xxljob从入门到精通-全网段最全解说
XXL-JOB特性一览
基本概念
xxljob解决的是以下几个痛点:
1) 跑批处理监控无法可视化,当前跑批的状态是:成功?失败?挂起?进度?为什么失败/原因?
2)批处理任务不可重用,特别是无法对批处理任务做:定时?重复使用?频次?其中路由调度?
3)批处理任务无法做到网格计算(特别像:websphere ibm grid computing)即批处理任务本身可以做成集群、fail over、sharding
由其是批处理任务可以做成“网格计算”这个功能,有了xxljob后你会发觉特别强大。其实网格计算:grid computing早在7,8年前就已经被提出过,我在《IBM网格计算与企业批处理任务架构》一文中详细有过介绍。
我们在一些项目中如:银行、保险、零商业门店系统中的对帐、结帐、核算、日结等操作中经常会碰到一些"批处理“作业。
这些批处理经常会涉及到一些大数据处理,同时处理一批增、删、改、查等SQL,往往涉及到好几张表,这边取点数据那边写点数据,运行一些存储过程等。
批处理往往耗时、耗资源,往往还会用到多线程去设计程序代码,有时处理不好还会碰到内存泄漏、溢出、不够、CPU占用高达99%,服务器被严重堵塞等现象。
笔者曾经经历过一个批处理的3次优化,试图从以下几个点去着手优化这个企业跑批。
首先,我们需要该批处理笔者按照数据库连接池的原理实现了一个线程池,使得线程数可以动态设定,不用的线程还可还回线程池。
其次,它需要支持负载均衡。
再者呢,它需要可以在线动态进行如:schedule配置。
然后肯定是良好的监控机制。
在当时动用了5个研发,最终虽然取得了较满意的结果,但是当中不断的优化程序、算法上耗时彼多,尤其是在做负截匀衡时用到了很复杂的机制等。大家知道,一个web或者是一个app容器当达到极限时可以通过加入集群以及增加节点的手段来提高总体的处理能力,但是这个批处理往往是一个应用程序,要把应用程序做成集群通过增加节点的方式来提高处理能力可不是一件简单的事,对吧?
当然我不是说不能实现,硬代码通过SOCKET通讯利用MQ机制加数据库队列是一种比较通用的设计手段,可以做到应用程序在处理大数据大事务时的集群这样的能力。而当时的ibm websphere grid computing组件提供了这么一种能力,但是它太贵了,至少需要上百万才能搞得定。

于是我们就有了xxljob这么一个开源的网格计算产品出来了。所谓网格计算和集群不一样的地方在于,
网格本质上就是动态的。集群包含的处理器和资源的数量通常都是静态的;而在网格上,资源则可以动态出现。资源可以根据需要添加到网格中,或从网格中删除。网格天生就是在本地网、城域网或广域网上进行分布的。通常,集群物理上都包含在一个位置的相同地方;网格可以分布在任何地方。集群互连技术可以产生非常低的网络延时,如果集群距离很远,这可能会导致产生很多问题。
xxljob的基本使用
源码地址
要使用xxljob请去下载这的源码,目前最新版本为:2.2.0,源码地址在这:https://github.com/xuxueli/xxl-job/tree/v2.2.0
下载解压后你会得到这么一个目录。

请使用eclipse把它整个导入进你的workspace中去,你会得到嘎许多东东
其中我们主要使用的是xxl-job-admin这个工程。要做生产级别的使用,我们必须使用数据库做载体。
准备数据库
我们打开“xxl-job-master->doc->db->tables_xxl_job.sql”这个文件,把它放到我们的mysql中运行它。

CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_cron` varchar(128) NOT NULL COMMENT '任务执行CRON',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` varchar(512) DEFAULT NULL COMMENT '执行器地址列表,多地址逗号分隔',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL);
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_cron`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '0 0 0 * * ? *', '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
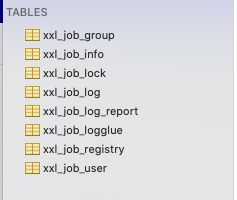
commit;运行后它会在我们的mysql中生成一个叫xxl_job的schema,在下面会有8张表(不是12张啊,网上都是12张的2.0的beta版,不准确!以我为准)。
配置xxl-job-admin工程
我们打开application.properties
### web
server.port=9091
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=jobadmin
spring.datasource.password=111111
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
### xxl-job, email
spring.mail.host=localhost
spring.mail.port=25
spring.mail.username=javamail
spring.mail.password=111111
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=false
spring.mail.properties.mail.smtp.starttls.required=false
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### xxl-job, access token
xxl.job.accessToken=
### xxl-job, i18n (default is zh_CN, and you can choose "zh_CN", "zh_TC" and "en")
xxl.job.i18n=zh_CN
## xxl-job, triggerpool max size
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### xxl-job, log retention days
xxl.job.logretentiondays=30下面是核心参数解析
xxl-job-admin portal所在地址
server.port=9091
server.servlet.context-path=/xxl-job-admin
xxl-job-admin的数据库配置
### xxl-job, datasource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=jobadmin
spring.datasource.password=111111
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
xxl-job-admin默认使用了hikari数据库连接池,它是目前性能最好的数据库连接池。目前市面上的数据库连接池的性能比从高到低的位置为:hikariCP>druid>tomcat-jdbc>dbcp>c3p0 。
druid连接池只是功能比较多而己,这不是瞎说的,这是业界的权威数据对比:
| 是否支持PSCache | 是 | 是 | 是 | 否 | 否 |
| 监控 | jmx | jmx/log/http | jmx,log | jmx | jmx |
| 扩展性 | 弱 | 好 | 弱 | 弱 | 弱 |
| sql拦截及解析 | 无 | 支持 | 无 | 无 | 无 |
| 代码 | 简单 | 中等 | 复杂 | 简单 | 简单 |
| 更新时间 | 2015.8.6 | 2015.10.10 | 2015.12.09 | 2015.12.3 | |
| 特点 | 依赖于common-pool | 阿里开源,功能全面 | 历史久远,代码逻辑复杂,且不易维护 | 优化力度大,功能简单,起源于boneCP | |
| 连接池管理 | LinkedBlockingDeque | 数组 | FairBlockingQueue | threadlocal+CopyOnWriteArrayList |
报警邮件的设置
### xxl-job, email
spring.mail.host=localhost
spring.mail.port=25
spring.mail.username=javamail
spring.mail.password=111111
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=false
spring.mail.properties.mail.smtp.starttls.required=false
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
我在我的本机搭建了一个james邮件服务器,因为我没有域、也没有证书,一穷二白。所以我就把starttls全给关闭了的哈!
运行xxl-job-admin
配完后我们通过XxlJobAdminApplication.java来启动它。
输入http://localhost:9091/xxl-job-admin/ 后我们会被提示用户名和密码。xxl-job-admin的默认用户名和密码为admin/123456.
登录后请自行点击右上角的“欢迎xxx“图标然后修改admin的密码即可。
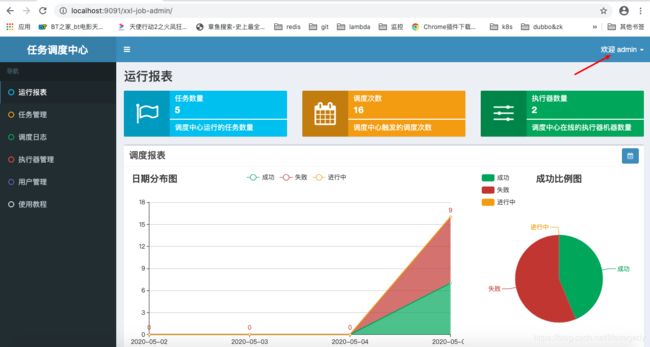
xxl-job的基本实现
有了xxl-admin-job后我们就需要再知道一个概念,executor。
executor
什么是executor?
一个executor就是一个spring boot的xxl-job。没错,在生产上运行时我建议是一个批处理一个job,以达到最佳的扩展性。
你要省一点,也是可以的,那么可以把一组业务相同的job放在一个spring boot工程中。
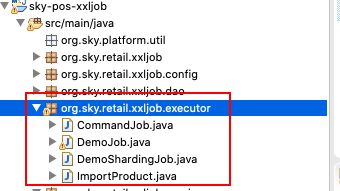
如这边,我们定义了4个job,每个job都符合这样的规则:
@Component
public class DemoJob {
@XxlJob("demoJobHandler")
public ReturnT demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
//具体做点虾米内容
return ReturnT.SUCCESS;
}
} xxl-job结构体解说
首先,它必须是一个@Component。
其次,它有一个"public ReturnT
需要注意的地方是:
- 如果job返回的是成功,那么需要使用return ReturnT.SUCCESS;
- 如果job有碰到exception反回失败,那么需要使用return ReturnT.FAIL,相应的FAIL也会触发邮件的报警;
- 任何需要在xxl-job-admin中显示成功、运行、失败日志的内容,你必须使用:XxlJobLogger而不是log4j,你也可以使用log4j混用;
创建我们自己的executor
工程介绍
我们的工程是标准的parent->module群→子module的maven工程,因此我下面给出完整的maven依赖。
parent工程

