树莓派安装snowboy
树莓派安装snowboy
树莓派现在已经出到4了,暂时还没有入手的意思,看到我已经静静吃灰的3b,刚好现在有点闲,就想折腾一下,就想着先安装snowboy试一试吧。
1.树莓派换源
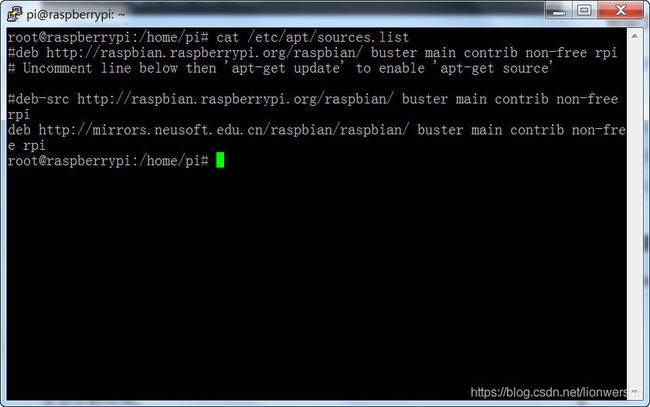
我的树莓派的系统是最新的树莓派官方系统buster,编辑list文件
nano /etc/apt/sources.list
注释掉官方源,添加国内的源,我添加的是东软源,添加好之后,按ctrl+x,输入Y,直接回车确认就行了。
#deb http://raspbian.raspberrypi.org/raspbian/ buster main contrib non-free rpi
deb http://mirrors.neusoft.edu.cn/raspbian/raspbian/ buster main contrib non-free rpi
执行一下,更新源操作。
apt-get source && apt-get update
2.安装依赖环境,先更新一下系统。
apt-get upgrade
安装依赖环境。
sudo apt-get install python3-pyaudio
sudo apt-get install swig
sudo apt-get install libatlas-base-dev
apt-get install pulseaudio
apt-get install sox
apt-get install alsa-utils
插入usb声卡,查看当前是否有录音设备。
arecord -l
出现了usb声卡编号,card1
**** List of CAPTURE Hardware Devices ****
card 1: Device [USB Audio Device], device 0: USB Audio [USB Audio]
Subdevices: 0/1
Subdevice #0: subdevice #0
查看当前的播放设备
aplay -l
列出了当前的所有设备。
**** List of PLAYBACK Hardware Devices ****
card 0: ALSA [bcm2835 ALSA], device 0: bcm2835 ALSA [bcm2835 ALSA]
Subdevices: 7/7
Subdevice #0: subdevice #0
Subdevice #1: subdevice #1
Subdevice #2: subdevice #2
Subdevice #3: subdevice #3
Subdevice #4: subdevice #4
Subdevice #5: subdevice #5
Subdevice #6: subdevice #6
card 0: ALSA [bcm2835 ALSA], device 1: bcm2835 IEC958/HDMI [bcm2835 IEC958/HDMI]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 0: ALSA [bcm2835 ALSA], device 2: bcm2835 IEC958/HDMI1 [bcm2835 IEC958/HDMI1]
Subdevices: 1/1
Subdevice #0: subdevice #0
card 1: Device [USB Audio Device], device 0: USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
新建 ~/.asoundrc文件,并添加如下内容,注意card的编号,是前面的usb声卡的编号。
pcm.!default {
type asym
playback.pcm {
type plug
slave.pcm "hw:0,0"
}
capture.pcm {
type plug
slave.pcm "hw:1,0"
}
}
ctl.!default {
type hw
card 1
}
录一段音频查看设备是否工作正常,我使用的是绿联的usb声卡,麦克风的插孔不要全部插入,要留一部分在外面,这样才可以正常工作,这一点非常重要!!!
