STM32CubeMx wiht AI 初体验
- File: 初使用STM32CubeMX 烧录AI极简model
- Tips: 没有图片的文章都是耍流氓,本文填充了大量的截图
- Github: project1
- 微信公众号链接: RTThread物联网操作系统
- Author1: [email protected]
- Author2: [email protected]
- Date: 2020/07/02
文章目录
- 0x00 嵌入式关联AI
- 将 AI 模型移植到 RT-Thread 上(1)
- 0x01 准备工作
- 1.1 安装开发环境
- 1.2 在 PC 端搭建极简神经网络
- 0x02 使用CubeMx AI 生成工程
- 2.1 打开CubeMx
- 2.2 导入软件包
- 2.3 导入PC端训练好的模型
- 2.4生成项目工程
- 0x03 代码调试
- 3.1 导入工程
- 3.2 生成`.bin` 文件
- 3.3 烧录`bin` 文件
- 3.4 other
- 0x04 显示神经网络的输入和输出
- 0x05 参考文章
0x00 嵌入式关联AI
将 AI 模型移植到 RT-Thread 上(1)
AI落地一直是一个很红火的前景和朝阳行业。我的好奇心也比较旺盛,所以关于任何嵌入式和 AI 相关的都是想尝一尝。本系列文章将带你一步一步把 AI 模型部署在嵌入式平台,移植到 RT-Thread 操作系统上,实现你从菜鸟到起飞的第一步甚至第 n 步!
开发环境:
后续开发过程将基于 STM32H743ZI-Nucleo 开发板,并且使用 STM32CubeMX.AI 工具。它可以基于训练好的 AI Model (仅限 Keras/TF-Lite),自动生成嵌入式项目工程(包括但是不局限于 MDK、STM32CubeIDE 等)。该工具易于上手,适合嵌入式 AI 入门开发。
STM32CubeMX是ST公司推出的一种自动创建单片机工程及初始化代码的工具,适用于旗下所有STM32系列产品。
0x01 准备工作
1.1 安装开发环境
