大数据实训01--Hadoop生态基本介绍
Hadoop官网
有一个Hadoop生态圈,都是用动物命名的
知识前提
分布式存储,分布式技术
分布式文件系统master-slave (每一台服务器为一个结点,一主多从)主从架构
master(主结点)-----保存文件系统的目录树结构(清单),监控整个集群资源使用情况
slave(从结点)-----存放真实的数据
客户端 和分布式文件系统进行通信
内部客户端(集群内部)
web客户端
先和master建立通信获取目录(数据清单)
分散在分布式系统中的数据可能属于一个文件
namespace命名空间,管理服务器集群的所有文件,有这种功能的就是主节点master
为了提高访问速度,可以将目录(master)存放在内存
很难管理大小不一样的文件-----解决:利用block块(Hadoop内部划分大小一样的块)Hadoop 1.x block 64M 2.x 128M
为数据建立副本(冗余备份)replication 副本机制 防止服务器崩溃导致数据丢失
Hadoop默认的副本有3个(可修改配置文件指定),分散在不同的机架

(图片来自实训老师)
分布式计算
100G的文件排序
传统的解决方案:
移动数据:将数据向计算移动
移动计算:将计算向数据移动,将程序移动到每个服务结点
map-reduce并行分布框架(分而治之的思想)
1.任务分解 map (map task)2.结果汇总reduce(reduce-task)
Hadoop
开源、可靠(副本机制)、可扩展(扩展结点,线性增长)分布式并行计算框架(HDFS存储 MapReduce计算)
大量数据,离线分析 Hbase 数据库(基于列shi)
体系架构

Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
(1)HDFS集群:负责海量数据的存储,集群中的角色主要 有 NameNode / DataNode/Client。
(2)YARN集群:负责海量数据运算时的资源调度,集群中的角色主 要有 ResourceManager /NodeManager
(3)MapReduce:它其实是一个应用程序开发包。
HDFS分布式文件系统
HDFS存储模式
存储模型:底层字节为单位
偏移量offset
副本数:默认是三个
架构模型
1.namenode (进程)文件系统的管家,监管这个文件系统的目录树结构,由他维护文件系统的元数据信息(文件名称、blocklocation)
2.datanode 存放真实的数据(block数据)与namenode保持心跳,提交列表
3.client客户端 与namenode 交互元数据,与datanode交互block信息
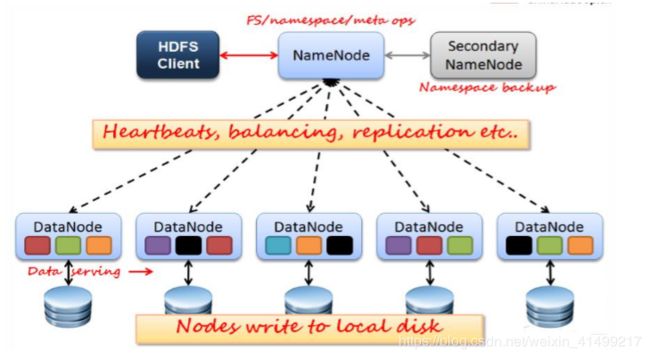
(图源:实训课件)
HDFS环境搭建相关知识
下载Hadoop
Hadoop-2.7.5 清华大学开源软件镜像
Hadoop官方文档
官方文档中有详细的介绍和安装步骤

集成好的Hadoop环境链接(centos6.5,Hadoop2.7.5,VMware12)虚拟机直接打开文档就可以用:
https://pan.baidu.com/s/1HIhy5r7CvPHLRR3ZofrzlA
提取码:0lxv
Hadoop的三种集群方式
1.单机模式 2.伪分布式模式 3.完全分布式模式
关闭防火请实现免密钥登录
在部署hadoop环境时,要关闭防火墙,如果不关闭可能会出现节点间无法通信的 情况,因为都是内网搭建的,对外还有一个服务器的,那个服务器有防火墙, 由它来访问内网集群,如果内网内开启防火墙,内网集群通讯会出现很多问题
免密钥利用sshd服务,防火墙关闭方法上一节提到过chkconfig iptables off
查看配置文件
dhfs-site.xml 配置了副本数量和slaves

core.site.xml 配置NN DN SNN

http://localhost:50070/ hadoop外部web访问接口,可视化界面
http://localhost:9000/ hadoop进程进的通信接口
从HDFS网页端查看存储的文档,可以看出文档被分成了block来存储

yarn资源管理框架 管理MapReduce
rm(resourceManager)执行作业
nm(nodeManager)资源调度

图中显示了Hadoop下的bin和sbin:bin下的是Hadoop的一些模块功能包括HDFS,MapReduce,yarn等,sbin是应用功能,如Hadoop守候进程,启动停止集群,yarn管理MapReduce
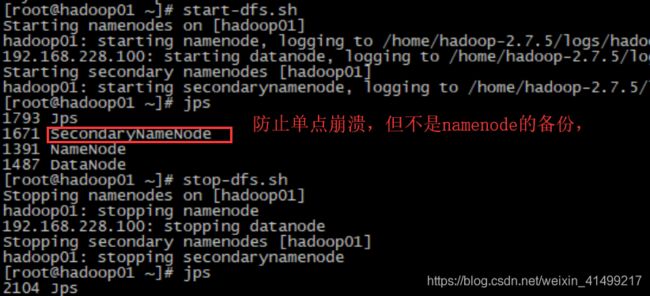
jps (Java的一个可执行程序)监管Hadoop产生的进程
start-dfs.sh启动集群(所有相关进程)
stop-dfs.sh关闭集群
#20200618
java的序列化和反序列化:序列化--内存中的对象序列成字节数组,反序列化:将磁盘中的数据读回到内存(方便更好的类比SecondaryNameNode的功能)
HDFS面临的问题
1 单节点故障
解决:主备切换(HA,active-standby,保持同步)
namenode:fsimage(快照),持久化,editlog(记录运行记录)
hdfs-namenode-format文件系统格式化------产生一个空的fsimage(相当于namenode的快照),同时开启editlog持续记录运行记录。SecondaryNameNode用于合并fsimage+editlog
SecondaryNameNode(SNN)
它的主要工作是帮助NN合并edits log,减少NN启动时间。
SNN执行合并时机
(1).根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
(2).根据配置文件设置edits log大小fs.checkpoint.size规定edits文件的最 大值默认是64MB
2 内存受限
解决:多个namenode 形成联邦机制(相互独立)
hdfs 相关命令
---查看hdfs文件

---从宿主机上传文件到虚拟机,小文件用命令rz,先yum install lrzsz -y安装,

rz命令会弹出对话框选择文件上传

大文件可以借助软件来完成,我的是 WinSCP,界面是这样的

上传到HDFS文件系统 (从Linux文件系统上传/下载 到hdfs文件系统)
hdfs dfs -put xx(待上传文件路径) /xx/xx(目的路径)
客户端指定块大小上传 参数 -D dfs.blocksize=xxx(B) 1M=1048576B
客户指定块大小,dfs执行切割,可能会把完整地字符拆分掉

下载:hdfs dfs -get /xx [hdfs文件系统中待下载文件的路径] /xx[下载到Linux文件系统的目的路径]
真实的块数据存储路径


单独启动/关闭某个进程 hadoop-daemon.sh start/stop xxx(进程名)

查看日志文件

持续更新补充......