pom.xml
4.0.0
org.sky.retail.platform
sky-parent2.0
0.0.1
pom
1.8
2.1.7.RELEASE
2.1.3.RELEASE
3.4.13
Finchley.RELEASE
2.7.3
4.0.1
2.8.0
1.1.20
27.0.1-jre
1.2.59
2.7.3
1.1.4
5.1.46
3.4.2
1.8.13
1.8.14-RELEASE
0.0.1
1.0.0
4.1.42.Final
0.1.4
1.16.22
3.1.0
3.4.5
1.3.1
1.3.10.RELEASE
1.0.2
4.0.0
2.4.6
2.9.2
1.9.6
1.5.23
1.5.22
1.5.22
1.9.5
0.0.1
0.0.1
3.1.6
2.9.6
2.8.6
2.5.8
0.1.4
1.7.25
2.0-M2-groovy-2.5
2.2.0
2.6
${java.version}
${java.version}
3.6.0
3.2.3
3.1.1
UTF-8
UTF-8
org.logback-extensions
logback-ext-spring
${logback-ext-spring.version}
org.slf4j
jcl-over-slf4j
${jcl-over-slf4j.version}
org.springframework.cloud
spring-cloud-starter-zookeeper-discovery
${spring-cloud-zk-discovery.version}
commons-logging
commons-logging
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
org.springframework.cloud
spring-cloud-starter-zookeeper-discovery
org.apache.zookeeper
zookeeper
${zookeeper.version}
org.slf4j
slf4j-log4j12
log4j
log4j
com.xuxueli
xxl-job-core
${xxljob.version}
org.springframework.boot
spring-boot-starter-test
${spring-boot.version}
test
org.springframework.boot
spring-boot-starter-logging
org.slf4j
slf4j-log4j12
org.spockframework
spock-core
1.3-groovy-2.4
test
org.spockframework
spock-spring
1.3-RC1-groovy-2.4
test
org.codehaus.groovy
groovy-all
2.4.6
com.google.code.gson
gson
${gson.version}
com.fasterxml.jackson.core
jackson-databind
${jackson-databind.version}
org.springframework.boot
spring-boot-starter-web-services
${spring-boot.version}
org.apache.cxf
cxf-rt-frontend-jaxws
${cxf.version}
org.apache.cxf
cxf-rt-transports-http
${cxf.version}
org.springframework.boot
spring-boot-starter-security
${spring-boot.version}
io.github.swagger2markup
swagger2markup
1.3.1
io.springfox
springfox-swagger2
${swagger.version}
io.springfox
springfox-swagger-ui
${swagger.version}
com.github.xiaoymin
swagger-bootstrap-ui
${swagger-bootstrap-ui.version}
io.swagger
swagger-annotations
${swagger-annotations.version}
io.swagger
swagger-models
${swagger-models.version}
org.sky
sky-sharding-jdbc
${sky-sharding-jdbc.version}
org.sky.retail.platform
sky-pos-common2.0
${sky-pos-common.version}
com.googlecode.xmemcached
xmemcached
${xmemcached.version}
org.apache.shardingsphere
sharding-jdbc-core
${shardingsphere.jdbc.version}
org.springframework.kafka
spring-kafka
1.3.10.RELEASE
org.mybatis
mybatis
${mybatis.version}
org.mybatis
mybatis-spring
${mybatis.spring.version}
org.springframework.boot
spring-boot-starter-web
${spring-boot.version}
org.slf4j
slf4j-log4j12
org.springframework.boot
spring-boot-starter-logging
org.springframework.boot
spring-boot-dependencies
${spring-boot.version}
pom
import
org.apache.dubbo
dubbo-spring-boot-starter
${dubbo.version}
org.slf4j
slf4j-log4j12
org.springframework.boot
spring-boot-starter-logging
org.apache.dubbo
dubbo
${dubbo.version}
javax.servlet
servlet-api
org.apache.curator
curator-framework
${curator-framework.version}
org.apache.curator
curator-recipes
${curator-recipes.version}
mysql
mysql-connector-java
${mysql-connector-java.version}
com.alibaba
druid
${druid.version}
com.alibaba
druid-spring-boot-starter
${druid.version}
com.lmax
disruptor
${disruptor.version}
com.google.guava
guava
${guava.version}
com.alibaba
fastjson
${fastjson.version}
org.apache.dubbo
dubbo-registry-nacos
${dubbo-registry-nacos.version}
com.alibaba.nacos
nacos-client
${nacos-client.version}
org.aspectj
aspectjweaver
${aspectj.version}
org.springframework.boot
spring-boot-starter-data-redis
${spring-boot.version}
io.seata
seata-all
${seata.version}
io.netty
netty-all
${netty.version}
org.projectlombok
lombok
${lombok.version}
com.alibaba.boot
nacos-config-spring-boot-starter
${nacos.spring.version}
nacos-client
com.alibaba.nacos
net.sourceforge.groboutils
groboutils-core
5
commons-lang
commons-lang
${commons-lang.version}
org.apache.maven.plugins
maven-compiler-plugin
${compiler.plugin.version}
${java.version}
${java.version}
org.codehaus.groovy
groovy-eclipse-compiler
2.7.0-01
org.apache.maven.plugins
maven-war-plugin
${war.plugin.version}
org.apache.maven.plugins
maven-jar-plugin
${jar.plugin.version}
sky-pos-common2.0工程
pom.xml
4.0.0
org.sky.retail.platform
sky-parent2.0
0.0.1
sky-pos-common2.0
jar
com.fasterxml.jackson.core
jackson-databind
com.google.code.gson
gson
com.googlecode.xmemcached
xmemcached
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-logging
org.springframework.boot
spring-boot-starter-log4j2
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-logging
org.aspectj
aspectjweaver
com.lmax
disruptor
redis.clients
jedis
com.google.guava
guava
com.alibaba
fastjson
org.springframework.boot
spring-boot-starter-data-redis
sky-pos-xxljob工程
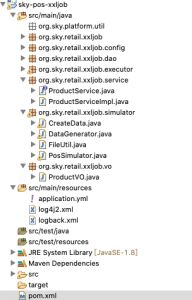
pom.xml
4.0.0
org.sky.retail.platform
sky-parent2.0
0.0.1
jar
sky-pos-xxljob
org.logback-extensions
logback-ext-spring
org.slf4j
jcl-over-slf4j
com.xuxueli
xxl-job-core
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-logging
mysql
mysql-connector-java
com.alibaba
druid
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.boot
spring-boot-starter-log4j2
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-logging