我是用的操作系统是 Ubuntu 18.04。本次实验要用到如下开发工具,软件的安装过程很简单,网上都有很成熟的教程,在此不再赘述。该篇教程同样适用于 Windows 环境,实验步骤完全相同。
-
STM32CubeMx
-
STM32CubeIDE
-
STM32CubeProgrammer
STM32CubeProgrammer 在 ubuntu 环境下使用可能会出现如下错误:
安装好之后,在终端执行安装包路径下的
bin文件夹下的执行文件,会报错误:找不到或无法加载主类 “com.st.app.Main”,这时候只要将 Ubuntu 默认的 Open-JDK 换成 Oracle JDK 就好了,下面是切换成 Oracle JDK 成功的截图:# Oracle 官网中下载JavaSE JDK 压缩包 $ sudo tar zxvf jdk-8u172-linux-x64.tar.gz -C /usr/lib/jvm # 将下载的JDK注册到系统中 $ sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_172/bin/java 300 # 切换JDK $ sudo update-alternatives --config java # 查看JDK 版本 $ java -version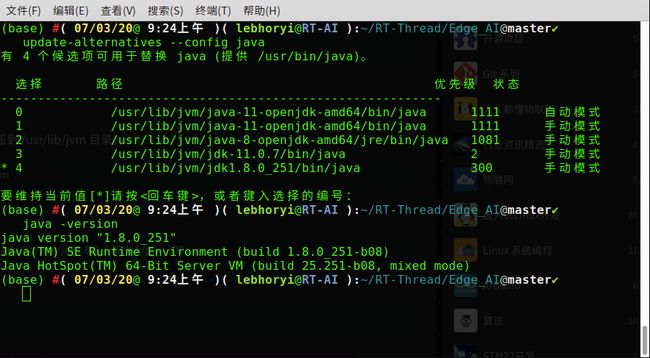
1.2 在 PC 端搭建极简神经网络
首先将如下开源仓库克隆到本地:
- Github: https://github.com/Lebhoryi/Edge_AI/tree/master/Project1

在本次实验中我选择了最简单的一个线性回归( Linear Regression) Tensor Flow2 Demo 作为示例,模型相关源文件说明如下:
tf2_linear_regression.ipynb内含三种不同方式搭建网络结构tf2_线性回归_扩展.ipynb内含不同方式训练模型
其中,在模型搭建的时候,重新温习了一下,有三种方式(各个方式的优缺点已经放在参考文章当中,感兴趣的同学自行查阅):
