深度学习常用评价指标
评价指标:
准确率 (Accuracy),混淆矩阵 (Confusion Matrix),精确率(Precision),召回率(Recall),平均正确率(AP),mean Average Precision(mAP),交除并(IoU),ROC
1、准确率 (Accuracy)
分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
2、混淆矩阵 (Confusion Matrix)
混淆矩阵中的横轴是模型预测的类别数量统计,纵轴是数据真实标签的数量统计。
对角线,表示模型预测和数据标签一致的数目,所以对角线之和除以测试集总数就是准确率。对角线上数字越大越好,在可视化结果中颜色越深,说明模型在该类的预测准确率越高。如果按行来看,每行不在对角线位置的就是错误预测的类别。总的来说,我们希望对角线越高越好,非对角线越低越好。
3、精确率(Precision)与召回率(Recall)
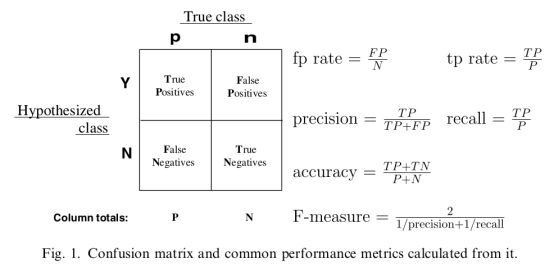
一些相关的定义。假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
- True positives : 正样本被正确识别为正样本,飞机的图片被正确的识别成了飞机。
- True negatives: 负样本被正确识别为负样本,大雁的图片没有被识别出来,系统正确地认为它们是大雁。
- False positives: 假的正样本,即负样本被错误识别为正样本,大雁的图片被错误地识别成了飞机。
- False negatives: 假的负样本,即正样本被错误识别为负样本,飞机的图片没有被识别出来,系统错误地认为它们是大雁。
Precision其实就是在识别出来的图片中,True positives所占的比率。也就是本假设中,所有被识别出来的飞机中,真正的飞机所占的比例。
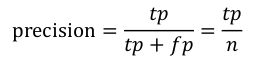
Recall 是测试集中所有正样本样例中,被正确识别为正样本的比例。也就是本假设中,被正确识别出来的飞机个数与测试集中所有真实飞机的个数的比值。

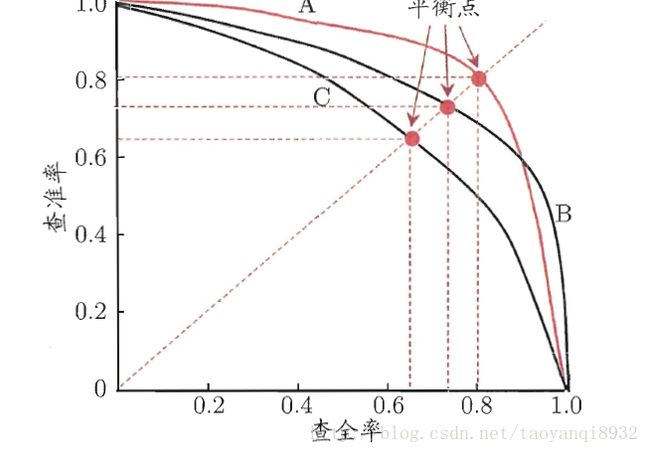
Precision-recall 曲线:改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到曲线。
如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
4、平均精度(Average-Precision,AP)与 mean Average Precision(mAP)
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
在正样本非常少的情况下,PR表现的效果会更好。
5、IoU
IoU这一值,可以理解为系统预测出来的框与原来图片中标记的框的重合程度。 计算方法即检测结果Detection Result与 Ground Truth 的交集比上它们的并集,即为检测的准确率。
IOU正是表达这种bounding box和groundtruth的差异的指标:

6、ROC(Receiver Operating Characteristic)曲线与AUC(Area Under Curve)

ROC曲线:
- 横坐标:假正率(False positive rate, FPR),FPR = FP / [ FP + TN] ,代表所有负样本中错误预测为正样本的概率,假警报率;
- 纵坐标:真正率(True positive rate, TPR),TPR = TP / [ TP + FN] ,代表所有正样本中预测正确的概率,命中率。
对角线对应于随机猜测模型,而(0,1)对应于所有整理排在所有反例之前的理想模型。曲线越接近左上角,分类器的性能越好。
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
ROC曲线绘制:
(1)根据每个测试样本属于正样本的概率值从大到小排序;
(2)从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本;
(3)每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
AUC(Area Under Curve)即为ROC曲线下的面积。AUC越接近于1,分类器性能越好。
物理意义:首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
计算公式:就是求曲线下矩形面积。
