Hadoop集群安装报告
去年选修了《网络大数据处理理论与实践》课程,本篇博客记录一下当时的安装过程。
安装教程来自:
http://www.powerxing.com/install-hadoop-cluster/
http://xixici.com/2016/07/18/spark-cookbook/
环境及所需软件说明
1) Ubuntu 14.04 x64(VMware 12.0虚拟机2台, Master:162.105.85.167 Slave1:162.105.85.184, 一个是master节点,一个是slave节点,必须在同一局域网内)
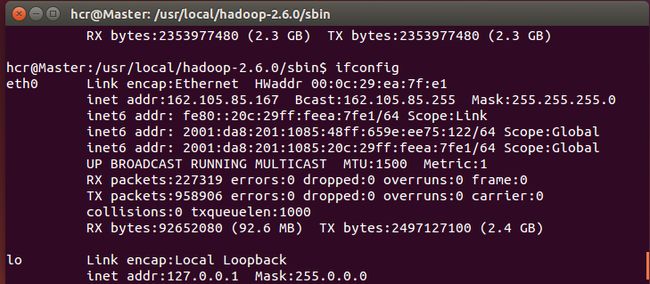
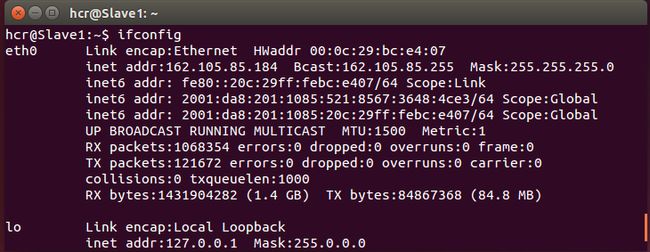
1) Hadoop 2.6.0
2) Java 1.8.0
3) Spark 1.6.2
4) Scala 2.10.6
5) Eclipse 4.4.2
Tips:不要求系统、软件版本等完全一致,但是注意Hadoop、Spark、Scala及其Eclipse插件等有一定搭配要求,最好去官网查查requirements里有没有说明。现在hadoop等都更新很多代了,但是这里建议的几个版本是目前网上教程和QA最多的,出现问题相对来说比较好解决一些。
Hadoop 集群的安装配置大致为如下流程:
- 选定一台机器作为 Master
- 在 Master 节点上安装 SSH server、安装 Java 环境
- 在 Master 节点上安装 Hadoop,并完成配置
- 在其他 Slave 节点上安装 SSH server、安装 Java 环境
- 将 Master 节点上的 /usr/local/Hadoop-2.6.0 目录复制到其他 Slave 节点上
- 在 Master 节点上开启 Hadoop
安装流程
一、 集群配置
配置伪分布式的话,只需要1台机器即可。如果配置集群的话,需要至少两台能连通的机器。如果没有2台实体机的话,可以采取如下方案:
2台虚拟机。更改网络连接方式为桥接(Bridge)模式,宿主机采用有线网卡的话,那么虚拟机可以自动分配IP(和宿主机在同一网段),也可以固定IP。
两台虚拟机的硬件设置——供参考:我的Master内存设置为3G(Spark的Master需要大量内存,内存不足会报错,尽量设2G以上,或者等报错再调也行),Slave内存设置为1.5G。
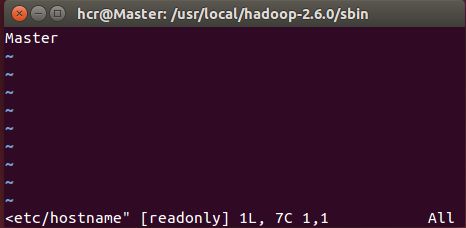
(1)修改主机名称
在Master主机上,
sudo vim /etc/hostname,将localhost改为Master
sudo vim /etc/hosts, 将127.0.0.1对应的localhost改为Master
Slave1主机同理