org.slf4j
slf4j-log4j12
org.aspectj
aspectjweaver
com.lmax
disruptor
redis.clients
jedis
com.google.guava
guava
com.alibaba
fastjson
org.springframework.boot
spring-boot-starter-data-redis
com.fasterxml.jackson.core
jackson-databind
com.google.code.gson
gson
org.sky.retail.platform
sky-pos-common2.0
src/main/java
src/test/java
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-compiler-plugin
${compiler.plugin.version}
${java.version}
${java.version}
src/main/resources
src/main/webapp
META-INF/resources
**/**
src/main/resources
true
application.properties
application-${profileActive}.properties
sky-pos-xxljob核心工程
这个,就是我们的poc工程,我们按照spring boot2的规范,先说一下它的application.yml文件内容。
application.yml
server:
port: 8082
logging:
#日志文件
config: classpath:logback.xml
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/storetrans01?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: storetrans01
password: 111111
xxl:
job:
admin:
#调度中心部署跟地址:如调度中心集群部署存在多个地址则用逗号分隔。
#执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调"。
addresses: http://localhost/xxl-job-admin
accessToken:
#分别配置执行器的名称、ip地址、端口号
#注意:如果配置多个执行器时,防止端口冲突
executor:
appname: posDemoExecutor
ip: 127.0.0.1
port: 9999
address:
#执行器运行日志文件存储的磁盘位置,需要对该路径拥有读写权限
logpath: /Users/apple/data/applogs/xxl-job
#执行器Log文件定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保持3天,否则功能不生效;
#-1表示永不删除
logretentiondays: -1我们在此:
- 定义了它的web服务器(内嵌tomcat运行端口);
- 日志文件为logback.xml,这是xxljob必须要使用的日志类,同时你也可以扔一个log4j2.xml文件在resources目录,这个没关系的,但是默认要申明使用logback;
- 数据源,因为我们后面的一个验证集群模式和利用网络计算能力的poc要用到数据库;
- xxljob admin的address的申明,它个地址就是我们布署前面那个xxl-job-admin管理端的服务器所在地址,如果你有多个调度器集群你可以使用类似:http://server1/xxl-job-admin,http://server2/xxl-job-admin这样来做申明,其实在这我们已经使用了两个调度器做集群了,我们其实是设置了2个xxl-job-admin集群上面我们使用了nginx来做了ha了,那么这样nginx再可以由多个,于是就组成了一个个的网络;
- 你可以在executor与admin(又叫调度器)间使用token通讯;
- executor申明,这个executor就是“该springboot中所有的xxl-job在运行时被xxl-job-admin的调度端所”回调“的端口。说白点就是executor与调度端是互相保持心跳并使用”配置管理中心注册“来保持互相同步的这么一种机制。
springboot无注解配置类
DataSourceConfig.java
package org.sky.retail.xxljob.config;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import com.alibaba.druid.pool.DruidDataSource;
import javax.sql.DataSource;
@Configuration
public class DataSourceConfig {
@Bean("dataSource")
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource createDataSource() {
return new DruidDataSource();
}
@Bean
public JdbcTemplate dataSource(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}XxlJobConfig.java
请注意,网上的很多博客用的是2.0初版,很多函数和类别都已经和2.2.0版不一样啦!
package org.sky.retail.xxljob.config;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* xxl-job config
*
* @author mk.yuan 2020-05-06
*/
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖: org.springframework.cloud
* spring-cloud-commons ${version}
*
*
* 2、配置文件,或者容器启动变量 spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}HelloWorld级别的第一个executor
DemoJob.java
package org.sky.retail.xxljob.executor;
import java.util.concurrent.TimeUnit;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
@Component
public class DemoJob {
private static Logger logger = LoggerFactory.getLogger(DemoJob.class);
@XxlJob("demoJobHandler")
public ReturnT demoJobHandler(String param) throws Exception {
XxlJobLogger.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobLogger.log("beat at:" + i);
TimeUnit.SECONDS.sleep(2);
}
return ReturnT.SUCCESS;
}
} job解说
它其实做了一件很简单的事情,模拟一个耗时5秒的job运行,一边运行一边输出日志,最后完成。
布署DemoJob.java至xxl-job-admin
首先,我们先把sky-pos-xxljob运行起来,为此我们书写一个主启动类
XxlJob.java
package org.sky.retail.xxljob;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@ComponentScan(basePackages = { "org.sky" })
@EnableAutoConfiguration(exclude = DataSourceAutoConfiguration.class)
@EnableTransactionManagement
public class XxlJob {
public static void main(String[] args) {
SpringApplication.run(XxlJob.class, args);
}
}
它运行在9999端口。
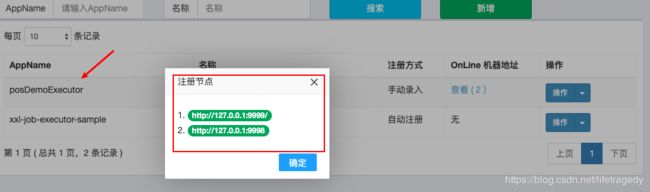
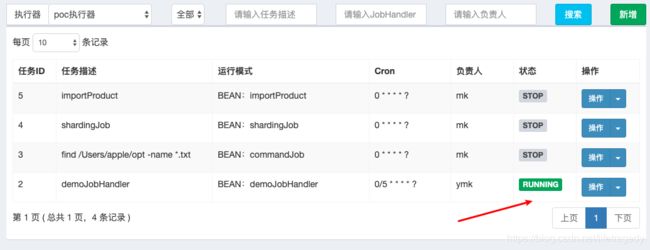
新建执行器
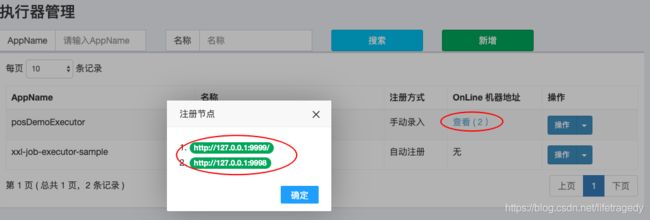
打开xxl-job-admin
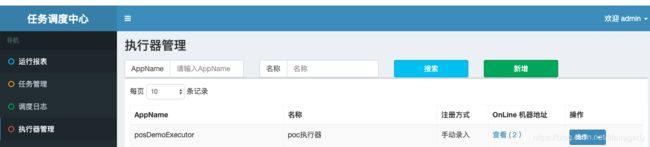
我们新增一个执行器叫posDemoExecutor的,如下内容:
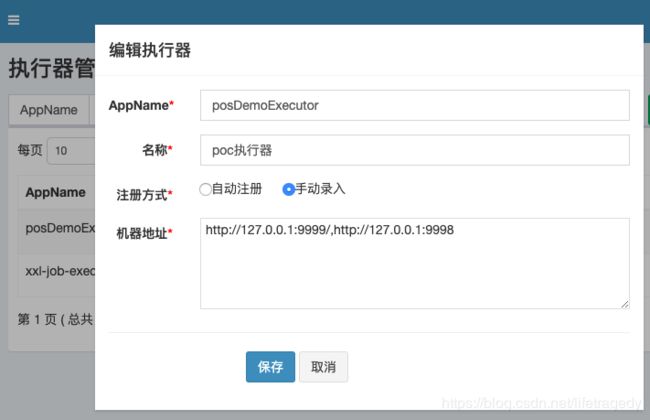
这边的注册方式有需要要注意的:
- 自动发现不可做executor的集群
- 手动录入方式后需要在机器地址中输入相应的executor地址,如果你是executor集群,那么你可以使用逗号来间隔每个executor的地址
新建任务
我们在任务管理中新建一个任务叫”demoJobHandler“,这个名字就和你的executor中的” @XxlJob("demoJobHandler")“必须相同,它是用来做bean的注册用的。
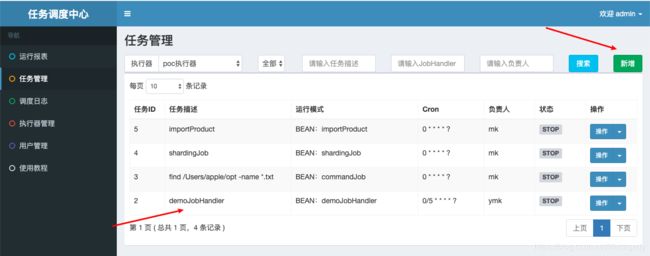
具体任务内容如下:
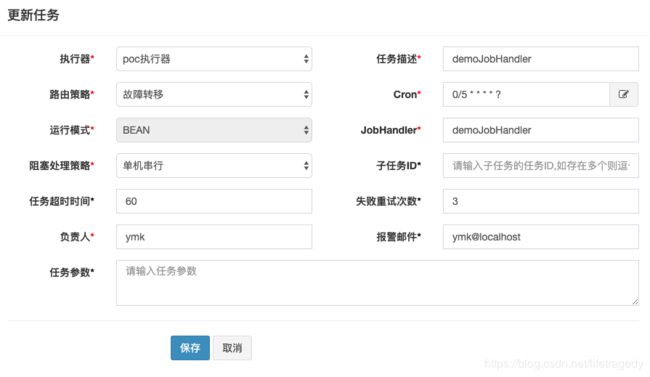
请注意这边我们有几样东西需要注意:
- 故障转移,我会使用同样功能多个executor给做”故障转移“,说白了我一个job由若干个workers去共同做,一个人做,其它workers等待,如果那个主要负责的workers猝了,另一个worker马上顶上;
- 任务超时,多久时间executor没有和xxl-job-admin(调度端)通讯,那么该任务执行就认为失败;
- jobHandler就是@XxlJob("demoJobHandler")中的bean的名字;
- cron,这个是标准的cron表达式,我们这边设置的是每隔5秒执行一次,说白了就是你点”开始“这个工作,它会每隔5秒开始执行一下;
全配置好了后,我们回到eclipse里。
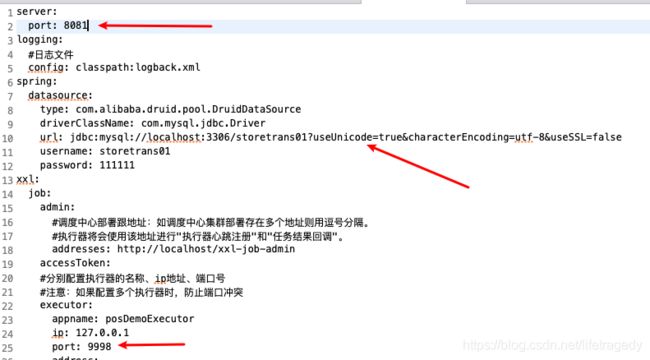
保持当前的xxljob的executor处于运行状态,然后我们把application.yml文件中的:
- server:port:8081,这边从本来的8082改成8081
- xxl:job:executor:port,这边从本来的9999改成9998
再运行一下XxlJob.java,使得在eclipse里再启动起一个xxljob的executor来,它运行在9998端口
然后我们来运行这个任务吧!
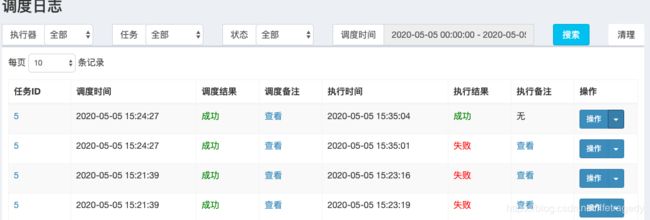
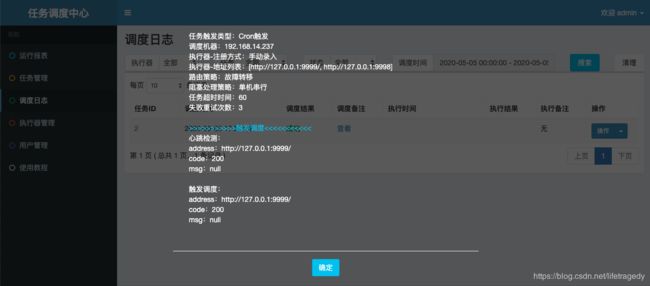
运行demoJobHandler

