通过freemarker出word的技术解决方案
通过freemarker制作word比较简单
步骤:制作word模板。制作方式是:将模板word保存成为xml----在xml的word模板中添加相应的标记----将xml的word文件的后缀名改成ftl文件
详细步骤如下:
模板制作(将要动态显示的数据打上标记,这个标记是freemarker中的EL标记,要注意的是,要控制值为空的情况,下面${(site.wzmc)?default(“”)}标识当网站名称为空的时候显示空值,如果这里如果不做控制,在实际项目中会显示错误!)
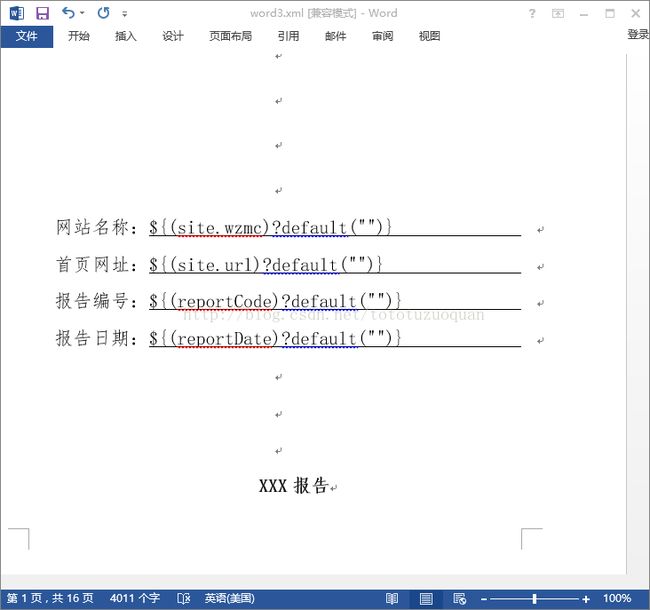
另外要注意的是:
一、不要直接在word中替换掉文字的方式添加标记,这种会有问题。
二、不要使用Eclipse对xml文件进行格式化,这种生成word的时候会提示文档有问题。解决这个的问题是通过firstobject对word的xml进行格式化,对xml进行编辑。(使用firstobject打开带有中文文件名的xml文件的时候,会出现问题,建议使用英文word文档名称)
三、firstobject下载地址:http://www.firstobject.com/dn_editor.htm
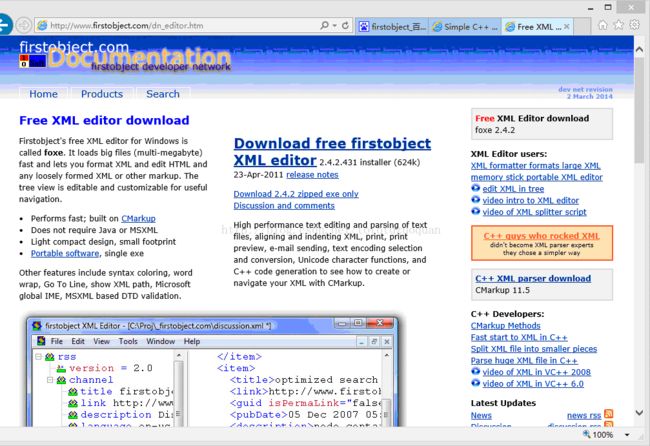
其中,要想软件能够格式化xml代码,需要进行设置,设置方式是:打开firstobject----Tools-----Preferences------Format-----Tabs
点击Indent,结果xml变成了有格式化的,效果图如下:
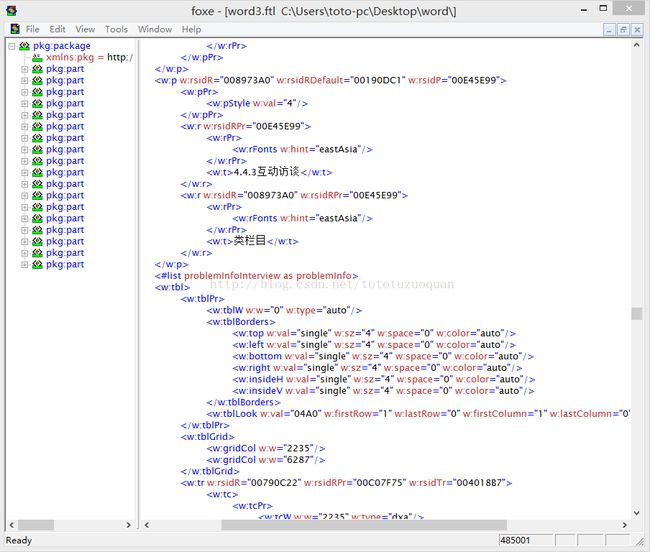
常见标签:
行标记:
标识是一个表格的标签
表格行:
表格中的单元格:
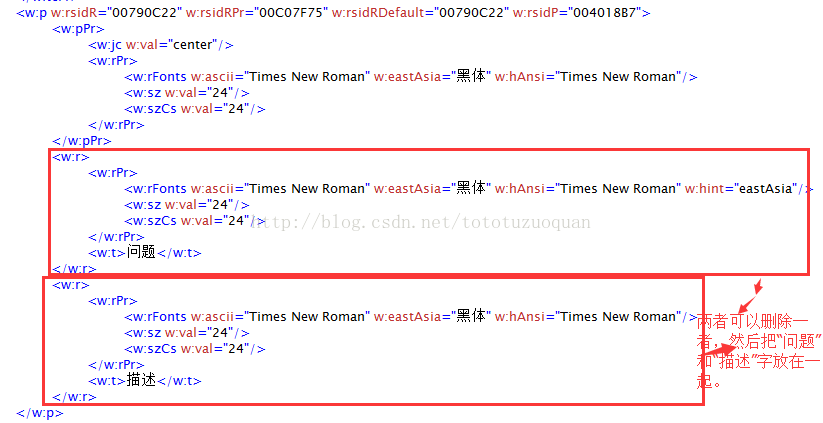
循环输出数据的方式
<#list problemInfoInterview as problemInfo>
w:hAnsi="Times New Roman" w:hint="eastAsia" />
这里面的行删除
|
另外,往文档中插入图片的时候,在做模板的时候要往模板中插入一个图片,然后打开文档,然后替换掉base64转码的图片部分。
将图片资源变成base64加密后的图片的代码
将图片转成base64串的方式:
public static String getImageString(String fileName) throws IOException { InputStream in = null; byte[] data = null; try { in = new FileInputStream(fileName); data = new byte[in.available()]; in.read(data); in.close(); } catch (Exception e) { e.printStackTrace(); } finally { if (in != null){ in.close(); } } Base64Encoder encoder = new Base64Encoder(); return data != null ? encoder.encode(data) : ""; } |
下面是出word用的相关的类:
读取路径用的TemplateUtil工具类
package com.ucap.netcheck.utils;
import java.io.File; import java.io.FileInputStream; import java.net.URL; import java.util.Properties;
/** * @Title: TemplateUtil.java * @Package com.ucap.netcheck.utils * @Description: * @author * @date 2015-4-13 下午9:07:58 * @version V1.0 */ public class TemplateUtil { // 模板所在的位置 public static String reportTemplatePath; // 模板的名称 public static String templateFileName;
static { URL resource = TemplateUtil.class.getClassLoader().getResource("template.properties"); System.out.println(resource.getPath());
File file = new File(resource.getPath()); //生成文件输入流 FileInputStream in = null; try { in = new FileInputStream(file); } catch (Exception e) { e.printStackTrace(); }
//生成properties对象 Properties prop = new Properties(); try { prop.load(in); } catch (Exception e) { e.printStackTrace(); }
reportTemplatePath = prop.getProperty("reportTemplatePath"); templateFileName = prop.getProperty("templateFileName"); }
/*public static void main(String[] args) { System.out.println(TemplateUtil.reportTemplatePath); }*/ } |
配置文件路径截图:
FreeMarkerUtil工具类
package com.ucap.netcheck.utils;
import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStreamWriter; import java.io.Writer; import java.util.HashMap; import java.util.Map;