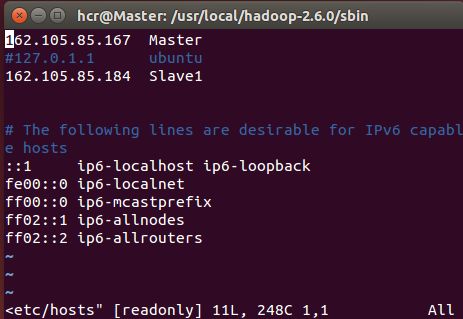

(2)配置hosts文件
在master主机的/etc/hosts文件中新加一行: 192.168.1.107 Slave1
在slave1主机的/etc/hosts文件中新加一行: 192.168.1.109 Master
(3)没有ssh server的安装ssh server(ubuntu 14.04默认没安装)
安装:sudo apt-get install openssh-server
输入命令ssh localhost,若提示“The authenticity of host 'localhost (127.0.0.1)' can't beestablished.”(首次登录提示)则说明安装成功。
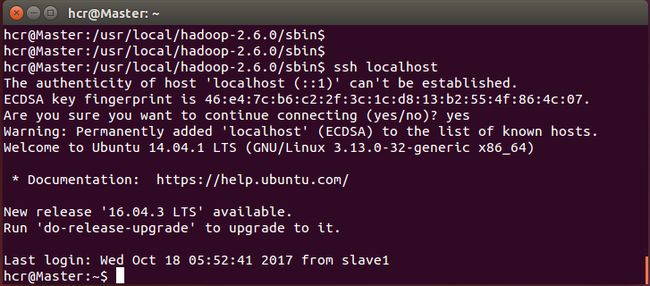
(4)配置ssh免密登录
这个操作是要让 Master和各个Slave 节点可以无密码互相SSH 登陆到对方节点上。下面以Master为例,Slave同理。
在Master上输入如下命令:
cd ~/.ssh (若提示不存在,就mkdir ~/.ssh即可)
ssh-keygen -trsa (然后一直按回车)
cat ./id_rsa.pub>> ./authorized_keys (让Master能够登录Master本机)
ssh-copy-id -i ~/.ssh/id_rsa.pub chjtan@Slave1 (将公钥传送到Slave1, chjtan是Slave1的用户名)
接着ssh chjtan@Slave1,若能免密直接登录,说明配置成功。
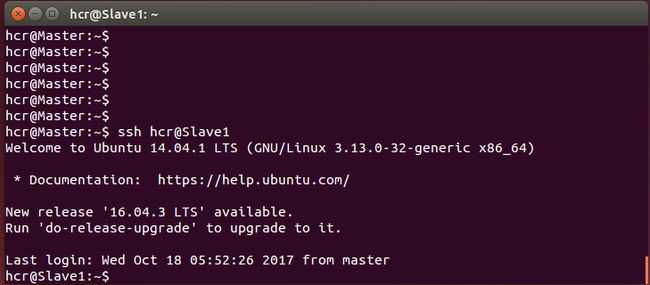
二、 Java环境配置
(1)将jdk-8u60-linux-x64.tar.gz解压到/opt/java/目录下
sudo tar -zxvf your_path/jdk-8u60-linux-x64.tar.gz–C /opt/java
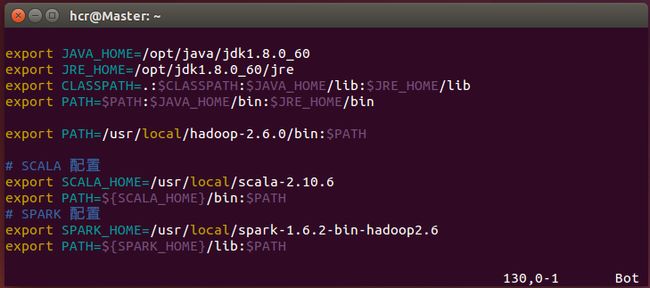
(2)配置环境变量
sudo vim ~/.bashrc, 在末尾另起一行输入如下内容:
export JAVA_HOME=/opt/java/jdk1.8.0_60
export JRE_HOME=/opt/jdk1.8.0_60/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source ~/.bashrc (使上述配置生效)
java –version,如果显示java version"1.8.0_60"….则说明配置成功

三、 Hadoop集群安装
(1)解压文件
sudo tar -zxvf your_path/hadoop-2.6.0.tar.gz-C /usr/local/

(2)配置环境变量
vim ~/.bashrc
exportPATH=/usr/local/hadoop-2.6.0/bin:$PATH
source ~/.bashrc
输入hadoopversion若正常显示版本,则配置成功