启动后我们是可以在“调度日志”里不断的看到日志文件被生成。
实际的日志文件位于这“/Users/apple/data/applogs/xxl-job”,它也在我们的application.yml文件中所配
在界面中我们可以直接看到该日志内容:
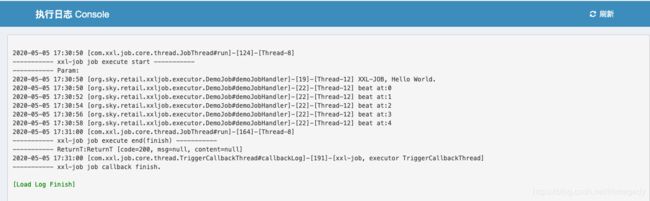
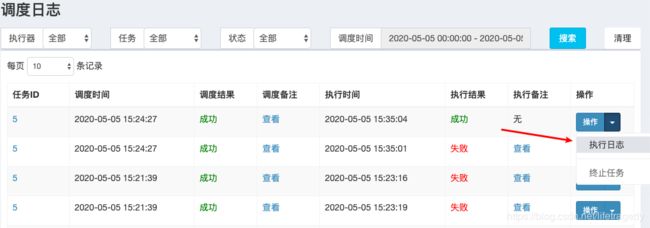
模拟executor宕机
我们配了2个executor,一个运行在9999,一个运行在9998,如果我们杀了一个,理论上另一个executor会立刻把任务接手过来。
所以我们杀9998.

