目标检测总结 Object Detection Summary
最近研究CV,看了几篇颇为重要的论文:
RCNN->SPPnet->Fast RCNN->Hyper Net->Faster RCNN->R-FCN->Mask RCNN
看了很多文章,分析得非常透彻,现在就这几篇总结一下,同时给自己顺下思路(观点雷同敬请谅解,如有侵权请联系)
RCNN算法流程
SS+wrap+VGG16+SVM+BBox
步骤:
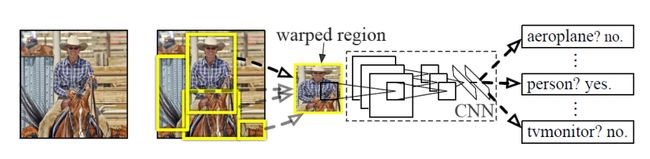
1)采用SelectiveSearch算法生成ROI(候选区域),一张图片大约生成2000个ROI,但由于ROI尺寸大小不一,warp(拉伸)到227*227.(全连接层的神经元设定之后是固定的,而每一个都对着一个特征,rg大神在进入CNN前对图片进行warp处理,就是为了卷积之后的特征数,能够和了全连接层的神经元个数相等)
2)把每个 ROI 送入CNN,提取特征。(CNN模型训练有两步组成:1在ImageNet上的预训练,2在检测数据上的微调)
3) 对候选框中提取出的特征,使用SVM分类器判别是否属于一个特定类
4) 对于属于某一特征的ROI,用BBox回归校正原来的ROI,生成预测窗口的坐标(基于前一步的输出结果)
SPPNet 算法流程:
SS+VGG16+SPPNet+SVM+Bbox
改进:
针对生成特征向量的尺寸大小问题,取消wrap
步骤:
1)提取ROI候选区域,和RCNN的第一步没变,还是2000个ROI
2)CNN对整幅图像提取卷积特征,这个输出对应是整幅图的卷积特征
3)结合1)、2)输出结果使用 SPP layer (Spatial Pyramid PoolingLayer),把每个ROI候选区域对应固定尺寸的特征向量
文中指出如果用4级空间金字塔, (1×1, 2×2, 3×3, 6×6, totally 50 bins),会产生一个 12,800维 (256×50)向量
2,3步是与RCNN最大的差别
4)固定尺寸的特征向量输入FC层进行分类。
5)对候选框中提取出的特征,使用SVM分类器判别是否属于一个特定类
6)对于属于某一特征的ROI,用BBox回归校正原来的ROI,生成预测窗口的坐标(基于前一步的输出结果)
RCNN和SPP-net的对比
SPP(spatial pyramid pooling)解释:
何凯明提出将最后一层特征图进一步处理,然后拼凑成和神经元个数相同的特征数,这样不用warp图片大小就获得相同数量的特征

