XXL_JOB分布式任务调度平台
前言
Github:https://github.com/HealerJean
博客:http://blog.healerjean.com
官方地址:分布式任务调度平台XXL-JOB
1、下载部署
1.1、下载
https://github.com/xuxueli/xxl-job
1.2、部署
1.2.1、目录结构:
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-spring:Spring版本,通过Spring容器管理执行器,比较通用;
:xxl-job-executor-sample-frameless:无框架版本;
:xxl-job-executor-sample-jfinal:JFinal版本,通过JFinal管理执行器;
:xxl-job-executor-sample-nutz:Nutz版本,通过Nutz管理执行器;
:xxl-job-executor-sample-jboot:jboot版本,通过jboot管理执行器;
1.2、SpringBoot选择
除了SpringBoot,其他的对我来说没有用,删掉其他的,我只保留的SpringBoot

1.2.1、调度中心
统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台。
1.2.1.1、properties
### web
server.port=8080
server.servlet.context-path=/xxl-job-admin
### actuator
management.server.servlet.context-path=/actuator
management.health.mail.enabled=false
### resources
spring.mvc.servlet.load-on-startup=0
spring.mvc.static-path-pattern=/static/**
spring.resources.static-locations=classpath:/static/
### freemarker
spring.freemarker.templateLoaderPath=classpath:/templates/
spring.freemarker.suffix=.ftl
spring.freemarker.charset=UTF-8
spring.freemarker.request-context-attribute=request
spring.freemarker.settings.number_format=0.##########
### mybatis
mybatis.mapper-locations=classpath:/mybatis-mapper/*Mapper.xml
#mybatis.type-aliases-package=com.xxl.job.admin.core.model
### datasource-pool
spring.datasource.type=com.zaxxer.hikari.HikariDataSource
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=30
spring.datasource.hikari.auto-commit=true
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.pool-name=HikariCP
spring.datasource.hikari.max-lifetime=900000
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.connection-test-query=SELECT 1
### 调度中心JDBC链接:链接地址请保持和 2.1章节 所创建的调度数据库的地址一致
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.163.com
spring.mail.port=25
[email protected]
spring.mail.password=Zhangyj..123
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
1.2.2:执行器项目
作用:负责接收“调度中心”的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
12.2.1、properties
# web port
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### 调度中心部署跟地址 [选填]:
# 如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;XxlJobConfig
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
# 这里相当的重要,和上面应用的端口不同,也就是执行器通过下面的端口进行服务
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
1.3、启动:
1.3.1、启动调度中心:xxl-job-admin
http://127.0.0.1:8080//xxl-job-admin
“admin/123456

2、定时器介绍
2.1、配置属性

2.1.1、执行器
任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置;
2.1.2、 任务描述
任务的描述信息,便于任务管理;

