基于doc2vec的中文文本聚类及去重
- Understand doc2vec
- Data introduction
- Train a model
- Test the model
- Cluster all the lyrics
- Filter out the duplicates
1. Understand doc2vec [1]
doc2vec是基于word2vec演化而来,其本质是要学出文档的一个表示,模型由谷歌科学家Quoc Le 和 Tomas Mikolov 2014年提出,并将论文发表在International Conference on Machine Learning上。由于word2vec的训练一般有两种策略:(1) 已知上下文,推测下一个词;就是本文中的CBOW (2) 已知当前词,推测上下文,也就是常说的skip-gram。
1.1 基于CBOW的word2vec

给定一条文本包含文字:w1,w2,w3,…wT, 那么word2vec的目标函数就是最大化概率函数

目标函数很好理解,本质上是给定窗口大小的n-gram。那么用什么数据训练模型呢?模型的输入和输出其实就是一个二元组[上下文,预测词]。就是用很多这样的二元组来训练模型。例如,给定句子:秋天傍晚小街路面湿润。假定分词结果为[秋天,傍晚, 小街, 路面, 湿润],现在要预测小街,窗口大小为2, 那么用来训练模型的数据集包括[秋天,小街],[傍晚,小街], [路面,小街], [湿润,小街]。
那么预测词的取值空间其实是整个词袋,因此预测某一个词可以被视为一个多分类问题,假如词袋一共有1000个词,那么其实wordvec的训练过程就是一个1000-类 分类问题。因此一般来说,词预测,也就是在神经网络的最后一层,使用softmax。
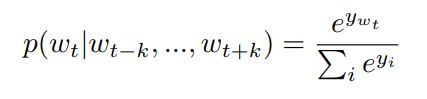

由于1000-类这样的分类问题显然直接用线性模型效率会非常低,何况一般的词袋都会有上万词,因此目前比较常用的方法是最后的输出层采用层次softmax将时间效率缩减到O(logn),其本质是一棵霍夫曼树。详细的解释以及负采样可以看一下这篇:
https://blog.csdn.net/zhangxb35/article/details/74716245。
其实word2vec要求的并不是output layer,而是为了得到hidden layer,在训练结束后,隐层的权重矩阵其实是一个NxM的矩阵,N是词的个数,M是embedding的维度,这个矩阵才是我们想要训练出来的。word2vec的训练保证了相近词义的词在向量空间中的距离更近。这也避免了词袋模型不考虑语序和语义的问题。
1.2 基于CBOW的doc2vec
为了得到文档的向量表示,科学家给原来的模型增加了一个输入向量,即文档id。其背后的思想可以解释为,预测一个词与文档本身整体的含义是分不开的,这等于是我们阅读理解以前只考虑近距离上下文,现在需要加入文章的主题来理解一个词。模型图如下