- Sequence
- 函数式 API
- 子类
后面将 AI 模型导入到 CubeMx 的过程中,如果使用后两种方式生成的网络模型,将会遇到如下报错:
INVALID MODEL: Couldn't load Keras model /home/lebhoryi/RT-Thread/Edge_AI/Project1/keras_model.h5,
error: Unknown layer: Functional
暂时的解决方式是采用Sequence 方式搭建神经网络,训练好的 AI Model 会被保存为 Keras 格式,后缀为 .h5,例如 keras_model.h5。
示例模型我已经保存好了,大家可以直接下载该模型进行实验,下载地址如下:
https://github.com/Lebhoryi/Edge_AI/tree/master/Project1/model
本次示例所训练的神经网络模型结构如下:
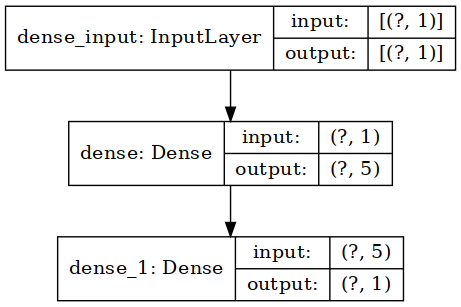
0x02 使用CubeMx AI 生成工程
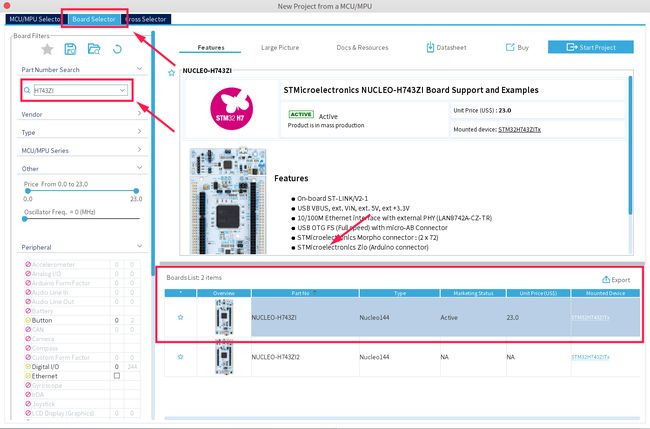
在 CubeMX 中选择 STM32H743ZI Nucleo 开发板,这里其实不限制开发板型号,常见的 Nucleo 和 Discovery 开发版都可以用于本次实验
2.1 打开CubeMx

2.2 导入软件包
打开菜单栏中的 Help,选择 Embedded Software Packages Manager,然后在 STMicroelectronics 一栏中选择 X-CUBE-AI 插件的最新版本,安装好之后点击右下角的 Close。

在工程中导入 X-CUBE-AI 插件:
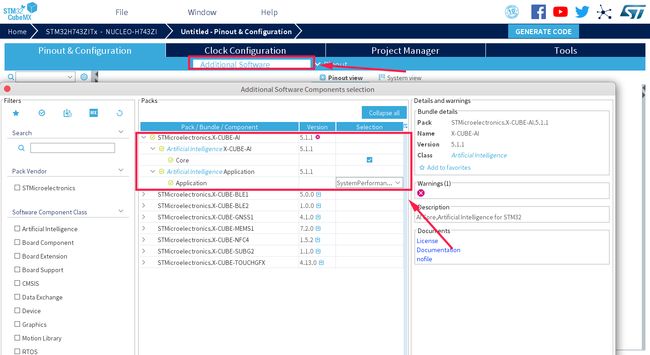
会出现如下界面:

接下来选择用于通信的串口,这里选择串口 3,因为该串口被用于 STlink 的虚拟串口。

2.3 导入PC端训练好的模型