rec test.wav
播放刚刚录制的音频,看看是否有杂音,可以通过alsamixer进行调节
aplay test.wav
播放录制的音频或者通过以下命令通过音箱听见你说话的声音。
sox -d -d
3.编译snowboy
下载snowboy源码
git clone https://github.com/Kitt-AI/snowboy.git
cd snowboy/swig
进入目录之后选择你要编译的语言,选择哪门语言进入对应的目录,我选择Python3,进入之后直接make进行编译
make
编译成功之后,进入snowboy目录下的examples中运行对应语言的例子
python3 demo.py resources/models/snowboy.umdl
运行官方的demo,并指定官方的语音模型,可以在网站上登录之后使用自定义的模型,但是受限于录音设备,效果一般。
官网地址
4.解决报错
1.官方的python例子中有一个导入的错误,在同一目录下的snowboydecoder.py文件中
from * import snowboydetect 改为 import snowboydetect 就可以运行了
2.OSError: [Errno -9997] Invalid sample rate 采样率无效的问题,这里只要把安装好的pulseaudio启动一下就可以了。
pulseaudio --start
在root用户下启动会报错,但是没有问题可以运行,只是提示权限的问题,
我们也可以将它加入到/etc/systemd/system/pulseaudio.service中去,确保它能在重新启动后继续工作:
[Unit]
Description=PulseAudio Sound System
Before=sound.target
[Service]
BusName=org.pulseaudio.Server
ExecStart=/usr/bin/pulseaudio
Restart=always
[Install]
WantedBy=session.target
3.在demo中要修改一个参数,不然还是会报错。
detector.start(detected_callback=snowboydecoder.play_audio_file,
interrupt_check=interrupt_callback,
sleep_time=0.3)
把sleep_time从0.03改为0.3才可以,这样一来就可以了。
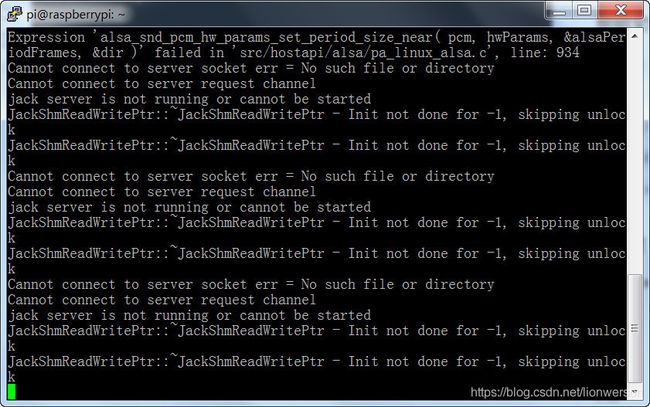
alsa的报错可以忽略,JackShmReadWritePtr好像是一个音频驱动,不用管。
对着麦克风说出snowboy就可以听见叮叮的声音,就成功了,并输出下面的信息,我的输出音箱接在usb声卡的输出口,才听到提示音。
INFO:snowboy:Keyword 1 detected at time:
修改响应
可以在官方的demo中修改detected_callback参数之后的函数进行自定义,官方也有demo可以实现用语音控制gpio引脚的例子。
import snowboydecoder
import sys
import signal
interrupted = False
def signal_handler(signal, frame):
global interrupted
interrupted = True
def interrupt_callback():
global interrupted
return interrupted
if len(sys.argv) == 1:
print("Error: need to specify model name")
print("Usage: python demo.py your.model")
sys.exit(-1)
model = sys.argv[1]
# capture SIGINT signal, e.g., Ctrl+C
signal.signal(signal.SIGINT, signal_handler)
detector = snowboydecoder.HotwordDetector(model, sensitivity=0.5)
print('Listening... Press Ctrl+C to exit')
# main loop
detector.start(detected_callback=snowboydecoder.play_audio_file,
interrupt_check=interrupt_callback,
sleep_time=0.03)
detector.terminate()
好像还可以通过snowboy通过文字转语音进行识别,但是百度的语音接口好像不支持,再研究研究吧。