该算法包括两个步骤:
- 在已有的文档上,训练词向量W, softmax 权重 U, b 以及文档向量 D。
- 如果有新的文档加入,那么推断环节就是保持W, U, b不变,只训练D。
2. Data introduction.
本文所用数据集为歌词数据,包含约14万条中文歌词,目的是为了不同歌手间的相同歌词去重(比如翻唱改编等)。因此采用先训练doc2vec,再将文本聚类,最终在类中进行歌词比对去重的方式。
数据格式为json,其中一条数据:
{
"artist_id": 1,
"author": "李宇春",
"title": "Dance To The Music",
"song_id": 119548568,
"album_title": "1987我不知会遇见你",
"album_id": 117854447,
"language": "国语",
"versions": NaN,
"country": "内地",
"area": 0.0,
"file_duration": 215,
"publishtime": "2014-7-30",
"year": 2014.0,
"month": 7.0,
"date": 30.0,
"publish_time": "2014/7/30",
"hot": 2011,
"listen_total": 378.0,
"lyrics": {
"status": "OK",
"content": {
"[00:02.00]": "Dance To The Music",
"[00:04.00]": "作曲 张亚东",
"[00:05.00]": "作词:李宇春",
"[00:06.00]": "演唱:李宇春",
"[00:08.00]": "",
"[00:16.57]": "Dance to the music",
"[00:20.64]": "Dance to the music",
"[00:24.64]": "Dance to the music",
"[00:28.78]": "Dance to the music",
"[00:33.11]": "音乐要开最大声才够酷",
"[00:36.65]": "酷毙那些熏陶出的严肃",
"[00:41.20]": "跳级跳槽不如先跳个舞",
"[00:45.20]": "踩着节奏慢半拍也挺态度",
"[00:49.17]": "Dance to the music (Come on! Have fun!)",
"[00:53.11]": "Dance to the music (It's the right time!)",
"[00:57.19]": "Dance to the music (Now is my)",
"[01:01.21]": "Dance to the music (swing time!)",
"[01:05.31]": "想去冒险就烧掉地图",
"[01:09.07]": "通往罗马又不是只有一条路",
"[01:13.30]": "玩法自定分什么胜负",
"[01:17.31]": "开心唱歌才不一定非要照着谱",
"[01:25.14]": "",
"[01:38.16]": "偶尔弄丢了惊喜的生活",
"[01:42.19]": "有没有劲爆的八卦听说",
"[01:46.37]": "曲奇和巧克力打了个啵",
"[01:50.38]": "别太当真我们只要趣多多",
"[01:54.17]": "Dance to the music (Come on! Have fun!)",
"[01:58.11]": "Dance to the music (It's the right time!)",
"[02:02.26]": "Dance to the music (Now is my)",
"[02:06.29]": "Dance to the music (swing time!)",
"[02:10.40]": "想去冒险就烧掉地图",
"[02:14.22]": "通往罗马又不是只有一条路",
"[02:18.46]": "玩法自定分什么胜负",
"[02:22.39]": "开心唱歌才不一定非要照着谱",
"[02:25.96]": "Rap:",
"[02:26.64]": "Talking all day is not cool",
"[02:28.42]": "Noisy like a goose",
"[02:30.51]": "Why don't you find something to do",
"[02:32.51]": "Jump into the groove",
"[02:34.65]": "This time I don't want to",
"[02:36.66]": "want to be good",
"[02:38.70]": "Please don't give me that look",
"[02:40.72]": "I'm not in the mood",
"[02:43.42]": "Dance to the music",
"[02:47.05]": "Dance to the music",
"[02:50.99]": "Dance to the music",
"[02:54.84]": "Dance to the music",
"[02:59.29]": "Dance to the music (Come on! Have fun!)",
"[03:03.41]": "Dance to the music (It's the right time!)",
"[03:07.34]": "Dance to the music (Now is my)",
"[03:11.51]": "Dance to the music (swing time!)",
"[03:22.88]": ""
},
"hash": 2625080655648660063
}
}
3. Train a model.
训练doc2vec需要首先进行分词,本文采用结巴分词器。
def loadLyrics(self, filepath):
dict_stat = {'ReadError': 0}
lines = []
with codecs.open(filepath, 'r', encoding='utf-8') as f:
for line in f:
#try:
obj = json.loads(line)
lyrics = obj["lyrics"]["content"].values()
lyrics_str = ""
for lv in lyrics:
lyrics_str += lv
#print(lyrics_str)
lyrics_str = re.sub("[a-zA-Z0-9\!\%\[\]\,\。\:\:\-\"\“\”\(\)(){}\'']", "", lyrics_str)
lyrics_str = lyrics_str.replace(" ","")
words= list(jieba.cut(str(lyrics_str)))
word_list = []
for w in words:
word_list.append(w)
#filter those with less words in the lyrics
if len(word_list) > 20:
obj["lyrics"]["seg"] = word_list
lines.append(obj)
然后使用gensim中的doc2vec算法训练模型,设置窗口大小为3,文档向量长度为100,训练后保存模型。
# -*- coding: utf-8 -*-
import sys
import gensim
import sklearn
import numpy as np
import jieba
from gensim.models.doc2vec import Doc2Vec, LabeledSentence
from datamanager import DataManager