(3)更改hadoop三个文件的java环境
在Master执行如下命令来修改权限(除了下列编辑文件,后面执行命令时也有很多地方需要权限,直接改了):
sudo chown -R chjtan:chjtan/usr/local/hadoop-2.6.0/

cd /usr/local/hadoop-2.6.0/etc/hadoop
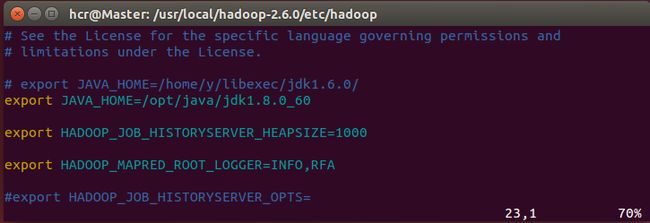
修改hadoop-env.sh中的export JAVA_HOME=${JAVA_HOME}如下:
export JAVA_HOME=/opt/java/jdk1.8.0_60
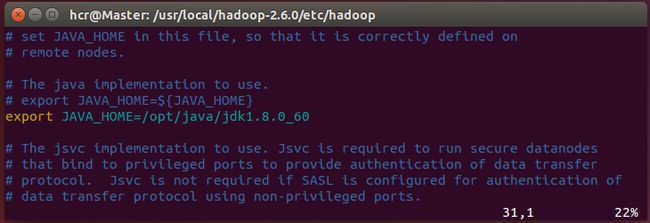
修改yarn-env.sh中的# exportJAVA_HOME=/home/y/libexec/jdk1.6.0/如下:
export JAVA_HOME=/opt/java/jdk1.8.0_60

修改mapred-env.sh中的# exportJAVA_HOME=/home/y/libexec/jdk1.6.0/如下:
export JAVA_HOME=/opt/java/jdk1.8.0_60
(4)hadoop配置修改
cd /usr/local/hadoop-2.6.0/etc/hadoop
vim slaves,删除原来的localhost,并且添加两行,分别是Master和Slave1(根据前面的配置,Master同时作为NameNode和DataNode)
vim core-site.xml, 修改为如下:

vim hdfs-site.xml, 修改configuration为如下(其中dfs.replication表示有两个slave节点——根据前面设置Master也作为DataNode):

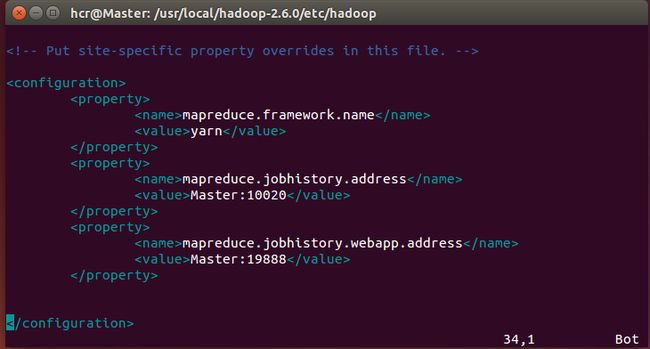
cp mapred-site.xml.template mapred-site.xml&& vim mapred-site.xml, 修改为如下:
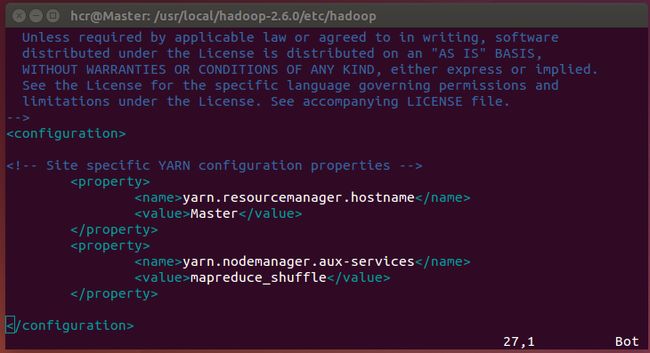
vim yarn-site.xml,修改为如下:
配置好后,将 Master 上的 /usr/local/hadoop-2.6.0 文件夹复制到各个节点上。
在Master和各个Slave节点上均执行如下命令来修改权限,以免后面操作遇到权限问题:
sudochown -R chjtan:chjtan /usr/local/hadoop-2.6.0/

