Forest数据分析及可视化
Forest数据分析及可视化
文章目录
- Forest数据分析及可视化
- 说在前面
- 1.导入csv数据集
- 2.分析种树种类
- 3.分析种树标签
- 4.种植树木的成功率
- 5.基于周和月的种树时间分析
- 6.总结
- 附源代码
说在前面
-
这次python作业是数据分析及可视化,这里我采用的是一个APP “Forest” ,从软件中导出 “Plants of forest.csv”,这是csv格式的数据集
-
Forest是一个让你规划时间,放下手机保持专注的APP,当需要专注的时候就种下一棵树并倒计时,时间结束,树就会长大,如果中途离开Forest,树就会枯死,最终所有种树记录都会保存,并且可以导出csv文件。
-
这里推荐一下Forest的官网,有需要的小伙伴可以去下载试试,可以提高学习效率。https://www.forestapp.cc/
下面是种树后的截图:(来源官网)

1.导入csv数据集
- 下面是我截取的部分csv数据集:

-
首先可以看出这里有StartTime(开始种树的时间)、EndTime(结束种树的时间)、Tag(标签,里面有"学习"、“休息”、"睡觉"等)、Note(自己设置的备注)、TreeType(每次种树的种类)、IsSuccess(是否种树成功)。
-
下面首先将该csv文件读进来,使用pandas中的read_csv()方法将其读进来保存到data中,之后可以用data[‘Tag’]取出标签这一列,其余列也是类似,这样就可以导入csv文件数据了。
data = pd.read_csv('Plants of forest.csv') tag = data['Tag']
2.分析种树种类
-
先对种树的种类进行分析:用
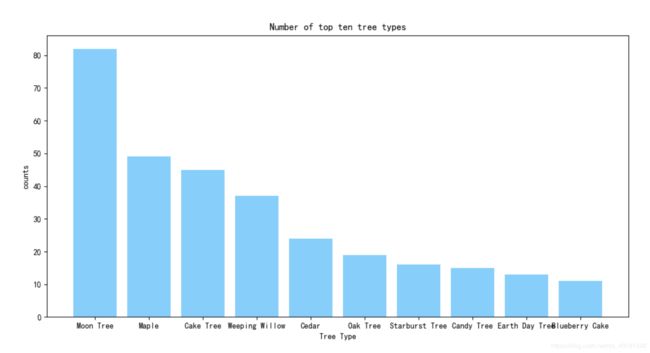
list(data[‘TreeType’])取出TreeType这一列数据并转化为列表,这里定义一个字典用来统计不同种类树的个数,遍历列表中每一个数据,使用count()方法统计个数并和该类型的种类组成一个键值对存到字典中,之后用sum(tree_dic.values)对种下的数目总数进行统计,并用sort方法对字典中树木类型的数量进行排序并打印输出。def tree_type_analyse(data): """分析种树种类""" tree_type = list(data['Tree Type']) tree_dic = {} for i in tree_type: tree_dic[i] = tree_type.count(i) tree_list = list(tree_dic.items()) tree_list.sort(key= lambda x:x[1], reverse=True) tree_type_count = len(tree_list) tree_count = sum(tree_dic.values()) sorted_tree = [] sorted_count = [] print('you have planted {0} trees, There are {1} types of trees'.format(tree_count, tree_type_count)) print ('\tTree Type \t\t\t counts') print ('=================================') for i in range(0, len(tree_list)): tree, count = tree_list[i] if i <= 9: sorted_tree.append(tree) sorted_count.append(count) print("{0:<30}{1:<5}".format(tree, count))下面是打印输出结果:
you have planted 433 trees, There are 40 types of trees Tree Type counts ================================= Moon Tree 82 Maple 49 Cake Tree 45 Weeping Willow 37 Cedar 24 Oak Tree 19 Starburst Tree 16 Candy Tree 15 Earth Day Tree 13 Blueberry Cake 11 Matcha Azuki Cake 11 Blue Oak Tree 10 Ginkgo 9 Pink Oak Tree 8 Sunflower 8 Four-Leaf Clover 7 Cherry Cheese Cake 6 Celestial Tree 6 Bush 5 Banana 5 Carnation 5 Rose 5 Tiramisu 4 Wisteria 4 Purple Oak Tree 4 Forest Spirit 4 Strawberry Chiffon Cake 3 Lemon Cake 2 Lemon Tree 2 Space Tree 2 Coconut Tree 2 Rainbow Flower 2 Black Forest Cake 1 Chocolate Strawberry Cake 1 Yellow Oak Tree 1 Cat-tail Willow 1 Blue Flower 1 Cherry Blossom 1 Flourishing Grass 1 Flower Tree 1 -
通过运行结果可以看到我一共种了433棵树,一共有40个种类,其中种植数量最多的是"Moon Tree"。
-
之后将前10的数目种类个数用直方图的形式绘制出来,这里就用到了plt.bar()方法绘制直方图。
plt.bar(sorted_tree,sorted_count,color='lightskyblue') plt.xlabel('Tree Type') plt.ylabel('counts') plt.title('Number of top ten tree types') plt.show()下面是绘制的种植数量前10的直方图结果:
3.分析种树标签
-
下面对树木的Tag和Time进行分析,观察我主要种树来做什么事情了分别用了多少时间,首先还是通过
list(data[‘Tag’])和list(data[‘Start Time’])、list(data[‘End Time’])获取这些标签的每一列数据。 -
之后定义
duration=[],用来存放每一次种树的持续时间,time1=[]和time2=[]用来存放每一次的起始时间和结束时间,这里我采用的计时单位是秒,之后遍历Strat Time 和 End Time,对其时间字符串进行split(’:’)分割成时分秒的形式,然后计算总秒钟,将两个time2和time1列表对应位相减就得到每一次种树的持续时间,存放到duration列表中。 -
接着和之前的方法一样定义一个dic_tag字典,遍历所有的Tag,将他们的持续时间加起来构成一个键值对存到字典中,然后打印出来该字典;其次我还使用了plt.pie()绘制出来不同Tag所对应时间的饼图。
def tree_tag_analyse(data): """分析种树标签""" tree_tag = list(data['Tag']) start_time = list(data['Start Time']) end_time = list(data['End Time']) duration = [] time1 = [] time2 = [] dic_tag = {} for i in start_time: x = i.split(' ')[3].split(':') time1.append(int(x[0])*60*60 + int(x[1])* 60 + int(x[2])) #print(time1) for i in end_time: x = i.split(' ')[3].split(':') time2.append(int(x[0])*60*60 + int(x[1])* 60 + int(x[2])) #print(time2) for i in range(0, len(time1)): if time1[i] > time2[i]: duration.append(24*60*60 - time1[i] + time2[i]) else: duration.append(time2[i] - time1[i]) #print(duration) total_duration = sum(duration) for i in range(0, len(duration)): if tree_tag[i] in dic_tag.keys(): dic_tag[tree_tag[i]] += duration[i]/60/60 else: dic_tag[tree_tag[i]] = duration[i]/60/60 print(dic_tag) explode=[0.01]*len(dic_tag.keys()) color = ['grey','salmon','lime','lightskyblue','gold','red','yellow','green','silver','pink'] plt.pie(dic_tag.values(),explode=explode,labels=dic_tag.keys(),autopct='%1.1f%%',colors=color) plt.title('Tag distribution') plt.show() return duration下面是输出的结果:
{'Unset': 0.46416666666666667, '学习': 188.2266666666667, '休息': 29.583333333333336, '睡觉': 323.9866666666667, '洗漱': 2.0572222222222223, '上课': 204.68583333333333, '运动': 6.833333333333336, '吃饭': 4.333333333333334, '其他': 3.8333333333333335, '工作': 11.0}

- 从输出结果可以看出我的时间基本用在了睡觉、学习、上课这三个方面,少部分用来休息、洗漱、运动、其他,这也反应了我平时的真实状况,学习和上课时间较多,运动时间少。这里睡觉用了323小时,学习用了188小时。
4.种植树木的成功率
-
之后我又对种植数目的成功率进行了统计,这里就用到数据的IsSuccess这一列数据,通过遍历该数据,统计True和False的个数,并将成功率进行打印输出。
def success_rate_analyse(data): """种植树木的成功率""" tree_is_success = list(data['Is Success']) success = tree_is_success.count(True) fail = tree_is_success.count(False) print('{0} trees were planted: {1} successful and {2} failed'.format(len(tree_is_success), success, fail)) print('the success rate is {0:.2f}%'.format(success/len(tree_is_success)*100))下面是输出的结果,可以发现一共种了433棵树,其中425棵成功了,8棵失败了,成功率高达98.15%。
433 trees were planted: 425 successful and 8 failed the success rate is 98.15%
5.基于周和月的种树时间分析
-
最后我又以月份为衡量单位和以周为衡量单位对我整体种树的时间进行了分析,这里依然是对Start Time和End Time中的字符串进行split,分理出月份和星期数,然后也是定义了两个字典分别来存储每一月的种植时间总数和每一星期的种植时间总数,由于方法和前面的类似,在此不再赘述。