import com.thoughtworks.xstream.core.util.Base64Encoder;
import freemarker.template.Configuration; import freemarker.template.Template;
/** * @Title: FreeMarkerUtil.java * @Package com.ucap.netcheck.utils * @Description: FreeMarker工具类 * @author Zuoquan Tu * @date 2015-4-5 下午6:02:11 * @version V1.0 */ public class FreeMarkerUtil { private static Configuration configuration = null; private static Map
static { configuration = new Configuration(); configuration.setDefaultEncoding("utf-8"); //configuration.setClassForTemplateLoading(FreeMarkerUtil.class, // "../template");
try { configuration.setDirectoryForTemplateLoading( new File(TemplateUtil.reportTemplatePath)); } catch (IOException e1) { e1.printStackTrace(); } allTemplates = new HashMap try { allTemplates.put("word",configuration.getTemplate(TemplateUtil.templateFileName)); } catch (Exception e) { e.printStackTrace(); throw new RuntimeException(e); } }
public FreeMarkerUtil() {
}
public static File createDoc(Map dataMap,String type){ String name = "temp" + (int) (Math.random() * 100000) + ".doc"; File f = new File(name); Template t = allTemplates.get(type); try { // 这个地方不能使用FileWriter因为需要指定编码类型否则生成的Word //文档会因为有无法识别的编码而无法打开 Writer w = new OutputStreamWriter(new FileOutputStream(f),"utf-8"); t.process(dataMap, w); w.close(); } catch (Exception ex) { ex.printStackTrace(); throw new RuntimeException(); } return f; }
public static String getImageString(String fileName) throws IOException { InputStream in = null; byte[] data = null; try { in = new FileInputStream(fileName); data = new byte[in.available()]; in.read(data); in.close(); } catch (Exception e) { e.printStackTrace(); } finally { if (in != null){ in.close(); } } Base64Encoder encoder = new Base64Encoder(); return data != null ? encoder.encode(data) : ""; } } |
出Word的Controller层的代码,并解决出word时中文文件名乱码的问题
package com.ucap.netcheck.controller;
import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.net.URLEncoder; import java.util.Map;
import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse;
import org.apache.commons.lang.StringUtils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod;
import com.ucap.netcheck.entity.Site; import com.ucap.netcheck.entity.User; import com.ucap.netcheck.service.IReport2WordService; import com.ucap.netcheck.service.ISiteService; import com.ucap.netcheck.utils.DateUtil; import com.ucap.netcheck.utils.FreeMarkerUtil;
/** * @Title: Report2WordController.java * @Package com.ucap.netcheck.controller * @Description: 生成word部分的Controller * @author Zuoquan Tu * @date 2015-4-12 上午9:36:43 * @version V1.0 */ @Controller @RequestMapping(value = "/reportToWord", method = { RequestMethod.GET, RequestMethod.POST }) public class Report2WordController {