杀了,然后我们来看看admin端
我们可以看到xxl-job-admin端任务状态是运行,xxl-job-admin后端也抛了错。
但是,我们依旧可以看到调度日志里的“成功”任务还在不断的增加:
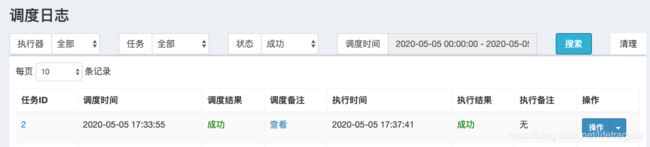
间隔了1分钟的查询:
我们再来查查看有没有“失败”的任务
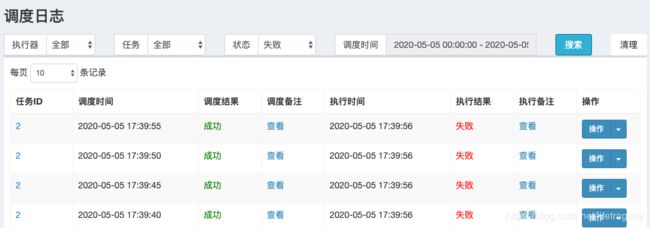
有任务的失败记录,同时我们也在executor 9998被杀死时也接到了报警邮件。
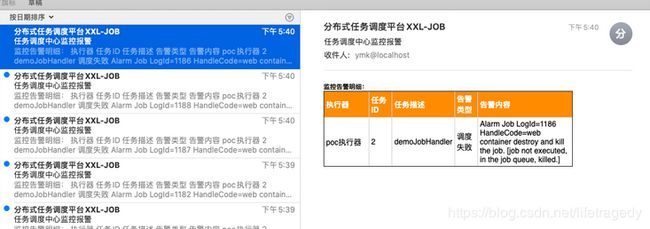
但是我们的executor依旧运行的很好。
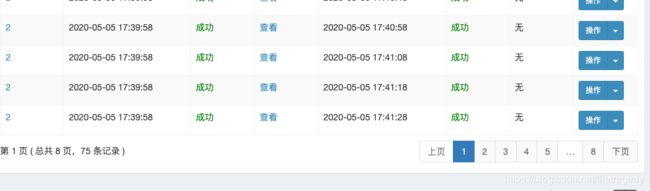
这说明,2个executor一个挂了,另一个立刻把这个executor的任务给接手过来了。
该场景适用于“多个executor集群运行同一个相同的任务“,但是同时只有一个executor在运行,其它的executor一旦碰到运行中的executor挂机时立刻会被顶上,它会在1秒不到内自动启来。
xxl-job的HA机制的实现
目标
制作一个job,它主要作的事为:
- 每次在s_order表中选取10条handle_flag=0的记录,并且该记录在s_order_item中存在;
- 根据以上关系关联查询s_order表和s_order_item表,并计算s_order_item表中的goods_amount*sales_price的乘职;
- 然后把计算后的值插入到s_order_rpt表中;
- 插入s_order_rpt表成功后,把这10条记录在s_order表中的handle_flag置为1;
验证步骤
- 启动两个同样的job,一个运行在9998端口,一个运行在9999端口;
- 把job设成“故障转移”机制;
- 让该job始终处于运行状态;
- 在运行时,杀掉第1个job,观察任务,观察数据库,由于2个job中有1个活着,因此不会报错,任务照样进行。但是由于是jbox-executor被杀,因为会受到“报警邮件”;
- 把杀掉的第1个job恢复,观察任务,观察数据库,任务照样进行;
- 杀掉第2个job,观察任务,观察数据库,由于2个job中有1个活着,因此不会报错,任务照样进行,但是由于是jbox-executor被杀,因为会受到“报警邮件”;
- 让第1个job以单实例继续运行完后,观察s_order_rpt中的记录数应等于最先s_order中handle_flag=0的总记录数
开始验证
s_order中总记录数为:2108条
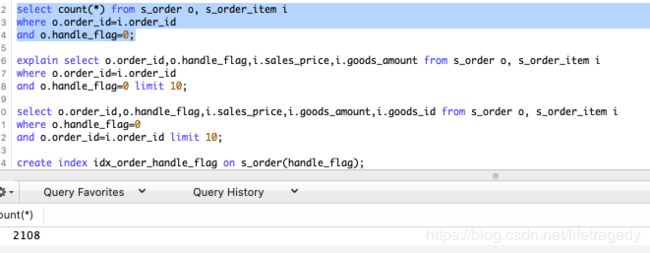
制作job-dbJob
package org.sky.retail.xxljob.executor;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import javax.annotation.Resource;
import org.sky.retail.xxljob.service.OrderService;
import org.sky.retail.xxljob.vo.OrderVO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
@Component
public class DbJob {
private static Logger logger = LoggerFactory.getLogger(DbJob.class);
@Resource
private OrderService orderService;
@XxlJob("dbJob")
public ReturnT dbJob(String param) throws Exception {
try {
int result = orderService.updateOrderRpt();
return ReturnT.SUCCESS;
} catch (Exception e) {
XxlJobLogger.log(e.getMessage(), e);
return ReturnT.FAIL;
}
}
} OrderDao.java
package org.sky.retail.xxljob.dao;
import java.util.List;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.vo.OrderVO;
public interface OrderDao {
public List getOrdersByLimit(int limits) throws RunTimeException;
public int updateOrderRpt(List orderList) throws RunTimeException;
public int isOrderExisted(String orderId) throws RunTimeException;
} OrderDaoImpl.java
package org.sky.retail.xxljob.dao;
import java.math.BigDecimal;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import javax.annotation.Resource;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.vo.OrderVO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.stereotype.Component;
@Component
public class OrderDaoImpl implements OrderDao {
protected Logger logger = LoggerFactory.getLogger(this.getClass());
@Resource
private JdbcTemplate jdbcTemplate;
@Override
public int isOrderExisted(String orderId) throws RunTimeException {
int result = 0;
String checkOrderExistSql = "select count(*) from s_order_rpt where order_id=?";
try {
result = jdbcTemplate.queryForObject(checkOrderExistSql, Integer.class, orderId);
return result;
} catch (Exception e) {
logger.error("isOrderExisted error: " + e.getMessage(), e);
throw new RunTimeException("isOrderExisted error: " + e.getMessage(), e);
}
}
@Override
public List getOrdersByLimit(int limits) throws RunTimeException {
List orderList = new ArrayList();
StringBuffer sql = new StringBuffer();
sql.append(
" select o.order_id,i.goods_id,o.handle_flag,i.sales_price,i.goods_amount from s_order o, s_order_item i");
sql.append(" where o.handle_flag=0");
sql.append(" and o.order_id=i.order_id limit ?");
try {
orderList = jdbcTemplate.query(sql.toString(), new Object[] { new Integer(limits) },
new RowMapper() {
@Override
public OrderVO mapRow(ResultSet rs, int rowNum) throws SQLException {
OrderVO order = new OrderVO();
order.setOrderId(rs.getString("order_id"));
order.setGoodsAmount(rs.getInt("goods_amount"));
order.setSalesPrice(rs.getBigDecimal("sales_price"));
order.setHandleFlag(rs.getInt("handle_flag"));
order.setGoodsId(rs.getInt("goods_id"));
return order;
}
});
orderList.forEach((item) -> {
logger.info(">>>>>>order_id->" + item.getOrderId() + " goods_amount->" + item.getGoodsAmount()
+ " sales_price->" + item.getSalesPrice() + " handle_flag->" + item.getHandleFlag());
});
} catch (Exception e) {
logger.error("getOrdersByLimit[" + limits + "] error: " + e.getMessage(), e);
throw new RunTimeException("getOrdersByLimit[" + limits + "] error: " + e.getMessage(), e);
}
return orderList;
}
public int addOrderRpt(OrderVO order) throws RunTimeException {
int result = 0;
String addOrderRptSql = "";
addOrderRptSql = "insert into s_order_rpt(order_id,goods_id,goods_amount,sales_price,total_price)values(?,?,?,?,?)";
try {
BigDecimal goodsAmount = BigDecimal.valueOf(order.getGoodsAmount());
BigDecimal salesPrice = order.getSalesPrice();
BigDecimal totalPrice = salesPrice.multiply(goodsAmount);
String orderId = order.getOrderId();
int goodsId = order.getGoodsId();
result = isOrderExisted(orderId);
if (result < 1) {
logger.info(">>>>>>orderId->" + orderId + " goodsAmount->" + goodsAmount + " and salesPrice->"
+ salesPrice + " and totalPrice->" + totalPrice);
// result = 1;
// totalPrice=salesPrice*goodsAmount;
jdbcTemplate.update(addOrderRptSql.toString(), orderId, goodsId, goodsAmount, salesPrice, totalPrice);
} else {
logger.info(">>>>>>orderId->" + orderId + " existed, skipped");
}
result = 1;
} catch (Exception e) {
logger.error("add s_order_rpt error: " + e.getMessage(), e);
throw new RunTimeException("add s_order_rpt error: " + e.getMessage(), e);
}
return result;
}
public int updateOrderRpt(List orderList) throws RunTimeException {
int result = 0;
String updatedOrderSql = "update s_order set handle_flag=? where order_id=?";
try {
for (Iterator it = orderList.iterator(); it.hasNext();) {
OrderVO order = (OrderVO) it.next();
int insertRecord = addOrderRpt(order);
if (insertRecord > 0) {
jdbcTemplate.update(updatedOrderSql, "1", order.getOrderId());
result = 1;
}
}
return result;
} catch (Exception e) {
logger.error("updateTotalPrice error: " + e.getMessage(), e);
throw new RunTimeException("updateTotalPrice error: " + e.getMessage(), e);
}
}
} OrderService.java
package org.sky.retail.xxljob.service;
import java.util.List;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.vo.OrderVO;
public interface OrderService {
public List getOrdersByLimit(int limits) throws RunTimeException;
public int updateOrderRpt() throws RunTimeException;
} OrderServiceImpl.java
package org.sky.retail.xxljob.service;
import java.util.ArrayList;
import java.util.List;
import javax.annotation.Resource;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.dao.OrderDao;
import org.sky.retail.xxljob.vo.OrderVO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service
public class OrderServiceImpl implements OrderService {
protected Logger logger = LoggerFactory.getLogger(this.getClass());
@Resource
private OrderDao orderDao;
@Override
@Transactional(propagation = Propagation.REQUIRED)
public List getOrdersByLimit(int limits) throws RunTimeException {
List orderList = new ArrayList();
try {
orderList = orderDao.getOrdersByLimit(10);
} catch (Exception e) {
logger.error(e.getMessage(), e);
throw new RunTimeException(e.getMessage(), e);
}
return orderList;
}
@Override
@Transactional(propagation = Propagation.REQUIRED)
public int updateOrderRpt() throws RunTimeException {
int result = 0;
try {
List rawOrderList = getOrdersByLimit(20);
result = orderDao.updateOrderRpt(rawOrderList);
logger.info(">>>>>>updateOrderRpt result->" + result);
} catch (Exception e) {
logger.error(e.getMessage(), e);
throw new RunTimeException(e.getMessage(), e);
}
return result;
}
} OrderVO.java
package org.sky.retail.xxljob.vo;
import java.io.Serializable;
import java.math.BigDecimal;
public class OrderVO implements Serializable {
private static final long serialVersionUID = 1L;
private String orderId = "";
private int goodsAmount = 0;
private BigDecimal salesPrice = new BigDecimal(0.0);
private int handleFlag = 0;
private int goodsId = 0;
private BigDecimal totalPrice = new BigDecimal(0.0);
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public int getGoodsAmount() {
return goodsAmount;
}
public void setGoodsAmount(int goodsAmount) {
this.goodsAmount = goodsAmount;
}
public BigDecimal getSalesPrice() {
return salesPrice;
}
public void setSalesPrice(BigDecimal salesPrice) {
this.salesPrice = salesPrice;
}
public int getHandleFlag() {
return handleFlag;
}
public void setHandleFlag(int handleFlag) {
this.handleFlag = handleFlag;
}
public int getGoodsId() {
return goodsId;
}
public void setGoodsId(int goodsId) {
this.goodsId = goodsId;
}
public BigDecimal getTotalPrice() {
return totalPrice;
}
public void setTotalPrice(BigDecimal totalPrice) {
this.totalPrice = totalPrice;
}
}dbJob在xxl-job-admin中的配置
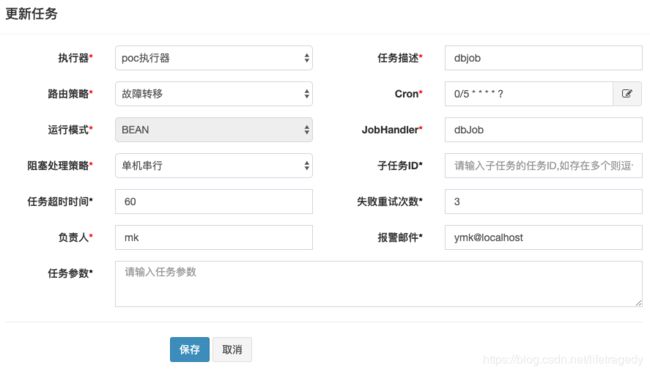
启动后,我们使用下面的sql可以看到job已经开始运行
select count(*) from s_order_rpt;启动成两个job,然后,我们把第1个job杀掉
我们发觉整个数据库继续在进数据且xxl-job-admin控制台无任何报错。