def day_and_mouth_analyse(data, duration): """基于周和月的种树时间分析""" start_time = list(data['Start Time']) mouth = [] week = [] dic_mouth = {'Jan':0, 'Feb':0, 'Mar':0, 'Apr':0, 'May':0, 'Jun':0, 'Jul':0, 'Aug':0, 'Sep':0, 'Oct':0, 'Nov':0, 'Dec':0} dic_week = {'Mon':0, 'Tue':0, 'Wed':0, 'Thu':0, 'Fri':0, 'Sat':0, 'Sun':0,} for i in start_time: mouth.append(i.split(' ')[1]) week.append(i.split(' ')[0]) #print(mouth) #print(week) for i in range(0, len(mouth)): dic_mouth[mouth[i]] += duration[i]/60/60 dic_week[week[i]] += duration[i]/60/60 print(dic_mouth) print(dic_week) plt.subplot(1,2,1) plt.plot(dic_mouth.keys(), dic_mouth.values(),color='red',marker='o',markerfacecolor='blue') plt.xlabel('mouth') plt.ylabel('hour') plt.title('Month duration curve') plt.subplot(1,2,2) plt.plot(dic_week.keys(), dic_week.values(),color='blue',marker='o',markerfacecolor='red') plt.xlabel('week') plt.ylabel('hour') plt.title('Week duration curve') plt.show()下面是最终的输出结果:
#月份输出结果 {'Jan': 0, 'Feb': 49.416666666666664, 'Mar': 385.08722222222224, 'Apr': 286.83333333333337, 'May': 31.750000000000004, 'Jun': 3.75, 'Jul': 0, 'Aug': 0, 'Sep': 0, 'Oct': 0, 'Nov': 0, 'Dec': 18.166666666666668} #周输出结果 {'Mon': 129.18694444444446, 'Tue': 139.7863888888889, 'Wed': 118.59722222222223, 'Thu': 104.75, 'Fri': 88.0, 'Sat': 91.0, 'Sun': 103.68333333333334}下面是绘制的他们的折线图:
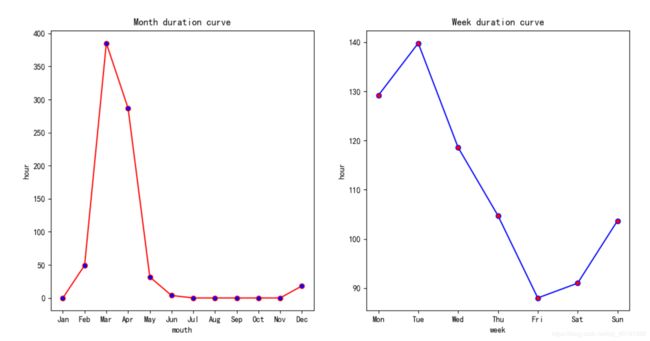
- 由折线图可以看出,我2、3、4、5月份种树花的时间最多,其余的月份较少,这是因为我用这个软件才刚刚几个月,所以其他月份没有记录,从每一周的统计结果来看,我在星期五和周末花的时间较少,这也比较符合我的正常生活规律,一般周末都没有课程,所以时间较少。
6.总结
- 以上就是我对“Plants of forest.csv”数据集的分析结果,整体来说还是比较符合实际的,也将里面各个标签的内容都一一做了分析。包括通过对时间的分析,我也知道了我的大部分时间都用到了哪里,也提醒我后面加强锻炼。
- 最后这个软件确实会提高自己的工作学习效率,减少看手机的时间,有需要的小伙伴可以试一下。
附源代码
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
def tree_type_analyse(data):
tree_type = list(data['Tree Type'])
tree_dic = {}
for i in tree_type:
tree_dic[i] = tree_type.count(i)
tree_list = list(tree_dic.items())
tree_list.sort(key= lambda x:x[1], reverse=True)
tree_type_count = len(tree_list)
tree_count = sum(tree_dic.values())
sorted_tree = []
sorted_count = []
print('you have planted {0} trees, There are {1} types of trees'.format(tree_count, tree_type_count))
print ('\tTree Type \t\t\t counts')
print ('=================================')
for i in range(0, len(tree_list)):
tree, count = tree_list[i]
if i <= 9:
sorted_tree.append(tree)
sorted_count.append(count)
print("{0:<30}{1:<5}".format(tree, count))
plt.bar(sorted_tree,sorted_count,color='lightskyblue')
plt.xlabel('Tree Type')
plt.ylabel('counts')
plt.title('Number of top ten tree types')
plt.show()
def tree_tag_analyse(data):
tree_tag = list(data['Tag'])