@Autowired private IReport2WordService report2WordService; @Autowired private ISiteService siteService;
@RequestMapping(value = "/word") public String outWord(Model model, HttpServletRequest request, HttpServletResponse response) throws Exception { request.setCharacterEncoding("utf-8");
// 获取innerUUID,taskId String siteCode = request.getParameter("innerUUID"); // 获取taskId Integer taskId = Integer.parseInt(request.getParameter("taskId")); // 获取用户的userId User user = (User) request.getSession().getAttribute("user"); // 通过下面的方式获得模板的参数 Site site = siteService.findSite(siteCode); String webSiteName = site.getWzmc(); Map taskId, user.getId());
// 获取innerUUID,taskId // Map
// 获取innerUUID,taskId // Map // map.put("taskNum", "测试"); // map.put("tackRunNum", "测试2……rqwrqw"); // String imageStr = new FreeMarkerUtil().getImageString("D:/1.png"); // map.put("imgStr", imageStr); // // List // for (int i = 0; i < 10; i++) { // CheckService checkService = new CheckService(); // checkService.setTaskRunNum(10); // checkService.setTaskNum(1000); // newsList.add(checkService); // } // map.put("newList", newsList);
this.generateWord(request,response, map, webSiteName);
return null; }
@SuppressWarnings("static-access") private void generateWord(HttpServletRequest request,HttpServletResponse response, Map throws FileNotFoundException, IOException { File file = null; InputStream fin = null; ServletOutputStream out = null; try { // 调用工具类WordGenerator的createDoc方法生成Word文档 file = new FreeMarkerUtil().createDoc(map, "word"); fin = new FileInputStream(file); response.setCharacterEncoding("utf-8"); response.setContentType("application/msword"); // 设置浏览器以下载的方式处理该文件默认名为下面的文件,按照时间来生成的一个文件名称 String longMsDateStr = DateUtil.getStringLongMsDate(); String fileName = webSiteName + "_" + longMsDateStr + ".doc"; //设置下载用的文件名 setFileDownloadHeader(request, response, fileName); //response.addHeader("Content-Disposition", "attachment;filename=" + fileName);
out = response.getOutputStream(); byte[] buffer = new byte[512]; int bytesToRead = -1;
// 通过循环将读入的Word文件的内容输出到浏览器中 while ((bytesToRead = fin.read(buffer)) != -1) { out.write(buffer, 0, bytesToRead); } } finally { if (fin != null) fin.close(); if (out != null) out.close(); if (file != null) file.delete(); // 删除临时文件 } }
/** * 根据当前用户的浏览器不同,对文件的名字进行不同的编码设置, 从而解决不同浏览器下文件名中文乱码问题 */ public static void setFileDownloadHeader(HttpServletRequest request, HttpServletResponse response, String fileName) { final String userAgent = request.getHeader("USER-AGENT"); try { String finalFileName = null; if (StringUtils.contains(userAgent, "MSIE")) { // IE浏览器 finalFileName = URLEncoder.encode(fileName, "UTF8"); } else if (StringUtils.contains(userAgent, "Mozilla")) { // google,火狐浏览器 finalFileName = new String(fileName.getBytes(), "ISO8859-1"); } else { // 其他浏览器 finalFileName = URLEncoder.encode(fileName, "UTF8"); }