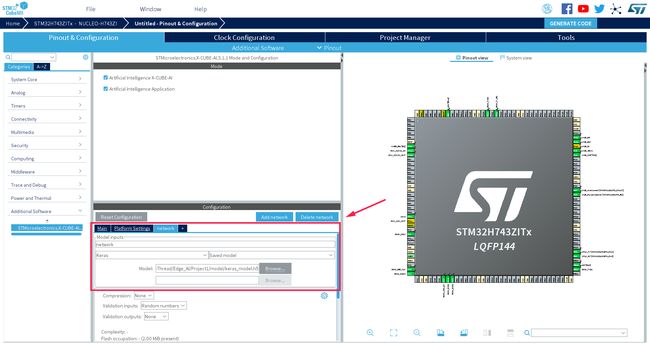
将 AI 模型烧录到开发板前,需要先分析 Model,检查其是否可以被正常转换为嵌入式工程,本次实验使用的模型比较简单,分析起来也也比较快,结果如下所示:
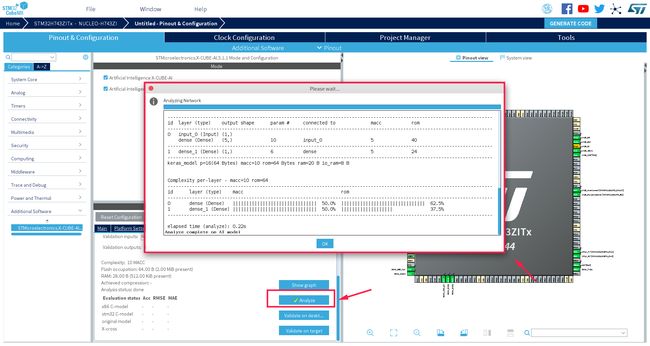
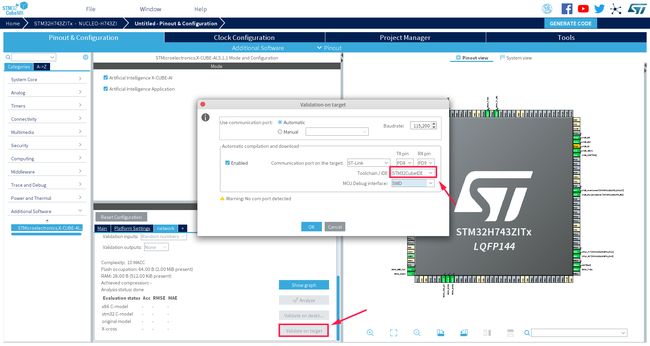
接下来我们要在开发板上验证转换后的嵌入式工程,在这个过程中 CubeMX AI 工具会根据你导入的 AI 模型,自动生成嵌入式工程,并且将编译后的可执行文件烧录到开发板中,并通过 STlink 的虚拟串口验证运行的结果。我的系统是 Ubuntu,不支持 MDK,所以在这里选择自动生成 STM32CubeIDE 工程。
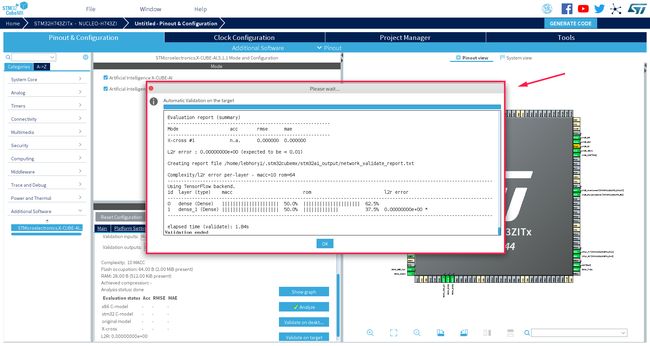
验证成功界面如下所示:
2.4生成项目工程
上一步我们只是进行了项目结果的验证,但是并没有生成项目源代码,接下来我们将生成项目工程,如下图所示:
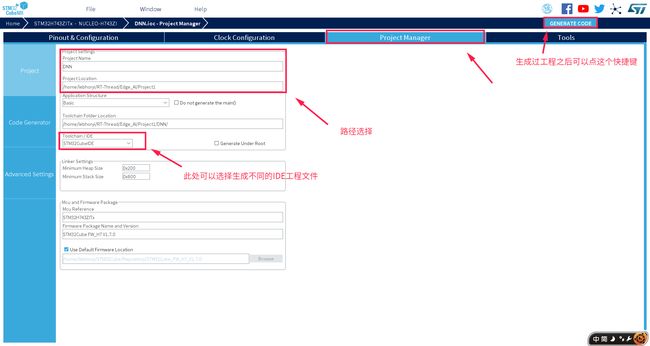
生成后的 Project 文件夹树如下所示:
(base) #( 07/03/20@10:51上午 )( lebhoryi@RT-AI ):~/RT-Thread/Edge_AI@master✗✗✗
tree -L 2 ./Project1
./Project1
├── DNN # CubeMX 生成工程路径
│ ├── DNN.ioc # CubeMX 类型文件
│ ├── Drivers
│ ├── Inc
│ ├── Middlewares
│ ├── network_generate_report.txt
│ ├── Src
│ ├── Startup
│ ├── STM32CubeIDE
│ ├── STM32H743ZITX_FLASH.ld
│ └── STM32H743ZITX_RAM.ld
├── image # 相关图片保存文件夹