但是收到了报警邮件,说明全流程正确也说明了:9998被杀后任务已经飘到了9999上。
这说明另一个job已经接手了前一个job的工作。
然后我们把第1个job恢复,然后杀第2个job

我们发觉数据库继续进数据进的很后,同时xxl-job-admin控制端也无出错记录
然后我们把第1个job保持“单实例”运行,直到结束。
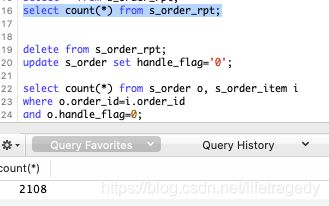
最后整个s_order_rpt中的记录数为:2108
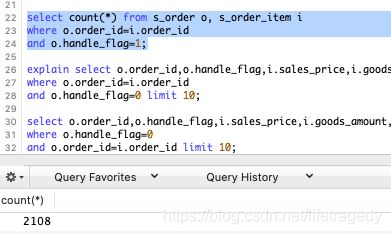
而s_order表handle_flag为1的记录从0变成了:2108
结论
只要你启动n个job,这n个job做同一件事同时这n个是job被分配成了“故障转移”,无论你是:
- 还未运行时,先杀一个进程
- 还是运行到一半时,把正在运行的进程杀掉(前面先杀1,让2运行,然后2在运行时恢复1再杀2让1继续运行直到结束足以证明)
都不影响这种“故障转移”类的job。
附:建表语句:
s_order表
CREATE TABLE `s_order` (
`order_id` varchar(32) NOT NULL DEFAULT '',
`price_amount` decimal(11,2) DEFAULT NULL,
`channel` tinyint(4) DEFAULT NULL,
`order_type` int(3) DEFAULT NULL,
`member_id` varchar(32) DEFAULT NULL,
`order_status` tinyint(4) DEFAULT NULL,
`handle_flag` tinyint(1) DEFAULT '0',
PRIMARY KEY (`order_id`),
KEY `idx_order_handle_flag` (`handle_flag`)
) ENGINE=InnoDB;s_order_item表
CREATE TABLE `s_order_item` (
`item_id` int(32) unsigned NOT NULL AUTO_INCREMENT,
`store_id` int(8) DEFAULT NULL,
`trans_id` varchar(32) DEFAULT NULL,
`pos_id` int(16) DEFAULT NULL,
`order_id` varchar(32) DEFAULT NULL,
`goods_id` int(16) DEFAULT NULL,
`goods_amount` int(11) DEFAULT NULL,
`sales_price` decimal(11,2) DEFAULT NULL,
PRIMARY KEY (`item_id`)
) ENGINE=InnoDB;s_order_rpt表
CREATE TABLE `s_order_rpt` (
`order_id` varchar(32) NOT NULL,
`goods_id` int(16) DEFAULT NULL,
`goods_amount` int(11) DEFAULT NULL,
`sales_price` decimal(11,2) DEFAULT NULL,
`total_price` decimal(11,2) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB;xxljob强大的高可用网格计算功能全流程
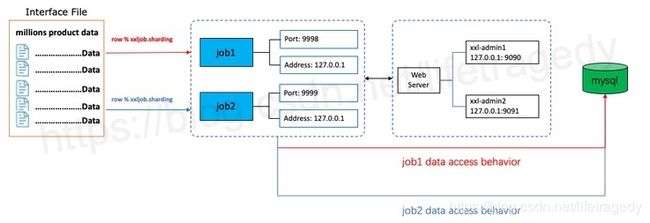
在有了前三篇的基础上,我们将会实现一个全真的基于网格计算的跑批实例。
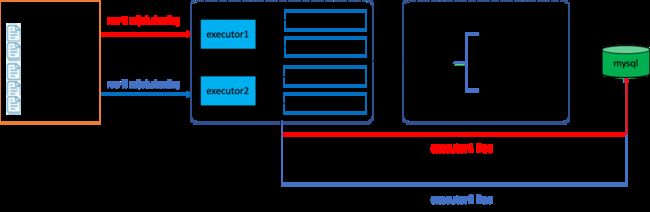
- 创建1个100万条记录的csv文件;
- 创建2个executor运行在不同的实例中(为演示我运行在本机,但是运行在2个不同的端口上,它是真正的独立的2个java进程);
- 2个executor里用一套xxljob自带的sharding机制,自动把100万条记录按照executor数量的实际取模后sharding到不同的executor中解析、进db(如何sharing是xxljob自带的强大功能);
- 使用2个xxl-admin-job运行在不同的实例中(为演示我运行在本机,但是运行在2个不同的端口上,它是真正的独立的2个java进程)来作成ha
付诸实施
创建了100万条记录
我自己写了一个生成100万条记录的csv生成器,它的内容如下:
0,FTWQHI,1
1,sZaKaD,5
2,7ONcDE,2
3,hqSRSH,3
4,g1FeyD,2
5,Pajn15,5它有3个字段,分别对应着:goods_id,goods_name,stock,一共有100万条记录
这块代码就作为各位自己做练习了,没什么难的。
创建xxljob
ImportProduct.java
package org.sky.retail.xxljob.executor;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.File;
import javax.annotation.Resource;
import org.sky.platform.retail.util.StringUtility;
import org.sky.retail.xxljob.service.ProductService;
import org.sky.retail.xxljob.vo.ProductVO;
import org.springframework.stereotype.Component;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
import com.xxl.job.core.util.ShardingUtil;
@Component
public class ImportProduct {
@Resource
private ProductService productService;
@XxlJob("importProduct")
public ReturnT shardingJobHandler(String param) throws Exception {
//多少条记录cpu一休息,每次休息250ms
int rowLimit=1000;
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// String filePath = "/Users/apple/data/demo_product.csv";
BufferedReader file = null;
if (param == null || param.trim().length() < 1) {
XxlJobLogger.log("必须输入合法的需要导入的csv文件路径");
return ReturnT.FAIL;
} else {
File f = new File(param);
if (!f.exists()) {
XxlJobLogger.log("必须输入合法的需要导入的csv文件路径");
return ReturnT.FAIL;
}
}
try {
String filePath = param;
file = new BufferedReader(new InputStreamReader(new FileInputStream(filePath), "UTF-8"));
String record;
int rowNum = 0;
int productNum = 0;
while ((record = file.readLine()) != null) {
boolean check = true;
String goodsName = "";
int stock = 0;
String fields[] = record.split(",");
if (fields == null || fields.length < 3) {
XxlJobLogger.log("row[" + rowNum + "] has error->skipped");
check = false;
} else {
if (StringUtility.isInteger(fields[0])) {
productNum = Integer.parseInt(fields[0]);
} else {
XxlJobLogger.log("row[" + rowNum + "] and col[0] expected numeric but it is [" + fields[0]
+ "]->skipped");
check = false;
}
}
goodsName = fields[1];
if (StringUtility.isInteger(fields[2])) {
stock = Integer.valueOf(fields[2]);
} else {
XxlJobLogger.log(
"row[" + rowNum + "] and col[2] expected numeric but it is [" + fields[2] + "]->skipped");
check = false;
}
if (check) {
if (productNum % shardingVO.getTotal() == shardingVO.getIndex()) {
// XxlJobLogger.log("第 {} 片, 命中分片开始处理第 {} 条记录", shardingVO.getIndex(),
// (productNum + 1));
ProductVO product = new ProductVO();
product.setGoodsId(productNum);
product.setGoodsName(goodsName);
product.setStock(stock);
try {
productService.addProduct(product);
} catch (Exception e) {
XxlJobLogger.log("第 {} 片, 第 {} 条记录处理出错,出错原因{}", shardingVO.getIndex(), (productNum + 1),
e.getMessage(), e);
}
if (rowNum % rowLimit == 0) {
XxlJobLogger.log("第 {} 片, 处理到 goods_id -> {}", shardingVO.getIndex(), productNum);
rowNum = 0;
Thread.sleep(250);
}
rowNum++;
}
}
}
XxlJobLogger.log("第 {} 片, 第 {} 条记录处理完毕", shardingVO.getIndex(), (productNum + 1));
} catch (Exception e) {
XxlJobLogger.log("error: " + e.getMessage(), e);
return ReturnT.FAIL;
} finally {
try {
if (file != null) {
file.close();
file = null;
}
} catch (Exception e) {
}
}
return ReturnT.SUCCESS;
}
} 核心代码解说
这里面最最好玩的部分在于这边
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
if (productNum % shardingVO.getTotal() == shardingVO.getIndex()) {
//do import job
}这个ShardingUtil正是xxljob自带的,它的作用是这样的:
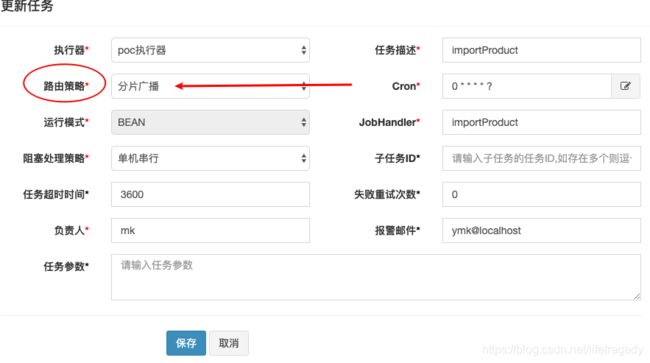
只要你在xxl-job-admin即调度器中,把任务中的【路由策略】设成了”分片广播“,你在相应的executor里就会得到shardingVO.getTotal和shardingVO.getIndex这2个参数。
在xxl-job-admin中我们是设置成了2个executor,因此:
- shardingVO.getTotal会得到2;
- 在executor1中shardingVO.getIndex你会得到0;
- 在executor2中shardingVO.getIndex你会得到1;
后面的,如果你真的是程序员,那么求个模就能对数据进行分片了。然后剩下的就简单的,插数据库呀!
ProductDao.java
package org.sky.retail.xxljob.dao;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.vo.ProductVO;
public interface ProductDao {
public void addProduct(ProductVO product) throws RunTimeException;
}ProductDaoImpl.java
package org.sky.retail.xxljob.dao;
import javax.annotation.Resource;
import org.sky.platform.retail.exception.RunTimeException;
import org.sky.retail.xxljob.vo.ProductVO;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Component;
@Component
public class ProductDaoImpl implements ProductDao {
@Resource
private JdbcTemplate jdbcTemplate;
@Override
public void addProduct(ProductVO product) throws RunTimeException {
String productSql = "insert into my_goods(goods_id,goods_name,stock)values(?,?,?)";
try {
jdbcTemplate.update(productSql, product.getGoodsId(), product.getGoodsName(), product.getStock());
} catch (Exception e) {
throw new RunTimeException(
"error occured on insert into my_goods with: goods_id->" + product.getGoodsId() + " goods_name->"
+ product.getGoodsName() + " error: " + " stock->" + product.getStock() + e.getMessage(),
e);
}
}
}启动两executor
第一步:把sky-pos-xxljob中的application.yml保持成以下形式,并启动
第二:把sky-pos-xxljob中的application.yml改成以下形式,并启动

