssselect('div.search-result-single')
for div in divs:
detail_url = div.cssselect('a.name')[0].attrib['href']
# 请求详情页地址
data_tuple = get_detail_page(detail_url)
parse_detail_page(data_tuple)
def get_detail_page(detail_url):
'''
请求详情页,获取源代码
:param detail_url: 详情页地址
:return:
'''
response = requests.get(detail_url, headers=headers)
return response.text, detail_url
def parse_detail_page(data_tuple):
'''
解析详情页,提取字体文件中的id(/2d/2df8ui),并提取公司的核准日期。
问题一:如何解决已经解析过的字体文件不用重复解析?如果是解析过的,直接使用映射字典,不用再进行图片识别了。如果是没有解析过的字体文件,再进行图片识别。
方案:声明一个字典,将解析过的字体id都存入列表中,等到后续获取字体id的时候,和字典中的id进行比对,查询是否存在这个id,如果已经存在,直接将映射字典取出。
{'2df8ui':{'1':'2'},'b64s4f':{'1':'3'}}
每一个id对应的映射字典是否保留?还是说只保留最新的id映射规则?
都保留,避免刷新到以前的id时再重新解析一遍。
:param data_tuple:get_detail_page()这个函数返回的元组。
:return:
'''
detail_page_source = data_tuple[0]
detail_url = data_tuple[1]
obj = etree.HTML(detail_page_source, parser=etree.HTMLParser(encoding='utf8'))
# 在详情页中提取字体id
pattern = re.compile(
r'.*?', re.S)
font_id = re.search(pattern, detail_page_source).group(1)
#在获取font_id以后,先判断Map_Dict中是否存在这个键,不存在再去调用parse_map_rule()
if font_id not in Map_Dict:
map_dic=parse_map_rule(font_id)
else:
map_dic=Map_Dict[font_id]
#根据映射字典转换核准日期
try:
hezhunriqi=obj.xpath('//td[@colspan="2"]/text[contains(@class,"tyc-num")]/text()')[0]
name=obj.xpath('//h1[@class="name"]/text()')[0]
result=''
for char in hezhunriqi:
if char !='-':
real_num=map_dic[char]
result+=real_num
else:
result+='-'
print(name,detail_url,result)
except:
pass
def parse_map_rule(font_id):
'''
根据字体id,拼接woff字体文件,并对字体进行识别,最终将字体id和映射字典保存到一个全局字典中。
:param font_id:
:return:
'''
font_url='https://static.tianyancha.com/fonts-styles/fonts/{}/tyc-num.woff'.format(font_id)
content = requests.get(font_url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}).content
with open('tyc.woff', 'wb')as f:
f.write(content)
# 先定义位置数字
position_number = ['1', '2', '3', '4', '5', '6', '7', '8', '9', '0']
map_dict = {}
for p_num in position_number:
# 创建一个图片对象,用于后续数字图片的存储
#(255,255,100) :RGB red/green/blue 三原色,每一种颜色的取值范围都是(0,255)
#三个参数:图片模式 图片的尺寸,图片的背景颜色
img = Image.new('RGB', (300, 500), (255, 255, 100))
draw = ImageDraw.Draw(img)
#根据位置数字p_num和字体文件woff,找出p_num在woff文件中的真实映射关系
# 参数1:指定字体文件
# 参数2:指定数字在画布上展示的大小
# truetype()返回一个字体对象
font = ImageFont.truetype('tyc.woff', 400)
draw.text((10, 10), text=p_num, font=font, fill=ImageColor.getcolor('green', 'RGB'))
img.save('tyc.png')
#利用pytesseract包识别图片中的数字
#pip install pytesseract
font_image = Image.open('tyc.png')
num = pytesseract.image_to_string(font_image, config='--psm 6')
if num == 'A' or num == '/':
num = pytesseract.image_to_string(font_image, config='--psm 8')
map_dict[p_num] = num
elif num == '':
map_dict[p_num] = p_num
else:
map_dict[p_num] = num
#有的字体文件中是缺少部分数字的,那么得到的图片就是一个空白的图片,也就是位置数字对应的真实数字不存在、
#凡是真实数字不存在的,都有一个特征:就是位置数字和真实数字是相等的。
Map_Dict[font_id]=map_dict
return map_dict
if __name__ == '__main__':
for x in range(1,6):
response=get_list_page(x)
parse_list_page(response)
此前先要安装载tesseract.exe的安装包。下载地址:https://digi.bib.uni-mannheim.de/tesseract/

这里仅获取了核准日期,注册资本和注册时间虽然也是加密的,可以在列表页进行获取(此时没有加密)。其它的原理上差不多。