四、 测试
首次启动需要在Master节点下完成NameNode的初始化,在Master输入如下命令:
hdfs namenode -format
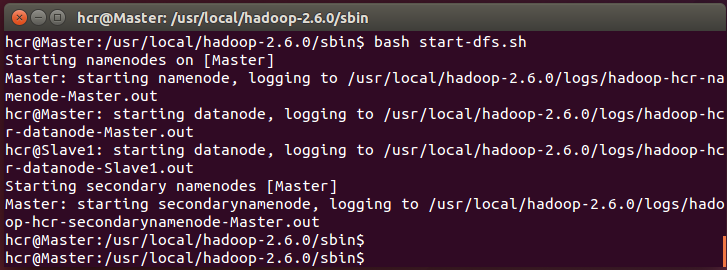
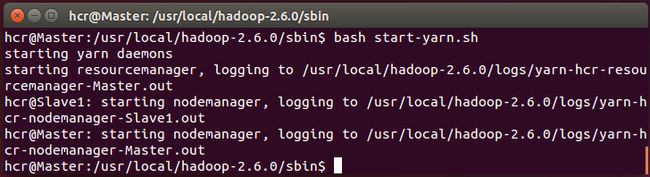
启动 hadoop ,启动需要在 Master 节点上执行如下几个命令:
cd /usr/local/hadoop-2.6.0/sbin
bash start-dfs.sh (注意,ubuntu 14.04版本中,sh命令默认指向dash,使用dash命令执行会报错,也可以将sh默认指向改为bash,然后用sh命令)
bash start-yarn.sh
bash mr-jobhistory-daemon.sh starthistoryserver
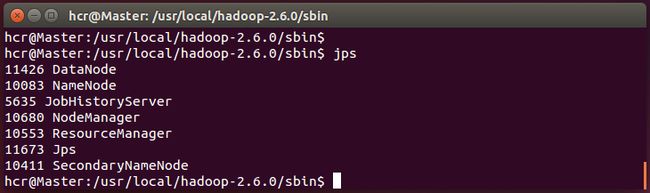
输入jps命令,可以查看各个节点所启动的进程。
正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
在 Slave 节点可以看到 DataNode 和 NodeManager 进程,如下图所示:

还可以通过Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/
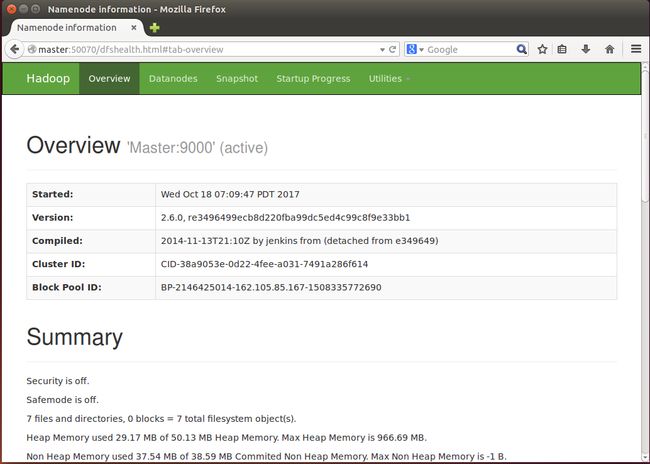
Tips:
如果碰到什么问题不好解决,想要重头开始做的话,把Master和Slave相关进程全部关了,直接删除Master和Slave的hadoop-2.6.0/tmp即可。
五、 配置Eclipse的Hadoop插件
安装Eclipse不多说了,直接下载解压就可以用,我的eclipse目录在/opt/eclipse。
(1)将hadoop-eclipse-plugin-2.6.0.jar复制到eclipse的plugin目录下:
sudo cp your_path/hadoop-eclipse-plugin-2.6.0.jar/opt/eclipse/plugins/
重启Eclipse生效。
如果hadoop版本不是2.6.0的话:这里https://github.com/winghc/hadoop2x-eclipse-plugin/tree/master/release有人已经编译好了几个版本hadoop的插件,如果是其他版本的hadoop,需要自行编译插件,参见http://www.cnblogs.com/myresearch/p/hadoop-eclipse-plugin-jar.html)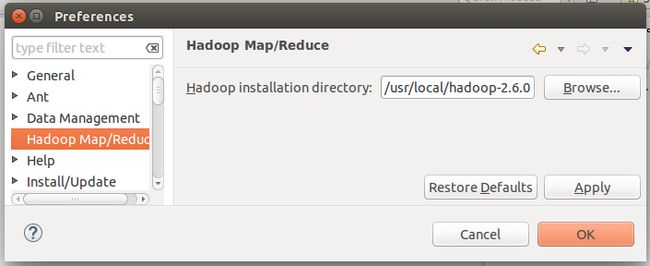
(2)配置 hadoop 安装目录
window ->preference -> hadoopMap/Reduce -> Hadoop installation
directory:/usr/local/hadoop-2.6.0/ -> 点击“OK”
(3) 配置Map/Reduce 视图
window ->Open Perspective ->Map/Reduce -> 点击“OK”
window ->Show View -> 搜索“map/reduce Locations”视图 选上 -> 点击“OK”
在eclipse下方就出现了一个“Map/Reduce Locations选项卡”-> 空白地方右键 选“New
Hadoop Location”,按如下方框配置:

