使用DL4J读取词向量并计算语义相似度
使用DL4J读取词向量并计算单词语义相似度
By 龙前尘
实验环境:WINDOWS 8、Java-1.8.0_25、DL4J-0.9.1、ND4J-0.9.1
转载请注明地址:
http://blog.csdn.net/svenhuayuncheng/article/details/79073883
笔者按
在将词向量用于语义相似度计算时,如笔者前文所述:Windows系统下使用维基百科中文语料训练Word2Vec词向量,笔者已经利用Gensim训练好了词向量。由于笔者的项目工程是基于Java编写的,故需要找到相关的Java类库来读取词向量。经过一番查询,笔者锁定了DL4J(Deeplearning for Java)这个库,下文即使用DL4J来读取词向量的方法,以及笔者踩到的坑。
1. 何为DL4J
本文节选自DL4J官网1。
DeepLearning4J(DL4J)是一套基于Java语言的神经网络工具包,可以构建、定型和部署神经网络。DL4J与Hadoop和Spark集成,支持分布式CPU和GPU,为商业环境(而非研究工具目的)所设计。Skymind是DL4J的商业支持机构。
Deeplearning4j拥有先进的技术,以即插即用为目标,通过更多预设的使用,避免多余的配置,让非企业也能够进行快速的原型制作。DL4J同时可以规模化定制。DL4J遵循Apache 2.0许可协议,一切以其为基础的衍生作品均属于衍生作品的作者。
Deeplearning4j包括了分布式、多线程的深度学习框架,以及普通的单线程深度学习框架。定型过程以集群进行,也就是说,Deeplearning4j可以快速处理大量数据。神经网络可通过[迭代化简]平行定型,与 Java、 Scala 和 Clojure 均兼容。
2. 配置POM文件
DL4J配置如下:
<dependency>
<groupId>org.deeplearning4jgroupId>
<artifactId>deeplearning4j-coreartifactId>
<version>0.9.1version>
dependency>
<dependency>
<groupId>org.deeplearning4jgroupId>
<artifactId>deeplearning4j-nlpartifactId>
<version>0.9.1version>
dependency>
DL4J使用了ND4J来做矩阵计算,在配置时,也必须要配置ND4J,否则会报错。
ND4J配置如下:
<dependency>
<groupId>org.nd4jgroupId>
<artifactId>nd4j-native-platformartifactId>
<version>0.9.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.nd4jgroupId>
<artifactId>nd4j-nativeartifactId>
<version>0.9.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.nd4jgroupId>
<artifactId>nd4j-apiartifactId>
<version>0.9.1version>
dependency>3. 使用DL4J读取词向量
DL4J可以读取使用DL4J训练出的词向量,也可以读取使用Gensim训练出的词向量vector文件,此外,对于谷歌训练好的谷歌新闻语料模型GoogleNews-vectors-negative300.bin,也可以读取。
本文主要针对于第二种词向量文件的读取与操作。
首先为读取词向量文件,代码如下:
Word2Vec word2Vec = WordVectorSerializer.readWord2VecModel("wiki.zh.text.vector");读取文件后,可以将Word2vec作为查询表使用:
WeightLookupTable weightLookupTable = word2Vec.lookupTable();
Iterator vectors = weightLookupTable.vectors();
INDArray wordVectorMatrix = word2Vec.getWordVectorMatrix("农业");
double[] wordVector = word2Vec.getWordVector("农业"); 如果遇到未登录词,Word2vec返回一个全零向量。
试一试效果:
Collection lst = vec.wordsNearest("计算机", 10);
System.out.println(lst);
double cosSim = vec.similarity("农业", "计算机");
System.out.println(cosSim);
for(Double d : wordVector)
System.out.println(d); 4. 踩过的坑
4.1 堆外内存溢出问题
读取词向量的代码很简单,但是仍然遇到问题。
报错如下图所示:

该错误是堆外内存溢出导致。
这是由于DL4J使用了ND4J,该模块使用off-heap(堆外内存)来存储NDArray,并且对于原生代码(如BLAS、CUDA库)可以提供更好的性能2.