start_time = list(data['Start Time'])
end_time = list(data['End Time'])
duration = []
time1 = []
time2 = []
dic_tag = {}
for i in start_time:
x = i.split(' ')[3].split(':')
time1.append(int(x[0])*60*60 + int(x[1])* 60 + int(x[2]))
#print(time1)
for i in end_time:
x = i.split(' ')[3].split(':')
time2.append(int(x[0])*60*60 + int(x[1])* 60 + int(x[2]))
#print(time2)
for i in range(0, len(time1)):
if time1[i] > time2[i]:
duration.append(24*60*60 - time1[i] + time2[i])
else:
duration.append(time2[i] - time1[i])
#print(duration)
total_duration = sum(duration)
for i in range(0, len(duration)):
if tree_tag[i] in dic_tag.keys():
dic_tag[tree_tag[i]] += duration[i]/60/60
else:
dic_tag[tree_tag[i]] = duration[i]/60/60
print(dic_tag)
explode=[0.01]*len(dic_tag.keys())
color = ['grey','salmon','lime','lightskyblue','gold','red','yellow','green','silver','pink']
plt.pie(dic_tag.values(),explode=explode,labels=dic_tag.keys(),autopct='%1.1f%%',colors=color)
plt.title('Tag distribution')
plt.show()
return duration
def success_rate_analyse(data):
tree_is_success = list(data['Is Success'])
success = tree_is_success.count(True)
fail = tree_is_success.count(False)
print('{0} trees were planted: {1} successful and {2} failed'.format(len(tree_is_success), success, fail))
print('the success rate is {0:.2f}%'.format(success/len(tree_is_success)*100))
def day_and_mouth_analyse(data, duration):
start_time = list(data['Start Time'])
mouth = []
week = []
dic_mouth = {'Jan':0, 'Feb':0, 'Mar':0, 'Apr':0, 'May':0, 'Jun':0, 'Jul':0, 'Aug':0, 'Sep':0, 'Oct':0, 'Nov':0, 'Dec':0}
dic_week = {'Mon':0, 'Tue':0, 'Wed':0, 'Thu':0, 'Fri':0, 'Sat':0, 'Sun':0,}
for i in start_time:
mouth.append(i.split(' ')[1])
week.append(i.split(' ')[0])
#print(mouth)
#print(week)
for i in range(0, len(mouth)):
dic_mouth[mouth[i]] += duration[i]/60/60
dic_week[week[i]] += duration[i]/60/60
print(dic_mouth)
print(dic_week)
plt.subplot(1,2,1)
plt.plot(dic_mouth.keys(), dic_mouth.values(),color='red',marker='o',markerfacecolor='blue')
plt.xlabel('mouth')
plt.ylabel('hour')
plt.title('Month duration curve')
plt.subplot(1,2,2)
plt.plot(dic_week.keys(), dic_week.values(),color='blue',marker='o',markerfacecolor='red')
plt.xlabel('week')
plt.ylabel('hour')
plt.title('Week duration curve')
plt.show()
def test2():
data = pd.read_csv('Plants of forest.csv')
tree_type_analyse(data)
duration = tree_tag_analyse(data)
success_rate_analyse(data)
day_and_mouth_analyse(data,duration)
def main():
plt.rcParams['font.sans-serif']=['SimHei'] # 解决中文显示问题
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
test2()
if __name__ == '__main__':
main()