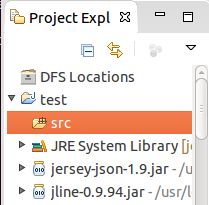
(4)在左边project explorer 列表框中找到“DFS Locations”右键refresh,就会看到
一个目录树,eclipse提供了一个目录树来管理HDFS系统,右键可以创建/删除目录,上传/
查看文件,操作起来很简单,内容与命令 hadoop fs -ls 结果一致
(5)新建Map/Reduce程序
File->New->project->Map/ReduceProject->Next
Project name:example ->Next->Finish-> src右键->New->class
Name:example->Finish -> 左侧窗口就显示一个example.java 类文件了
六、 Hadoop做Word Count
关键代码:

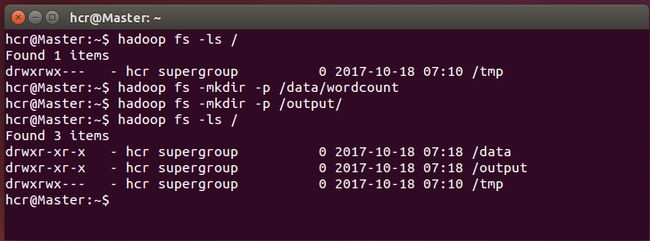
建立输入输出文件夹:
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output/
复制所需文件到data文件夹:
hadoop fs -put ./WordCount /data/wordcount/
查看HDFS的内容:
http://Master:50070/explorer.html#/
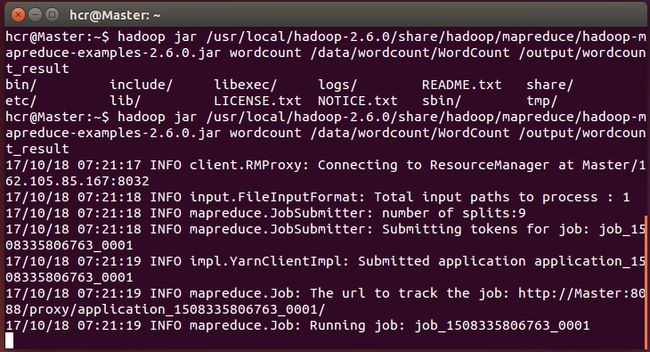
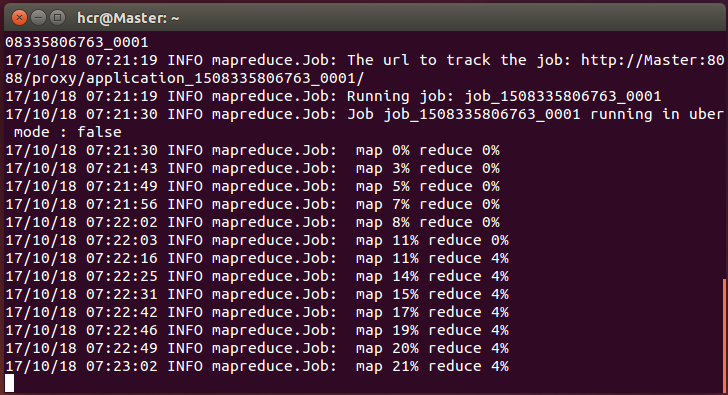
执行wordcount 的mapreduce命令:
hadoop jar../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /data/wordcount/WordCount_Small/output/wordcount_result