通用(内核)链表详解
Linux内核中充斥着大量的数据结构,这些数据结构很多都是使用结构体来表示:如cdev结构体用于描述一个字符设备,再如task_struct结构体,是我们所说的进程控制块PCB,用于描述一个进程的所有信息。追寻内核源码我们会发现很多都是表示设备的结构体中都有list_head这样的字段,没错这就是内核链表的节点类型。描述设备的结构体中只要包含这个字段,内核就能通过链表来管理我们的设备,试想浩瀚的内核中有大量不同类型的设备或结构体,如何把他们统一起来进行管理呢?内核链表在这里就立下了汗马功劳,它的设计非常的巧妙,也体现了内核设计者的强大的智慧,下面跟随我的脚步来探寻下内核链表(以下都叫做通用链表)是如何实现的,又是如何管理我们不同类型的结构体的。
首先我们讨论下普通的链表的特点:和数组相比它的节点内存分配可以是不连续的,可以动态的增减节点也就是链表长度可以不固定,但是它的数据域在定义链表节点的时候必须固定,也就是说普通的链表只能维护一条相同的数据类型的节点,如果数据域长度改变必须重新定义链表节点。
内核中由于要管理大量的设备,但是各种设备各不相同,必须将他们统一起来管理,于是内核设计者就想到了使用通用链表来处理,通用链表看似神秘,实际上就是双向循环链表,这个链表的每个节点都是只有指针域,没有任何数据域。

图1 普通的单链表
使用通用链表的好处是:1.通用链表中每个节点中没有数据域,也就是说无论数据结构有多复杂在链表中只有前后级指针。2.如果一个数据结构(即是描述设备的设备结构体)想要用通用链表管理,只需要在结构体中包含节点的字段即可。3.双向链表可以从任意一个节点的前后遍历整个链表,遍历非常方便。4.使用循环链表使得可以不断地循环遍历管理节点,像进程的调度:操作系统会把就绪的进程放在一个管理进程的就绪队列的通用链表中管理起来,循环不断地,为他们分配时间片,获得cpu进行周而复始的进程调度。
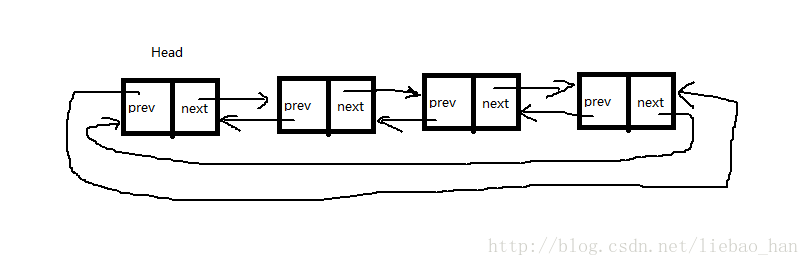
图2 通用链表
有了这些理论的东西,下面我们来实现一下通用链表,并使用它来管理一个学生信息的结构体。其他类型的任何结构体管理亦是如此。我们会把主要的注释放在程序代码中,结合图示来进行阐述。
以下是list_head.h文件,描述通用链表的节点类型和操作函数的声明。
#ifndef __LIST_HEAD_H__
#define __LIST_HEAD_H__
//通用链表节点类型 双向链表
struct list_head{
struct list_head *prev; //前级指针
struct list_head *next;//后级指针
};
void INIT_LIST_HEAD(struct list_head *list);//初始化通用链表
void list_add(struct list_head *node,struct list_head *head);//插入节点
void list_add_tail(struct list_head *node,struct list_head *head);//尾插
void list_del(struct list_head *node);//删除节点
/*遍历链表 依次为:从头节点的下一个节点开始遍历
* 从头节点的上一个节点开始遍历
*(以list_for_next_each为例理解:首先节点指针pos指向头节点的下一个节点,判断 pos是否指向头节点,不是的话就向后继续遍历)
*/
#define list_for_next_each(pos,head)\for(pos=(head)->next;pos!=(head);pos=pos->next)#define list_for_prev_each(pos,head)\for(pos=(head)->prev;pos!=(head);pos=pos->prev)
//提取数据结构 ptr 是链接因子的指针 type是包含了链接因子的数据类型 member是链接因子成员名#define container_of(ptr,type,member)\
(type *)( (int)ptr - (int)(&((type *)0)->member) )
#endif通用链表需要解决的就是如何通过链表节点的指针得到设备结构体的首地址,只有得到了设备结构体的首地址才能拿到结构体中的所有成员,这也是通用链表的核心算法,实现理解起来稍微有点难度,但是只要感悟出来,也并无那么难。下面画图讲解container_of的实现:(可以发现是通过偏移量来求得首地址的,设备结构体一旦分配空间在内存中就有了一块区域,链接因子list也就有了地址,使用对0地址的强转为设备结构体指针的类型,能够找到0地址中的链接因子的地址,通过两个链接因子的差值,当然这里将地址强转为int型,不然差值是指向数据的个数,这样就能得到我们想要的首地址了)。
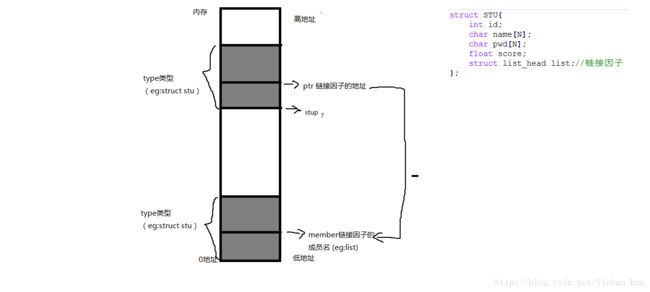
图3 container_of的理解图
以下是list_head.c文件,是操作函数的实现。
#include "list_head.h"
void INIT_LIST_HEAD(struct list_head *list)//初始化通用链表
{
//前后级指针都指向本身
list->next=list;
list->prev=list;
}
void list_add(struct list_head *node,struct list_head *head)//插入节点
{
node->next=head->next;
node->prev=head;
head->next->prev=node;
head->next=node;
}
void list_add_tail(struct list_head *node,struct list_head *head)//尾插
{
node->next=head->prev;
node->prev=head;
head->prev->next=node;
head->prev=node;
}
void list_del(struct list_head *node)//删除节点
{
node->prev->next=node->next;
node->next->prev=node->prev;
}

图4 通用链表的头尾插

图5 通用链表的节点删除
以下是stu.h文件,描述设备信息的结构体定义。
#ifndef __STU_H__
#define __STU_H__
#define N 32
#include "list_head.h"
struct STU{
int id;
char name[N];
char pwd[N];
float score;
struct list_head list;//链接因子
};
#endif以下是test.c文件,用于测试我们的通用链表。
#include 以下是简单的makefile, 利用make的隐含规则,使得makefile非常简单:
test:list_head.o test.o
.PHONY:clean
clean:
rm -rf test *.o最后是执行结果:

以上是本人对于内核链表的理解,内核中的许多思想和算法值得我们去学习应用,如内核的统一性、面向对象的思想、分层的思想、分离的思想等等。内核中最核心也是最有魅力的莫过于算法,而C语言的魅力所在也就是它对于指针的灵活应用,使得他能够去操作硬件,表示许多复杂的数据结构。通用链表也不过是向我们提供了一种统一不同设备结构体的算法而已。本文就说到这,对于文中如有不足之处,望提出宝贵意见!