//这里设置一下让浏览器弹出下载提示框,而不是直接在浏览器中打开 response.setHeader("Content-Disposition", "attachment; filename=\"" + finalFileName + "\""); } catch (Exception e) { e.printStackTrace(); } } } |
ServiceImpl层的实现类
package com.ucap.netcheck.service.impl;
import java.text.NumberFormat; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;
import com.ucap.netcheck.combination.beans.TargetTypeParentToChildBean; import com.ucap.netcheck.dao.IReport2WordDao; import com.ucap.netcheck.entity.CheckService; import com.ucap.netcheck.entity.MainPageScanFail; import com.ucap.netcheck.entity.MainPageScanResult; import com.ucap.netcheck.entity.ProblemInfo; import com.ucap.netcheck.entity.Site; import com.ucap.netcheck.entity.SiteService; import com.ucap.netcheck.service.CheckServiceService; import com.ucap.netcheck.service.IReport2WordService; import com.ucap.netcheck.service.ISingleRejectResultService; import com.ucap.netcheck.service.ISiteService; import com.ucap.netcheck.service.SiteServService; import com.ucap.netcheck.service.TargetTypeService; import com.ucap.netcheck.utils.DateUtil;
/** * @Title: Report2WordServiceImpl.java * @Package com.ucap.netcheck.service.impl * @Description: * @author * @date 2015-4-12 上午11:58:09 * @version V1.0 */ @Service public class Report2WordServiceImpl implements IReport2WordService {
@Autowired private ISiteService siteService; @Autowired private CheckServiceService checkServiceService; @Autowired private IReport2WordDao report2WordDao; @Autowired private TargetTypeService targetTypeService; @Autowired private ISingleRejectResultService singleRejectResultService; @Autowired private SiteServService siteServService;
/** * generateWordData(通过这个方法获得生成报告所需的数据) * * @Title: generateWordData * @Description: 通过这个方法获得生成报告所需的数据 * @param @return 返回所需的数据 * @return Map * @throws */ @Override public Map String siteCode,Integer taskId,String userId) { Map //网站名称,首页网址,报告编号,报告日期 Site site = siteService.findSite(siteCode); map.put("site", site); //生成报告编号和报告日期 map.put("reportCode", DateUtil.getNowDateStr() + "_" + taskId); map.put("reportDate", DateUtil.getYearMonthAndDay());
//检查方法的数据,获得CheckService的值 //通过siteCode查找site_service SiteService siteService = siteServService.findSiteService(siteCode); CheckService checkService = report2WordDao.findCheckService(siteService.getServId()); map.put("checkService", checkService); //设置开通时间的日期 map.put("checkServiceOpenTime", DateUtil.dateToStr(checkService.getOpenTime())); //设置结束时间的日期 map.put("checkServiceCloseTime", DateUtil.dateToStr(checkService.getCloseTime()));