│ ├── mymodel1.png # model
│ └── STM32H743.jpg # H743
├── model # model 保存路径
│ └── keras_model.h5
├── Readme.md
├── tf2_linear_regression.ipynb
└── tf2_线性回归_扩展.ipynb
至此,神功练成了一大半,剩下的就是代码调试的工作了。
0x03 代码调试
关于STM32CubeIDE 的初步认识:基础说明与开发流程
3.1 导入工程
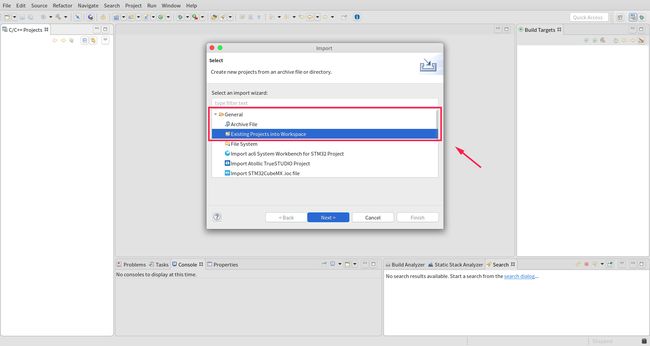
选择 File 选项 --> import:
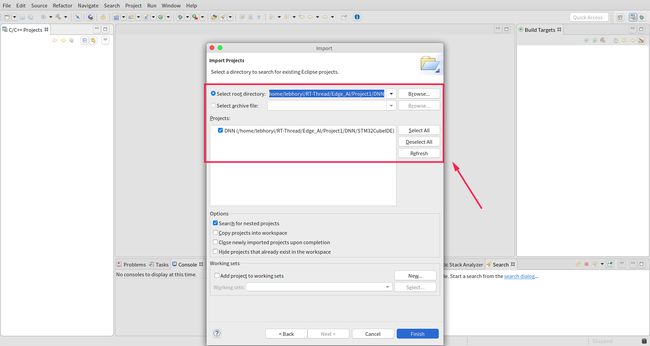
选择先前导出工程的路径:
导入成功的界面如下所示:
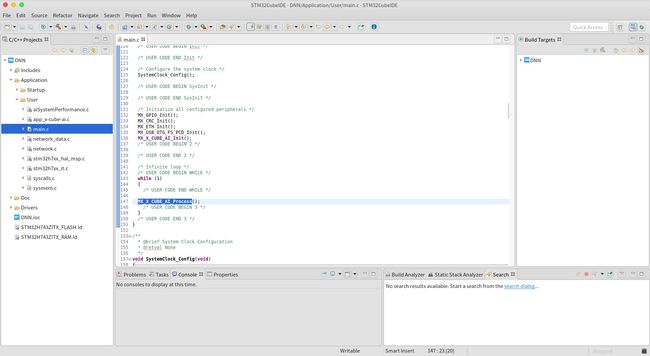
接下来就可以使用 STM32Cube IDE 来调试生成的工程了。
3.2 生成.bin 文件
在编译的过程中还会自动生成相应的 bin 文件,后续可以通过 stm32cubeProgramer 工具将 bin 文件烧录到开发板中。
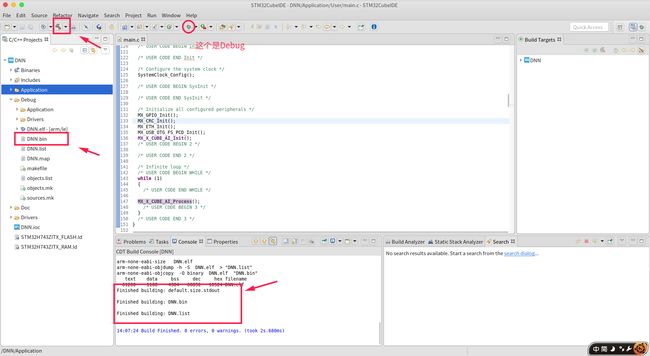
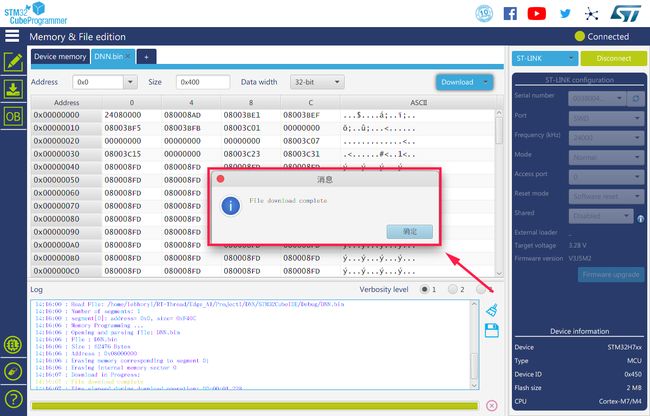
3.3 烧录bin 文件
打开STM32CubeProgramming,点击右上角connect,然后选择Open file,选择要打开的.bin 文件。

烧录成功的界面:
3.4 other
在 Ubuntu 系统中我们可以使用串口工具cutecom来查看最终程序的运行结果,程序运行结果如下:
在使用 cutecom 连接串口前,记得断开 STM32Programer 和开发板的连接,否则会出现串口打开错误的情况。
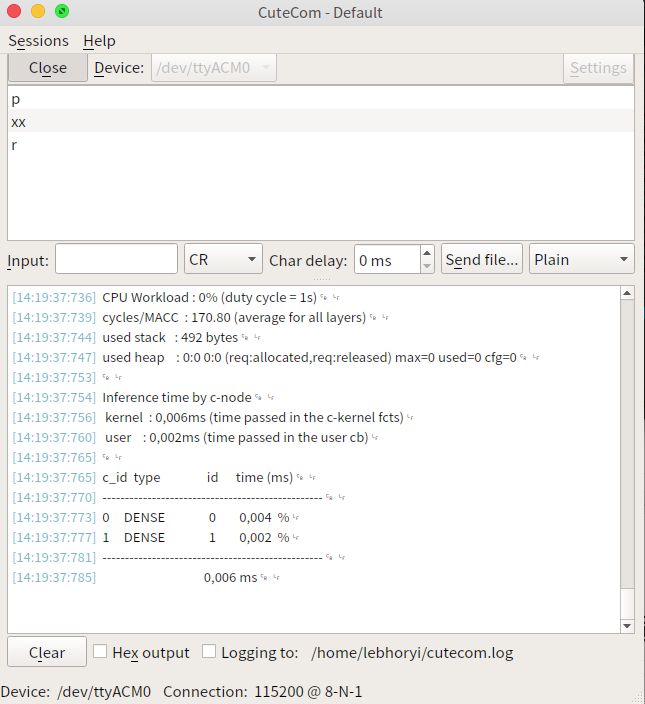
可以看到我们的 AI 模型已经在开发板上欢快地跑了起来 !!!