如上图所示:
经过卷积网络后,得到最后的特征图feature A,然后我们使用三层的金字塔池化层pooling,分别设置图片切分成多少块,论文中设置的分别是(1,4,16),然后按照层次对这个特征图feature A进行分别处理(用代码实现就是for(1,2,3层)),也就是在第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,然后使用对应的大小的池化核对其进行池化得到4个特征
第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,然后使用对应大小的池化核对其进行池化得到16个特征
然后,将这1+4+16=21个特征输入到全连接层,进行权重计算. 当然了,这个层数是可以随意设定的,以及这个图片划分也是可以随意的,只要效果好同时最后能组合成我们需要的特征个数即可
SPPnet另一个改进点:
何大神觉得,如果对ss提供的2000多个候选区域都逐一进行卷积处理,势必会耗费大量的时间,所以他觉得,能不能我们先对一整张图进行卷积得到特征图,然后再将ss算法提供的2000多个候选区域的位置记录下来,通过比例映射到整张图的feature map上提取出候选区域的特征图B,然后将B送入到金字塔池化层中,进行权重计算.
经过尝试,这种方法是可行的,于是在RCNN基础上,进行了这两个优化得到了这个新的网络sppnet.
值得一提的是,sppnet提出的这种金字塔池化来实现任意图片大小进行CNN处理的这种思路,得到了大家的广泛认可,以后的许多模型,或多或少在这方面都是参考了这种思路,就连rg在后来提出的fast-rcnn上也是受益于这种思想的启发.
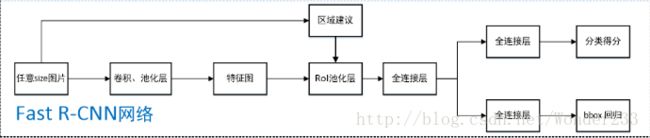
Fast RCNN算法流程:
Ss+VGG16+ROI-pooling+Multi-Task(Softmax+Bbox)
改进:
- 相比R-CNN,用整张图提一次特征,再把ROI 映射到feature map上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了
- Bbox regression放进神经网络内部,与ROI分类合并成为了一个multi-task模型,实际实验证明,这两个任务能够共享卷积特征,并相互促进
步骤:
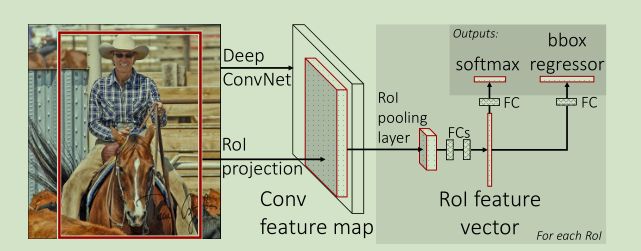
1)提取ROI候选区域,和RCNN的第一步没变,还是2000个ROI
2)把 整幅图像 输入CNN中特征提取
3)ROI pooling layer:找到每个ROI在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到ROI pooling生成固定大小的feature,方便传入后面的FC层(其实是单层的SPP layer,这里是借鉴了SPPNet中的 SPP网络层,比SPP网络层简单,只用一个尺度)
4)继续经过两个FC层,得到特征向量,RoI feature vector。
5)特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax分类,第二个是bounding box回归
RoI pooling layer 解释:
每一个RoI都由一个四元组(r,c,h,w)表示,其中(r,c)表示左上角位置,而(h,w)则代表高度和宽度。这一层使用最大池化(max pooling)将RoI区域转化成固定大小的 H*W 的特征图(H和W是取决于任何特定RoI层的超参数)。
RoI 最大池化通过将 h×w RoI窗口划分为 h / H × w / W个子窗口网格,子窗口大小固定为 H × W ,然后将每个子窗口中的值max pooling到相应的输出网格单元 。这是SPP pooling层的一个简化版,所以说ROIpooling是一个只有一层的“空间金字塔”(spp)
Hyper-Net:
改进:
hyper feature map把低层信息和高层信息融合为立方体,小物体的检测效果改善
ROI用RPG小型卷积网络生成,把ROI放进了神经网络当中
1、整张图片通过CNN提取特征
2、特取的特征进行融合得到Hyper Feature maps ,通过RPG生成候选区
3、生成的候选区和Hyper Feature maps一起进行目标检测

Hyper Feature Maps:
不同层提出了不同的采样策略。我们在层次较低的卷积层添加了最大池化层。对层次较高的卷积层,我们添加了一个反卷积操作(Deconv)来进行上采样。一个卷积层应用与每一个采样结果。卷积操作不仅提取了语义特征,还将它们压缩到一个统一的空间。最后,用LRN(localresponse normalization)归一化多个feature maps,并整合到一个立方体中,这个立方体就是Hyper Feature。
Faster-R-CNN算法:
VGG16/ZF+RPN+ROIpooling+Multi-Task(Softmax+Bbox)
改进:
使用RPN(Region Proposal Network)代替原来的Selective Search方法产生建议窗口
通过交替训练,使建议窗口RPN和目标检测Fast-RCNN网络共享参数。
步骤:
1、整张图片送入CNN,进行特征提取;(终于扔掉了2000个候选框,大快人心呐,看着就麻烦)
2、在最后一层卷积featuremap上,通过RPN生成ROI,每张图片大约300个建议窗口;(2000变300)
3、通过RoI pooling层使得每个建议窗口生成固定大小的feature map;
4、经过两个全连接层(FC),得到特征向量,RoI feature vector。
5、特征向量经由各自的FC层,得到两个输出向量, 第一个是分类,使用softmax,第二个是每一类的bounding box回归。


