cs231n 2018系列笔记(lecture7)
所有内容
![]()
slides地址
链接: https://pan.baidu.com/s/12zGt_kYd5Jj8jq5EygS35A 密码: hd57
batchnorm及其演变
1.普通batchnorm公式,请注意维度,后面会用到

2.test时batchnorm公式
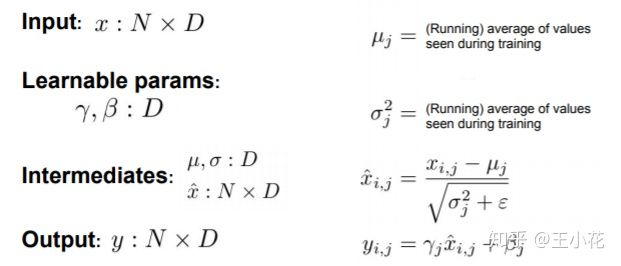
均值和方差用train时候的不需要训练,其他不变
3.全连接层和卷积层的batchnorm

除了第二维其他都为1
4.layer normalization(arxiv, 2016)
左边的是batchnorm,两者对比发现μ和sigmoid维度改了,变成了对每个批次求均值
5.instance normalization(cvpr 2017)
是对卷积操作,不过更操作更细致
6 .group normlization(arxiv 2018)及可视化对比图
可以看到group是对layer norm 与 instance norm的折衷
7.Decorrelated Batch Normalization(arXiv 2018,业界良心4月份的论文都上了)
相比batchnorm能够让处理后的数据体现更好的相关联性
代码实现(占坑,只写一下前向传播)
Optimization
SGD:下降较慢,可能遇到鞍点,梯度接近0的时候几乎停滞,并且14年的论文提出高维的时候会有更多的鞍点。由于梯度也是小批量取样,所以梯度会引入噪声。
不是很理解为什么梯度取minibatches会有噪声
SGD改进型:SGD+Momentum(ICML 2013)
SGD方法的一个缺点是,其更新方向完全依赖于当前的batch,因而其更新十分不稳定。解决这一问题的一个简单的做法便是引入momentum。
momentum即动量,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,能够很好的解决鞍点和局部最小值的问题
杜客:CS231n课程笔记翻译:神经网络笔记3(下)zhuanlan.zhihu.com
关于写法问题,吴恩达的写法推荐是
更易理解,通常的做法是拿掉(1-beta),但是之前的beta=beta/(1-beta),α也要随之改变
另外两种ppt里面的写法是等价的,区别在于第一种ρ为负,并且减少了一次乘法运算,速度几乎没有区别,第二种ρ为正
Nesterov+Momentum 的区别在于比 SGD+momentum 多减去了α*grad(ρ*vt)
帐号登录blog.csdn.net
以上的都是人工设置学习率,总还是有些生硬,接下来介绍几种自适应学习率的方法。
ycszen:深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)zhuanlan.zhihu.com
Adam是之前的结合
优化方法
神经网络的训练可以采用二阶优化方法吗(如Newton, Quasi Newton)?www.zhihu.com
由于二阶优化计算量过大,deeplearning一般采用一阶优化,但对于浅层模型效果和精度都不错,一阶是梯度下降,二阶线性拟合和梯度都有
建议:
默认使用Adam, SGD+Momentum调节好学习率之后通常比Adam效果好一点。深度学习不建议二阶优化算法。
model ensembles(模型融合)
SGDR - 搜索结果 - 知乎www.zhihu.com
Loshchilov and Hutter, “SGDR: Stochastic gradient descent with restarts”, arXiv 2016
提高单个模型的表现可以引入
1.正则化
2.dropout
3.数据加入噪声
4.数据增强,图片加上transform之类的操作
一个比较好的处理应该如下,训练加噪,测试去噪,中间加入examples的操作
最下面的Stochastic Depth Pytorch代码实现
吴明昊:Deep Networks with Stochastic Depthzhuanlan.zhihu.com
Transfer Learning
从上往下,如果是小数据集,只改最顶端的Fc-1000,如果是大数据集,需要改动更多层,才能更具通用性。(一般weight都是来自imagenet),下图是对比。