mysql 基本语句使用
目录
group by 和 distinct的区别
GROUP BY 语法
FIND_IN_SET语法
left join
group_concat
row_number() over() 的使用
-
group by 和 distinct的区别
共同点: 去重
group by
select *
from
i_plc_procedure_record
where
updateTime > "2018-09-04 00:00:00"
group by
cProcedureIDdistinct:
distinct 字段需放在字段最前边, 要不然会报错, 去重
错误方法:
select cProcedureID,distinct updateTime from i_plc_procedure_record
报错如下:
select cProcedureID,distinct updateTime, Num from i_plc_procedure_record where updateTime > "2018-09-04 00:00:00" group by cProcedureID
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'distinct updateTime, Num from i_plc_procedure_record where updateTime > "2018-0' at line 3
正确使用方法:
select distinct cProcedureID, updateTime from i_plc_procedure_record
不同点: group by 的功能比distinct更加强大
group by 聚合函数,
-
GROUP BY 语法
SELECT
column_name, function(column_name)
FROM
table_name
WHERE
column_name operator value
GROUP BY
column_name;语句使用:
select
cProcedureID,
max(updateTime) as updateTime,
SUM(Num*unitPrice) as Money,
Num
from
i_plc_procedure_record
where
updateTime > "2018-09-04 00:00:00"
group by
cProcedureID在查询的过程中,有时库里单个用户的数据往往会存在很多条,当我们需要查询出用户的一条数据时(最大时间对应记录或最小时间对应记录)往往要写很复杂的子查询,而其实通过一个简单的方法就可以查询。
就是使用concat函数,就可以非常简单的查询出相应的记录。
SELECT
uuid(),
phone_no,
date_time
FROM
TABLE
WHERE
CONCAT(phone_no, date_time) IN (
SELECT
CONCAT(
phone_no,
min(date_time)
)
FROM
TABLE
WHERE
phone_no IS NOT NULL
GROUP BY
phone_no
)
AND phone_no IS NOT NULL
GROUP BY
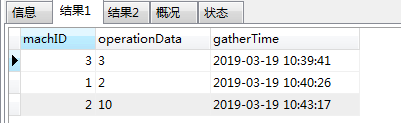
phone_no;所遇场景: 表中有machID, gatherTime字段, 现在需要查询表所有machID的时间gatherTime最近的一条记录:
表结构如下:

解决方案:
select
DISTINCT machID, operationData,gatherTime
from
dac_machine_stringdata
where
CONCAT(machID, gatherTime) in
(
select
CONCAT(machID, max(gatherTime))
from
dac_machine_stringdata
where
operationFlag=9 GROUP BY machID
);
结果如下:
-
FIND_IN_SET语法
mysql 语法:
FIND_IN_SET(str,strlist)
str 要查询的字符串
strlist 字段名 参数以”,”分隔 如 (1,2,6,8)
查询字段(strlist)中包含(str)的结果,返回结果为null或记录
FIND_IN_SET和IN 之间的关联
相同点
SELECT accessWebID
FROM i_plc_authority
where FIND_IN_SET(id,(select authorityID from i_plc_users where id =UserID))SELECT accessWebID
FROM i_plc_authority
where id in (select authorityID from i_plc_users where id =UserID)区别点
select *
from i_plc_product
where FIND_IN_SET("1", cInvName) and operationFlag=9 正常运行select *
from i_plc_product
where "1" in cInvName and operationFlag=9 报错[SQL] -- select * from i_plc_sfc_operation where operationFlag=9 order by opCode + 0
select * from i_plc_product where "1" in cInvName and operationFlag=9
[Err] 1064- You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'cInvName and operationFlag=9' at line 2-
left join
left join 和 where的区别
left join(1):
select w.OpSeq,c.WcName
from
technic1workcenter as w
left join (
select
WcName,
WcCode
from
i_plc_workcenter
where
operationFlag=9
) c
on
c.WcCode=w.WcCode
where
w.operationFlag=9
left join(2):
select w.OpSeq,c.WcName from technic1workcenter as w left join i_plc_workcenter c on c.WcCode=w.WcCode where w.operationFlag=9 and c.operationFlag=9
(一)查询的数据为什么比(二)多? 是因为technic1workcenter的数据没有与i_plc_workcenter关联, 但是在(二)中存在 where c.operationFlag=9, 导致直接过滤掉了
where类似于inner join:
select
w.OpSeq,
w.WcCode,
w.id,
c.WcName
from
technic1workcenter w,
i_plc_workcenter c
where
c.WcCode=w.WcCode and w.operationFlag=9 and c.operationFlag=9
-
group_concat
语法: group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
Select
GROUP_CONCAT(d.peoName) '所属人员(必须)'
From
i_plc_machine a
LEFT JOIN
(
select JobID,peoName
from i_plc_staff
where operationFlag = 9
) d on FIND_IN_SET(d.JobID,a.cPsn)
Where
a.operationFlag=9
GROUP BY a.id
Order By a.id;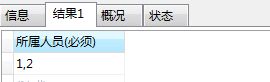
row_number() over() 的使用
统计topN
//sql 风格
val ranksql = "select key,value,row_number() over(partition by key order by value desc) as rank from tmp having rank <3"
spark.sql(ranksql).show()
/**
* +---+-----+----+
* |key|value|rank|
* +---+-----+----+
* | cc| 49| 1|
* | cc| 34| 2|
* | bb| 67| 1|
* | bb| 44| 2|
* | aa| 49| 1|
* | aa| 36| 2|
* +---+-----+----+
*/