RPN(Region Proposal Network)解释:
RPN基于卷积神经网络,核心是Anchor机制,重点是通过anchors就引入了检测中常用到的多尺度方法,输出包含二类softmax和bbox回归的多任务模型
RPN工作流程:
1、在feature map上滑动窗口 ,Anchor是滑动窗口的中心,对于该图像的每一个位置,论文默认考虑9种可能的候选窗口,采3种尺度(128,256,512),3种长宽比(1:1,1:2,2:1),这些候选窗口称为anchors
2、滑动窗口的位置提供了物体的大体位置信息
3、建一个神经网络用于obj classify + box regress(obj classify确定框里有没有目标,box regress提供了更精确的位置)
Anchor:下图示出51*39个anchor中心(假设得到51*39的feature map),以及9种anchor示例。

anchors size,是根据检测图像设置的。在demo中,会把任意大小的输入feature map reshape成800x600。再回头来看anchors的大小,anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是cover了800x600的各个尺度和形状
9个anchors是做什么的呢?借用Faster RCNN论文中的原图,如下图,遍历Conv layers计算获得的feature maps,为每一个点都配备这9种anchors作为初始的检测框。这样做获得检测框很不准确,不用担心,后面还有2次bbox regression可以修正检测框位置,而且训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练

解释一下上面这张图的数字。
- 在原文中使用的是ZF model中,其Conv Layers中最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-d
- 在conv5之后,做了rpn_conv/3x3卷积且num_output=256,相当于每个点又融合了周围3x3的空间信息,同时256-d不变(如上图中的红框)
- 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates
- 此外,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练
引:CNN目标检测:Faster RCNN详解
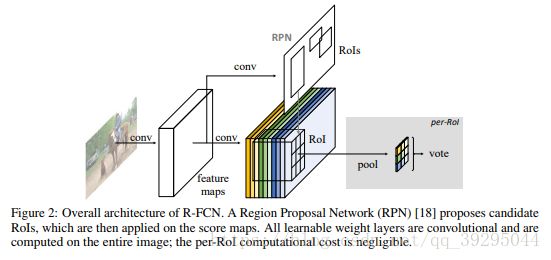
R-FCN算法:
ResNet-101+RPN+position sensitive score map+ROI pooling+vote+Softmax
改进:
FasterR-CNN的框架上进行改造,把提取特征的VGG16换了ResNet-101
引入position sensitive score map,把FastR-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROIpooling会丢失位置信息,故在pooling前加入位置信息,即指定不同scoremap是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息
步骤:
1、整张图片送入ResNet,进行特征提取。ps:去掉ResNet-101最后一层FC层,保留前100层,再接一个1*1*1024的conv层(100层输出是2048d,为了降维,引入了一个1*1的卷积层,则输出为1024d)
2、最后一层卷积featuremap,用区域建议网络(RPN)提出了RoIs,然后将其应用于position-sensitive score map上。这里k²(C+1) 个score map,其中,k²代表切分一个目标的相关位置的数量(比如,3²代表一个 3x3 的空间网格),C+1 代表 C 个类外加一个背景。
3、通过RoI pooling层使得每个ROI生成固定大小的score map;
4、k*k个框直接进行vote(每个类单独做)得到每一类的score
5、softmax得到每类的最终得分
 \
\
Position sensitive score map 解释:
k^2*(C+1)的conv层:上一步的ROI输出是W*H*1024,经过k^2*(C+1)的conv层得到channel=k^2*(C+1),大小为W*H的position sensitive score map。
举个栗子:k=3表示把一个ROI划分成3*3,表示分别预测9个位置(上左,上中,上右,中左,中中,中右,下左,下中,下右)包含(C+1)个物体的score。如下图所示,在3*3的区域内,每一个区域内都预测(C+1)类的得分,比如下图左上角的框预测的是可能是人这个类且是人的左上部位的score(也预测是其他C个类且是该类左上部位的score)。

ROI pooling: 输入是k*k*(C+1)*W' *H'(W'和H'是ROI的宽度和高度)的score map,输出为(C+1)*k*k大小的score map,然后k*k个框直接进行vote(每个类单独做)得到每一类的score,然后进行softmax得到每类的最终得分
FPN:
引:https://blog.csdn.net/u014380165/article/details/72890275