TaggededDocument = gensim.models.doc2vec.TaggedDocument
def get_datasest():
dm = DataManager()
list_lyrics = dm.loadLyrics('lyrics1.json')
x_train = []
#y = np.concatenate(np.ones(len(docs)))
for i, lyric in enumerate(list_lyrics):
try:
document = TaggededDocument(lyric["lyrics"]["seg"], tags=[i])
x_train.append(document)
except:
print(i)
print(type(words))
#print(x_train)
return x_train
def getVecs(model, corpus, size):
vecs = [np.array(model.docvecs[z.tags[0]].reshape(1, size)) for z in corpus]
return np.concatenate(vecs)
def train(x_train, size=100, epoch_num=1):
model_dm = Doc2Vec(x_train,min_count=1, window = 3, size = size, sample=1e-3, negative=5, workers=4)
model_dm.train(x_train, total_examples=model_dm.corpus_count, epochs=70)
model_dm.save('model_dm_lyrics.vec')
model_dm.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)
return model_dm
4. Test a model.
给顶一个分词结果,通过相似度结果来测试模型的有效性。
def test():
model_dm = Doc2Vec.load("model_dm_lyrics.vec")
x = get_datasest()
test_text = 《曹操》歌词的分词结果,该输入是一个数组
#test_text = "作词:林秋离作曲:林俊杰不是英雄不读三国若是英雄怎么能不懂寂寞独自走下长坂坡月光太温柔曹操不啰唆一心要拿荆州用阴谋阳谋明说暗夺淡泊东汉末年分三国烽火连天不休儿女情长被乱世左右谁来煮酒尔虞我诈是三国说不清对与错纷纷扰扰千百年以后一切又从头不是英雄不读三国若是英雄怎么能不懂寂寞独自走下长坂坡月光太温柔曹操不啰唆一心要拿荆州用阴谋阳谋明说暗夺淡泊东汉末年分三国烽火连天不休儿女情长被乱世左右谁来煮酒尔虞我诈是三国说不清对与错纷纷扰扰千百年以后一切又从头"
#text_cut = jieba.cut(test_text)
#text_raw = []
#for i in list(text_cut):
# text_raw.append(i)
inferred_vector_dm = model_dm.infer_vector(test_text)
print (inferred_vector_dm)
sims = model_dm.docvecs.most_similar([inferred_vector_dm], topn=10)
return sims
结果如下:
5. Cluster all the lyrics。
根据预训练的doc2vec,本文使用k-means对文档进行聚类,但是面临一个问题:多少各类合适?通过取值不同的聚类个数,计算SSE并对结果绘图寻找臂拐点作为合适的聚类个数。
5.1 选择聚类个数
from gensim.models.doc2vec import Doc2Vec, LabeledSentence
from sklearn.cluster import KMeans
from datamanager import DataManager
from tqdm import tqdm
import pandas as pd
import numpy as np
import json
import codecs
from sklearn.cluster import AgglomerativeClustering
def get_vectors():
list_lyrics = get_dataset()
infered_vectors_list = []
print("load doc2vec model...")
model_dm = Doc2Vec.load("model_dm_lyrics.vec")
print("load train vectors...")
i = 0
for lyric in list_lyrics:
vector = model_dm.infer_vector(lyric["lyrics"]["seg"])
infered_vectors_list.append(vector)
i += 1
vector_df = pd.DataFrame(np.matrix(infered_vectors_list))
vector_df.to_csv("doc_vecs.csv",index=None,header=None)
def cluster(K):
df = pd.read_csv("doc_vecs.csv",header=None)
infered_vectors_list = df.as_matrix()
print ("train kmean model...")
kmean_model = AgglomerativeClustering(n_clusters=K)
kmean_model.fit(infered_vectors_list)
labels= kmean_model.predict(infered_vectors_list)
#cluster_centers = kmean_model.cluster_centers_
#print(cluster_centers)
#sse = kmean_model.inertia_
list_lyrics = get_dataset()
lines = []
for i, lyric in enumerate(list_lyrics):
line = lyric
line["cluster_id"] = str(labels[i])
lines.append(line)
list_lyrics = []
for inst in tqdm(lines):
list_lyrics.append(inst)
with codecs.open('lyrics_with_cluster.json', 'w', encoding='utf-8') as f:
f.write('\n'.join([json.dumps(tmp, ensure_ascii=False) for tmp in list_lyrics]))
#return cluster_centers
if __name__ == '__main__':
#get_vectors()
sse_arr = []
k_arr = []
for k in tqdm(np.arange(10,1000,10)):
cluster(k)
5.2 实验结果

可见,在200到300处,该曲线有拐点,最终选择300为合适聚类个数。
6. Filter out the duplicates.
对于每一类的歌词中的每一首歌,计算其simhash值,然后设计聚类算法类内删除重复歌词。
[1] Distributed Representations of Sentences and Documents Quoc Le [email protected] Mikolov [email protected]