第三步:把xxl-job-admin做成cluster
xxl-job-admin的集群
- xxl-job-admin可以启动多个,但是它们只能以ha形式来运行;
- 多个admin可以端口号不同,但是它们必须指向同一个数据库且必须使用数据库才能使用ha集群;
- xxl-job-admin的2.0.x版本使用的是落后的quartz,它的技术停留在3-4年前。而现在最新版的xxl-job-admin是自自己用netty写的计时器,它在效率、可维护性、稳定性上目前在业界排在(非大数据定时器)首位
第一步:保持xxl-job-admin中的application.properties为如下形式并启动
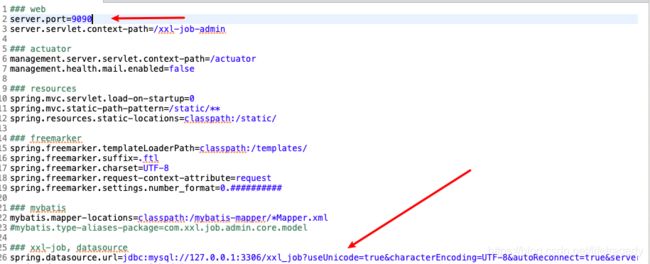
第二步:把xxl-job-admin中的application.properties改为如下形式并启动

至此,我们一共启动了2个executor2个admin(调度端),下面我们就需要配至admin的ha了。
xxl-job-admin的HA集群
其实,我们在2个executor中已经使用了通过ng做代理的xxl-job-admin的负载均衡的地址形式了
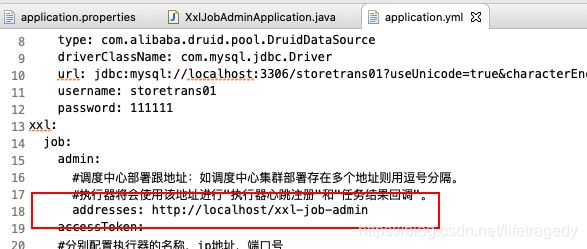
修改nginix
注:
nginix怎么装不属于本教程范围,这个不会不应该!
我们在nginix.conf文件所在目录创建一个vhost文件夹
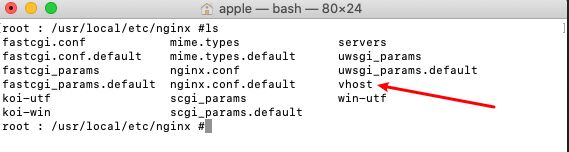
在vhost目录内放置一个xxljob_admin.conf文件