//问题统计部分的数据 List targetTypeService.getTargetTypeByParentId(siteCode, taskId); map.put("targetTypeBeanStatistics", targetTypeBeanStatistics);
//---------------------------------------------------------------------------------- //单项否决部分的问题 //获取站点无法访问的数据,获取单项否决权的数据 //下面是单项否决部分的代码 MainPageScanResult mainPageScanResult = singleRejectResultService.queryMainPageScanResultUnique(siteCode,taskId); map.put("mainPageScanResult", mainPageScanResult); if (null != mainPageScanResult && mainPageScanResult.getFailNum() >= 0 && mainPageScanResult.getSuccessNum() >= 0) { NumberFormat format = NumberFormat.getNumberInstance(); format.setMaximumFractionDigits(2); double rate = mainPageScanResult.getFailNum() / mainPageScanResult.getSuccessNum(); String mainPageFailRateString = format.format(rate); map.put("mainPageFailRateString", mainPageFailRateString); } else { map.put("mainPageFailRateString", ""); }
List if (null != mainPageScanResult) { queryMainPageScanFailList = singleRejectResultService.queryMainPageScanFailListById(mainPageScanResult.getId()); } map.put("queryMainPageScanFailList", queryMainPageScanFailList);
// List // singleRejectResultService.queryMainPageScaneResultByCondition(siteCode,taskId); // map.put("mainPageScanResults", mainPageScanResults);
//获取网站不更新的数据 List map.put("MainPageUpdateInfoLists", MainPageUpdateInfoLists);
//获取栏目不更新 List map.put("problemInfoUnUpdate", problemInfoUnUpdate);
//严重错误 List map.put("problemInfoSeriousError", problemInfoSeriousError);
//互动回应差 List map.put("problemInfoInterAct", problemInfoInterAct);
//---------------------------------------------------------------------------------- //网站可用性 //1、首页可用性 List map.put("problemInfoIndexUsability", problemInfoIndexUsability); // // //连接可用性 // List // map.put("problemInfoLinkUsability", problemInfoLinkUsability);
//----------------------------------------------------------------------------------- //信息更新情况 //首页栏目 List map.put("problemInfoIndexColumn", problemInfoIndexColumn);
//基本信息 List map.put("queryCheckProblemInfoBaseInfo", queryCheckProblemInfoBaseInfo);
//----------------------------------------------------------------------------------- //互动回应情况 //政务咨询类栏目 List map.put("problemInfoGovAdvisory", problemInfoGovAdvisory);
//调查集体类栏目 List map.put("problemInfoSurvey", problemInfoSurvey);
//互动访谈类栏目 List map.put("problemInfoInterview", problemInfoInterview);
//----------------------------------------------------------------------------------- //服务使用情况 //办事指南 List map.put("problemInfoServiceUsedInfo", problemInfoServiceUsedInfo);
//附件下载 List map.put("problemInfoAccessory", problemInfoAccessory);
//在线系统 List map.put("problemInfoOnLineInfo", problemInfoOnLineInfo);
return map; } } |