2.1.3、路由策略
当执行器集群部署时,提供丰富的路由策略,包括;
| FIRST(第一个) | 固定选择第一个机器; |
| LAST(最后一个) | 固定选择最后一个机器; |
| ROUND(轮询) | |
| RANDOM(随机) | 随机选择在线的机器 |
| CONSISTENT_HASH(一致性HASH) | 每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。 |
| LEAST_FREQUENTLY_USED(最不经常使用): | 使用频率最低的机器优先被选举; |
| LEAST_RECENTLY_USED(最近最久未使用) | 最久未使用的机器优先被选举 |
| FAILOVER(故障转移) | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度; |
| BUSYOVER(忙碌转移) | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度; |
| SHARDING_BROADCAST(分片广播) | 广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务; |
2.1.4、Cron
触发任务执行的Cron表达式;
2.1.5、运行模式
| BEAN模式 | 任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务; |
|---|---|
| GLUE模式 | 任务以源码方式维护在调度中心;任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务; |
| GLUE模式(Java) | 该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务; |
| GLUE模式(Shell) | 该模式的任务实际上是一段 “shell” 脚本; |
| GLUE模式(Python) | 该模式的任务实际上是一段 “python” 脚本; |
| GLUE模式(PHP) | 该模式的任务实际上是一段 “php” 脚本; |
| GLUE模式(NodeJS) | 该模式的任务实际上是一段 “nodejs” 脚本; |
| GLUE模式(PowerShell) | 该模式的任务实际上是一段 “PowerShell” 脚本; |
2.1.6、JobHandler
运行模式为 “BEAN模式” 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
2.1.7、阻塞处理策略
调度过于密集执行器来不及处理时的处理策略;
如果当前任务还没执行完成,又来了任务的处理策略 。我们一定要尽可能避免此类情况
| 阻塞处理策略 | |
|---|---|
| 单机串行(默认) | 调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行; |
| 丢弃后续调度 | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败; |
| 覆盖之前调度 | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务; |
2.1.9、子任务Id
每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
2.1.10、任务超时时间
支持自定义任务超时时间,任务运行超时将会主动中断任务,同下面调度日志里面的终止任务;
2.1.11、失败重试次数
支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
2.1.12、负责人
任务的负责人;
2.1.13、报警邮件
任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
2.1.14、执行参数
任务执行所需的参数
3、BEAN模式
任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务
3.1、方法形式
3.1.1、执行器项目
package com.xxl.job.executor.service.jobhandler.bean;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
/**
* XxlJob开发示例(Bean模式)
*
* 开发步骤:
* 1、在Spring Bean实例中,开发Job方法,方式格式要求为 "public ReturnT execute(String param)"
* 2、为Job方法添加注解 "@XxlJob(value="自定义jobhandler名称", init = "JobHandler初始化方法", destroy = "JobHandler销毁方法")",注解value值对应的是调度中心新建任务的JobHandler属性的值。
* 3、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志;
*/
@Component
@Slf4j
public class BeanMethodXxlJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public ReturnT<String> demoJobHandler(String param) throws Exception {
log.info("任务【demoJobHandler】开始执行, 请求参数:{}", param);
//任务调度器日志
XxlJobLogger.log("XXL-JOB, 请求参数:{}", param);
return ReturnT.SUCCESS;
}
/**
* 2、生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑;
*/
@XxlJob(value = "demoJobHandler2", init = "init", destroy = "destroy")
public ReturnT<String> demoJobHandler2(String param) throws Exception {
log.info("任务【demoJobHandler2】开始执行, 请求参数:{}", param);
//任务调度器日志
XxlJobLogger.log("XXL-JOB, Hello World.");
return ReturnT.SUCCESS;
}
public void init() {
log.info("任务【demoJobHandler2】开始执行 init");
}
public void destroy() {
log.info("任务【demoJobHandler2】开始执行 destroy");
}
}
3.1.2、调度中心页面操作
3.1.2.1、demoJobHandler
0 */1 * * * ? 每分钟执行一次


3.1.2.2、demoJobHandler2


4、GLUE(java)模式
任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
4.1、GLUE模式(Java)
4.1.1、glueJobHandle
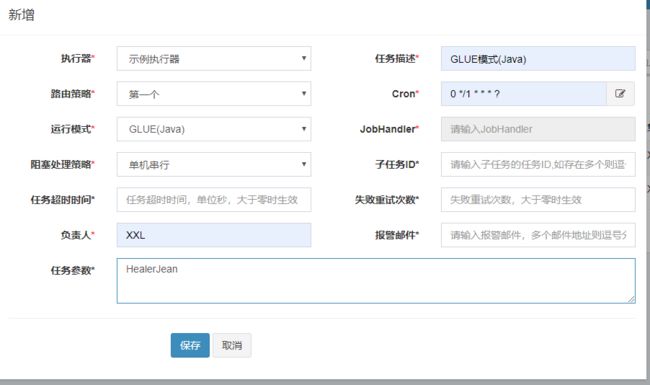
4.1.1.1、创建
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jp2MWFgF-1591086758306)(https://raw.githubusercontent.com/HealerJean/HealerJean.github.io/master/blogImages/image-20200514173938394.png)]
package com.xxl.job.service.handler;
import com.xxl.job.core.log.XxlJobLogger;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
public class DemoGlueJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
XxlJobLogger.log("GlueJob 请求参数:{}", param);
return ReturnT.SUCCESS;
}
}

