图像稀疏编码表示
注:本文学习自CVPR《Linear Spatial Pyramid Matching Using Sparse Coding
for Image Classification》、《Image classification By non-negative sparse coding, low-rank and sparse decomposition》及《基于稀疏编码的图像视觉特征提取及应用》
在提取完所有训练图像的SIFT特征后,需要对每幅图像进行视觉特征编码。视觉特征编码的目的在于对原始特征向量进行选择和变换,得到图像中最具表现力和区分度的视觉特征向量,使得计算机可以更高效的进行处理。一般编码方式是向量量化,另一种视觉编码方式稀疏编码能更好的表示图像。
1、向量量化
向量量化的基本思想是在基向量空间中寻找目标向量的最近邻,然后用该基向量的编号表示原目标向量:
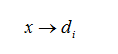
其中x为某个SIFT特征向量,di为基向量空间中的第i个向量。其实基向量就是对所有训练图像的所有SIFT特征向量进行聚类,得到的K个聚类中心,这K个特征向量最后作为基向量。然后对于每一幅图像,寻找每个SIFT特征向量属于哪个基向量,来进行映射。
在向量量化的过程中,基本步骤如下:
1) 将全部的训练样本进行归一化;
2) 对训练样本进行聚类,得到若干个类中心,构成基向量空间:
3) 在所有类中心中为目标向量寻找最近邻。
在BOW模型中,先聚类产生视觉关键词,然后进行向量量化编码。对于用SIFT特征

就是这幅图像的稀疏编码。
向量量化的优点在于计算简单,数据压缩率高,缺点在于精度损失比较大,在某些应用中难以满足要求。
2、稀疏编码
稀疏编码的本质是一个目标向量可以由少量的基向量经线性拟合而成,且基向量空间存在一定的冗余。与向量量化的区别是向量量化的每个目标向量只能由一个基向量表示。也就是说向量量化方式的约束条件太严格,会引起重构误差。二者区别可表示如下:
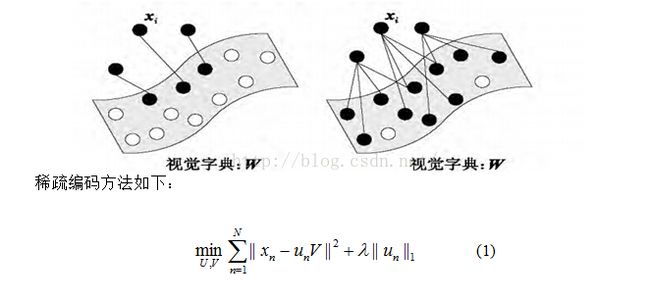

对图像的稀疏编码一般分为两个过程:
一是基向量的训练过程,也称为字典的学习。在这个过程中,我们利用大量的训练样本,通过无监督学习方法学习获得一组冗余的基向量,这组基向量通常反映了训练样本中一些带有本质特性的基元,如图像中的边界、角点,实验表明,字典的学习过程模拟了人类视觉皮层对信息的处理过程。
最优化问题(1)变成了二次约束的最小二乘问题,即:
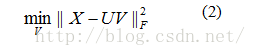
这个最优化问题,在给定X情况下,交替固定一个变量,训练另一个变量,如此迭代。
二是线性拟合的求解过程。即任意目标向量xn都可以由字典V内的若干个条目经线性组合拟合而成,该过程根据不同的约束条件,可以得到不同的拟合系数un,然后用该系数向量表示图像特征。
此时V已知,对图像X稀疏编码得到U,问题变为如下求解:
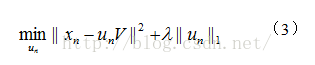
3、实验过程:
1、从每张图像中随机提取一个特征点向量,凑出一个初始训练样本X。(128*2600)
for ii = 1:2600
fpath = training.path{ii};
load(fpath);
num_fea = size(feaSet.feaArr, 2);
rndidx = randperm(num_fea);
X(:, ii) = feaSet.feaArr(:, rndidx(ii));
end;
2、视觉字典V的学习
a、初始视觉字典V通过随机函数给出,先随机产生一个128*300的矩阵作为初始视觉 字典
V = rand(128, 300)-0.5;%先随机生成一个视觉词典V
V = V - repmat(mean(V,1), size(V,1),1);
V = V*diag(1./sqrt(sum(V.*V)));
b、使用刚刚得到的V,对样本X计算得到U
U = L1QP_FeatureSign_Set(X, V, lambda);
此函数在已知训练样本X和给出的视觉字典V的前提下,学习得到此时样本的稀
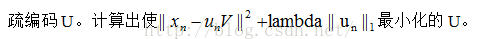
c、使用刚刚得到的U,再训练得到V
V = l2ls_learn_basis_dual(X, U, pars.VAR_basis);
此函数在已知训练样本X和样本稀疏编码U的前提下,学习得到V。在条件

d、迭代50次b和c过程,最终得到视觉词典V及训练样本X的稀疏编码U。
3、对每张图像,应用得到的视觉字典V,得到其稀疏编码U
4、如下代码用某种方式(sc_approx_pooling)对每幅图像的稀疏编码进行了处理,然后用21*300(300是视觉关键词的个数)维向量来表示这幅图像。以前是对向量量化编码U按关键词出现的频次计算直方图来表示这幅图像,现在改用最大池处理,即对于稀疏编码得到的U,Uij表示了第i块SIFT特征区域对第j个关键词的归属程度,取每个关键词中归属程度的最大值来表示这个关键词,得到K维特征向量来表示这幅图像。
sc_fea = zeros(6300, 2600);%%所有训练图像的稀疏编码
sc_label = zeros(2600, 1);
for iter1 = 1:2600,
fpath = database.path{iter1};
load(fpath);
%%对每张图像给出一个稀疏编码矩阵(这里需要对每张图片每金字塔层每个网格给出一个300*N的 稀疏编码矩阵,最后按 权值串联该幅图的所有稀疏编码作为最终稀疏编码来表示这幅图像)
sc_fea(:, iter1) = sc_approx_pooling(feaSet, V, pyramid, gamma);
sc_label(iter1) = database.label(iter1);
end;
总结一下,稀疏编码其实就是先对所有图像的所有SIFT特征进行训练,得到基向量也即视觉关键词V。之后对于每一幅图像,计算其每个特征点所属的基向量索引u,u中含有多个非零系数用来拟合多个基向量,得到一幅图像的系数编码U。用U乘以基向量V就能表示一幅图像X。之后再用方法(sc_approx_pooling)对每幅图像的稀疏表示U进行了处理,得到300(视觉关键词的个数)维向量来表示这幅图像。