off-heap堆外内存指不由JVM维护的内存空间,故JVM的垃圾回收机制也不会管理对堆外内存。在JVM中,ND4J会维护指向堆外内存的指针,可以通过JNI将这些指针传递到ND4J底层的C++代码中,来完成ND4J操作。
为了维护内存空间的分配,ND4J使用了两种方法:
第一是通过JVM与弱引用追踪方法(WeakReference tracking);
第二是通过内存工作空间管理(MemoryWorkspaces)。
这两种方法的核心思想是一样的:即当一个INDArray数组被垃圾回收后,其对应的堆外内存应该被释放,并重新分配该内存空间。GC与MemoryWorkspaces不同之处在于何时、如何释放内存。
对于JVM,当INDArray数组被作为垃圾回收时,其对应的堆外内存被释放;
对于MemoryWorkspaces,当一个INDArray数组离开工作空间的范围时,比如,当神经网络中的一层已经完成了前馈传递,其内存可能会被重用,故不进行内存释放或重分配。这样对于循环神经网络来说性能更佳。
所以,无论用什么方法,在DL4J/ND4J中,有两种类型的内存限制都需要显示配置。堆内(on-heap)JVM内存,以及NDArray数组所在的堆外(off-heap)内存,都需要设置内存限制。
设置如下:
-Xms 当应用开始时,分配给应用的初始JVM堆的大小;
-Xmx 分配给应用的最大JVM堆的大小;
-Dorg.bytedeco.javacpp.maxbytes 堆外内存大小;
-Dorg.bytedeco.javacpp.maxphysicalbytes 同样为设置堆外内存的,应该设置地与maxbytes大小一样;
例如,设置堆内内存初始大小为1G,最大堆内内存为2G,最大堆外内存为8G,则有:
-Xms1G -Xmx2G -Dorg.bytedeco.javacpp.maxbytes=8G -Dorg.bytedeco.javacpp.maxphysicalbytes=8G
在IntelliJ IDEA中,需要在Run->Edit Configurations中设置VM参数。
设置如下图所示:
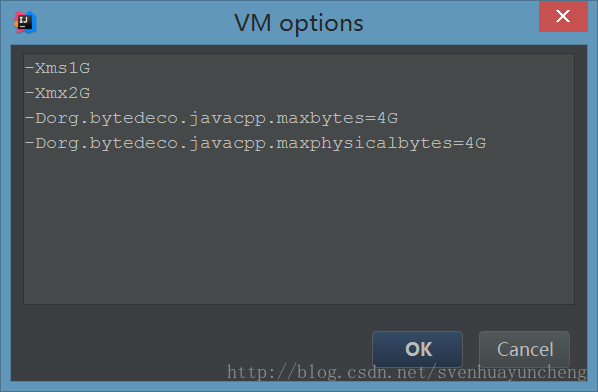
如此设置后,问题解决。
4.2 使用main函数缺少ND4J类库的问题
在WINDOWS操作系统下,用main函数读取词向量文件时,可能会遇到以下错误:
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.deeplearning4j.nn.conf.NeuralNetConfiguration$Builder.seed(NeuralNetConfiguration.java:624)
at org.deeplearning4j.examples.feedforward.anomalydetection.MNISTAnomalyExample.main(MNISTAnomalyExample.java:46)
Caused by: java.lang.RuntimeException: org.nd4j.linalg.factory.Nd4jBackend$NoAvailableBackendException: Please ensure that you have an nd4j backend on your classpath. Please see: http://nd4j.org/getstarted.html
at org.nd4j.linalg.factory.Nd4j.initContext(Nd4j.java:5556)
at org.nd4j.linalg.factory.Nd4j.(Nd4j.java:189)
... 2 more
Caused by: org.nd4j.linalg.factory.Nd4jBackend$NoAvailableBackendException: Please ensure that you have an nd4j backend on your classpath. Please see: http://nd4j.org/getstarted.html
at org.nd4j.linalg.factory.Nd4jBackend.load(Nd4jBackend.java:259)
at org.nd4j.linalg.factory.Nd4j.initContext(Nd4j.java:5553)
... 3 more该问题是由于操作系统无法加载某些必要的类库导致。这里可以使用Dependency Walker来解决问题。
1、 首先下载类库:Dependency Walker 2.2 for x64,并解压。
2、 引入类包:
import org.bytedeco.javacpp.Loader;
import org.nd4j.nativeblas.Nd4jCpu;3、在main()方法之前,或者在初始化对象之前,插入以下代码。
try {
Loader.load(Nd4jCpu.class);
} catch (UnsatisfiedLinkError e) {
String path = Loader.cacheResource(Nd4jCpu.class, "windows-x86_64/jniNd4jCpu.dll").getPath();
new ProcessBuilder("c:/path/to/depends.exe", path).start().waitFor();
}由此,解决了使用main方法运行程序出错的问题。
以上,完成了使用DL4J读取词向量的全过程。
本文旨在做一个实验记录,也是抛砖引玉,欢迎大家共同探讨!
- https://deeplearning4j.org/cn/index。 ↩
- https://deeplearning4j.org/memory。 ↩