内容如下:
upstream xxljob_admin{
server localhost:9090 weight=1;
server localhost:9091 weight=1;
}
server {
listen 80;
server_name localhost;
access_log /usr/local/var/log/nginx/xxljob_admin.access.log;
error_log /usr/local/var/log/nginx/xxljob_admin.error.log;
#root html;
#index index.html index.htm index.jsp index.php;
location / {
proxy_http_version 1.1;
proxy_set_header Connection "";
proxy_pass http://xxljob_admin;
#Proxy Settings
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_max_temp_file_size 0;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 4k;
proxy_buffers 4 32k;
proxy_busy_buffers_size 64k;
proxy_temp_file_write_size 64k;
}
}注意:
一定要有以下2行
proxy_http_version 1.1;
proxy_set_header Connection "";否则你在传发tomcat的json api请求时,调用端会收到http请求error
配完后我们就可以直接这样启动了:
浏览器中输入:http://localhost/xxl-job-admin/
测试
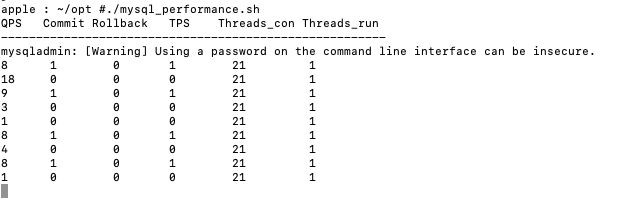
在测试开始前我们制作了一个监控mysql的qps, tps以及其它相关关键指标的小脚本,叫mysql_performance.sh,一起粪上!
#!/bin/bash
mysqladmin -uroot -p'111111' extended-status -i1|awk 'BEGIN{local_switch=0;print "QPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- "}
$2 ~ /Queries$/ {q=$4-lq;lq=$4;}
$2 ~ /Com_commit$/ {c=$4-lc;lc=$4;}
$2 ~ /Com_rollback$/ {r=$4-lr;lr=$4;}
$2 ~ /Threads_connected$/ {tc=$4;}
$2 ~ /Threads_running$/ {tr=$4;
if(local_switch==0)
{local_switch=1; count=0}
else {
if(count>10)
{count=0;print "------------------------------------------------------- \nQPS Commit Rollback TPS Threads_con Threads_run \n------------------------------------------------------- ";}
else{
count+=1;
printf "%-6d %-8d %-7d %-8d %-10d %d \n", q,c,r,c+r,tc,tr;
}
}
}'运行的话直接./mysql_performance.sh,然后你会看到实时刷新的一个类似70年代ibm在各机场里做的“航班表”大黑屏(是不是有点matrix的感觉,^_^)
配置告警用邮箱
我们使用的是apache的james来配置的发告警邮件用邮箱,没有启用tls。
注:apache james如何配置不属于本教程范围,这块建议自行补足,这个很简单,你应该会配。
在xxl-job-admin中配置任务


有多少个executor做“集群运行”是在这边配置的

创测试用数据库表my_goods
CREATE TABLE `my_goods` (
`goods_id` int(16) NOT NULL,
`goods_name` varchar(100) DEFAULT NULL,
`stock` int(11) DEFAULT NULL,
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;运行

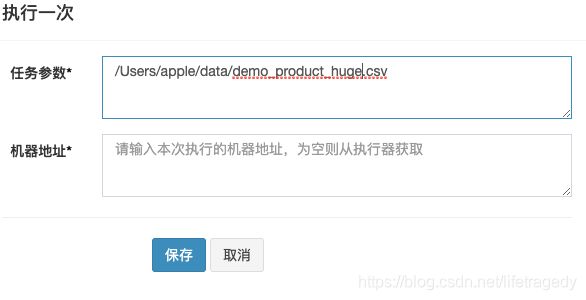
点击完【执行一次】后,在弹出框的任务参数中请填入相应的我们的含有100万条记录的csv所在的全路径。

进入调度日志中,我们看到任务已经开始执行
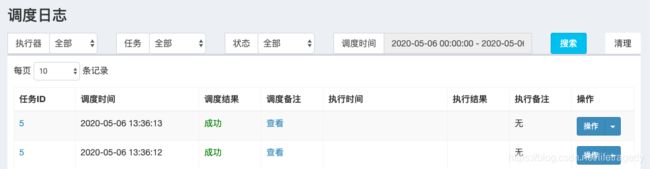
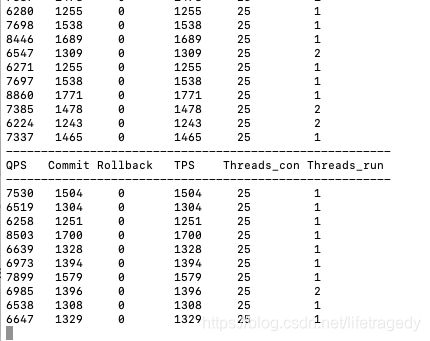
我们在mysql_performance中也已经看到数据库开始起量了。
目前我因为心疼我的mac,因此我只让cpu的运行效率在65%左右,因此我在我的ImportJob中使用了如下技巧:
if (rowNum % rowLimit == 0) {
XxlJobLogger.log("第 {} 片, 处理到 goods_id -> {}", shardingVO.getIndex(), productNum);
rowNum = 0;
Thread.sleep(250);
}实际生产上这几句可以完全去掉,我在我本机上当这几句代码被注释掉时,我的小破笔记本上的平均指标:qps可以到达12,000,而tps到达了2300.
我们可以看到,这个任务一运行就产生了2条调度日志,我们分别来查看这2个日志。
executor0的日志:

它执行的都是“单数”的goos_id的入库。
executor1的日志:
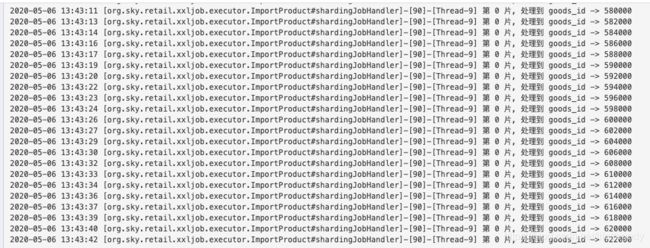
它执行的都是“偶数”的goos_id的入库。
杀掉一个xxl-job-admin进程
我call,杀了!!!

- 观察2个xxl-job的executor端,一点无出错
- 观完mysql_performance的监控端,qps, tps一点不影响
- 观察http://localhost/xxl-job/admin中的调度日志


跑的还很欢,我call。。。这都跑完了。
观察mysql端

随便抽3条记录:
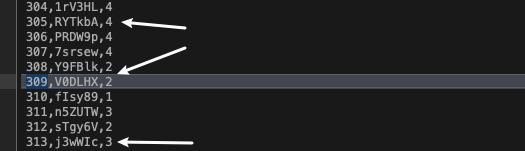
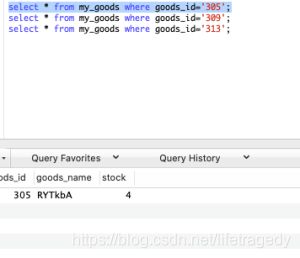
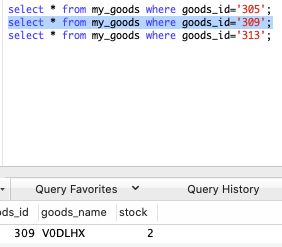
- 如果去除了sleep,在我本机运行实际用时在6分钟。
- 而使用单executor运行实际耗时17分钟。
完美,打完收工!