4.1.1.2、查看日志

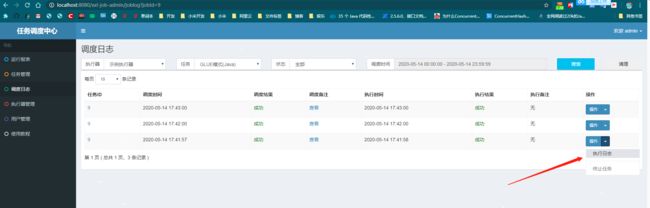
2020-05-14 17:41:57 [com.xxl.job.core.thread.JobThread#run]-[124]-[Thread-19]
----------- xxl-job job execute start -----------
----------- Param:HealerJean
2020-05-14 17:41:57 [com.xxl.job.core.handler.impl.GlueJobHandler#execute]-[26]-[Thread-19] ----------- glue.version:1589449244000 -----------
2020-05-14 17:41:57 [sun.reflect.NativeMethodAccessorImpl#invoke0]-[-2]-[Thread-19] GlueJob 请求参数:HealerJean
2020-05-14 17:41:57 [com.xxl.job.core.thread.JobThread#run]-[164]-[Thread-19]
----------- xxl-job job execute end(finish) -----------
----------- ReturnT:ReturnT [code=200, msg=null, content=null]
2020-05-14 17:41:57 [com.xxl.job.core.thread.TriggerCallbackThread#callbackLog]-[191]-[xxl-job, executor TriggerCallbackThread]
----------- xxl-job job callback finish.
[Load Log Finish]
5、操作指南
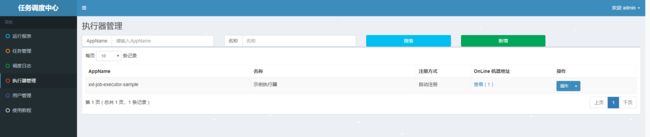
5.1、执行器管理
AppName: 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
名称:执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
排序:执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
注册方式:调度中心获取执行器地址的方式
1、自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址
2、手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;`
5.2、调度日志

调度时间:"调度中心"触发本次调度并向"执行器"发送任务执行信号的时间;
调度结果:"调度中心"触发本次调度的结果,200表示成功,500或其他表示失败;
调度备注:"调度中心"触发本次调度的日志信息;
任务触发类型:失败重试触发
调度机器:10.236.150.223
执行器-注册方式:自动注册
执行器-地址列表:[http://10.236.150.223:9999/]
路由策略:第一个
阻塞处理策略:单机串行
任务超时时间:0
失败重试次数:3
>>>>>>>>>>>触发调度<<<<<<<<<<<
触发调度:
address:http://10.236.150.223:9999/
code:200
msg:null
执行时间:"执行器"中本次任务执行结束后回调的时间;
执行结果:"执行器"中本次任务执行的结果,200表示成功,500或其他表示失败;
执行备注:"执行器"中本次任务执行的日志信息
操作:
1、"执行日志"按钮:点击可查看本地任务执行的详细日志信息;详见“4.8 查看执行日志”;

2、"终止任务"按钮:仅针对执行中的任务。在任务日志界面,点击右侧的“终止任务”按钮,将会向本次任务对应的执行器发送任务终止请求,将会终止掉本次任务,同时会清空掉整个任务执行队列。
任务终止时通过 “interrupt” 执行线程的方式实现, 将会触发 “InterruptedException” 异常。因此如果JobHandler内部catch到了该异常并消化掉的话, 任务终止功能将不可用。
因此, 如果遇到上述任务终止不可用的情况, 需要在JobHandler中应该针对 “InterruptedException” 异常进行特殊处理 (向上抛出) , 正确逻辑如下:
try{
// do something
} catch (Exception e) {
if (e instanceof InterruptedException) {
throw e;
}
logger.warn("{}", e);
}
而且,在JobHandler中开启子线程时,子线程也不可catch处理”InterruptedException”,应该主动向上抛出。
任务终止时会执行对应JobHandler的”destroy()”方法,可以借助该方法处理一些资源回收的逻辑。
5.3、用户管理
管理员:拥有全量权限,支持在线管理用户信息,为用户分配权限,权限分配粒度为执行器;
普通用户:仅拥有被分配权限的执行器,及相关任务的操作权限;

6、总体设计
6.1、源码目录介绍
- /doc :文档资料
- /db :“调度数据库”建表脚本
- /xxl-job-admin :调度中心,项目源码
- /xxl-job-core :公共Jar依赖
- /xxl-job-executor-samples :执行器,Sample示例项目(大家可以在该项目上进行开发,也可以将现有项目改造生成执行器项目)
6.2、调度数据库
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
7、quartz的不足
问题一:调用API的的方式操作任务,不人性化;
问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务;
问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务(其实也是乐观锁获取任务),充分发挥集群优势,负载各节点均衡。
主要还是入侵比较严重吧。而且分布式用XXLJob,更好,可以给多个分布式系统节点提供服务