0x04 显示神经网络的输入和输出
在main.c 函数中找到下面这一行:
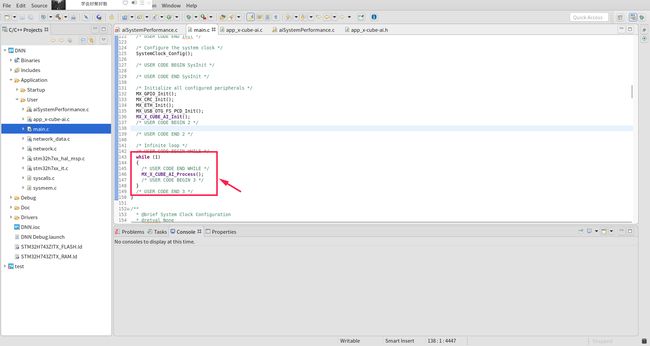
函数内部跳转, 跳转到定义 MX_X_CUBE_AI_Process(void) 的地方
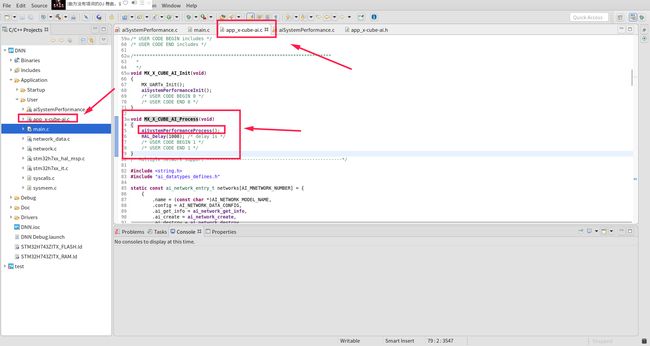
继续跳转,找到这个函数aiSystemPerformanceProcess()
下面是做了更改之后的代码, 其他部分没有做任何更改:
int aiSystemPerformanceProcess(void)
{
int idx = 0;
int batch = 0;
int y_pred;
ai_buffer ai_input[AI_MNETWORK_IN_NUM];
ai_buffer ai_output[AI_MNETWORK_OUT_NUM];
ai_float input[1] = {0}; // initial
ai_float output[1] = {0};
if (net_exec_ctx[idx].handle == AI_HANDLE_NULL)
{
printf("E: network handle is NULL\r\n");
return -1;
}
ai_input[0] = net_exec_ctx[idx].report.inputs[0];
ai_output[0] = net_exec_ctx[idx].report.outputs[0];
// ai_float test_data[] = {0, 1, 2, 3, 4, 5, 6, 7};
for (int i=0; i < 999; i++)
{
input[0] = rand()%20 - 15; // 随机生成[-10, 10] 的值
output[0] = 0;
ai_input[0].data = AI_HANDLE_PTR(input);
ai_output[0].data = AI_HANDLE_PTR(output);
batch = ai_mnetwork_run(net_exec_ctx[idx].handle, &ai_input[0], &ai_output[0]);
if (batch != 1)
{
aiLogErr(ai_mnetwork_get_error(net_exec_ctx[idx].handle),
"ai_mnetwork_run");
break;
}
y_pred = 6 * input[0] + 10;
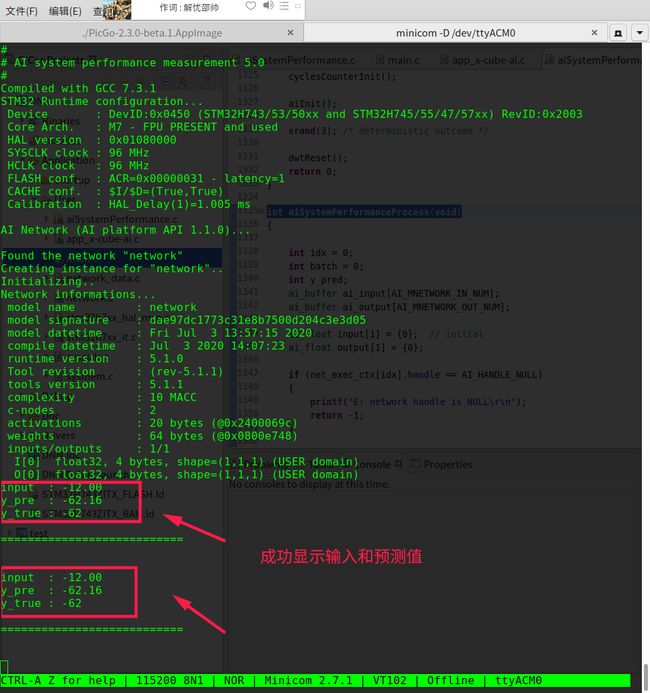
printf("input : %.2f \r\n", input[0]);
printf("y_pre : %.2f \r\n", output[0]);
printf("y_true : %d \r\n", y_pred);
printf("\r\n===========================\r\n\r\n\r\n");
HAL_Delay(5000);
}
}
运行成功的截图:
0x05 参考文章
- STM32CubeMX系列教程
- Tensorflow 2.0 中模型构建的三种方式
- Ubuntu16.04 和 Ubuntu18.04 安装 STM32CubeProgrammer 遇到的坑
- 基础说明与开发流程