import matplotlib.pyplot as plt
import numpy as np
import random
"""
Desc:
读取数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
"""
Desc:
随机选择alpha_j
Parameters:
i - alpha
m - alpha参数个数
Returns:
j - 返回选定的数字
"""
def selectJrand(i, m):
j = i
while(j == i):
j = int(random.uniform(0, m))
return j
"""
Desc:
修剪alpha
Parameters:
aj - alpha值
H - alpha上限
L - alpha下限
Returns:
aj - alpha值
"""
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
"""
Desc:
简化版SMO算法
Parameters:
dataMatIn - 数据矩阵
classLabels - 数据标签
C - 松弛变量
toler - 容错率
maxIter - 最大迭代次数
Returns:
None
"""
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
b = 0
m, n = np.shape(dataMatrix)
alphas = np.mat(np.zeros((m, 1)))
iter_num = 0
while(iter_num < maxIter):
alphaPairsChanged = 0
for i in range(m):
fxi = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
Ei = fxi - float(labelMat[i])
if((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i, m)
fxj = float(np.multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fxj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
if(labelMat[i] != labelMat[j]):
L = max(0, alphas[j] -alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if(L == H):
print("L == H")
continue
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - dataMatrix[j, :] * dataMatrix[j, :].T
if eta >= 0:
print("eta>=0")
continue
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
alphas[j] = clipAlpha(alphas[j], H, L)
if(abs(alphas[j] - alphaJold) < 0.00001):
print("alpha_j变化太小")
continue
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[i, :].T
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[j, :].T - labelMat[j] * (alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
if(0 < alphas[i] < C):
b = b1
elif(0 < alphas[j] < C):
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1
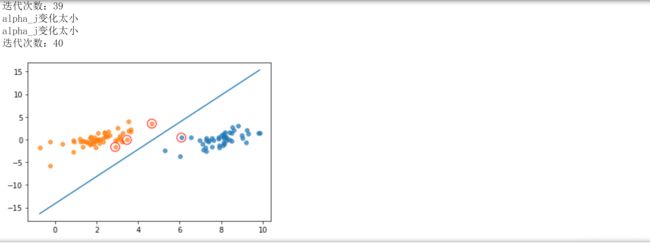
print("第%d次迭代 样本:%d, alpha优化次数:%d" % (iter_num, i, alphaPairsChanged))
if(alphaPairsChanged == 0):
iter_num += 1
else:
iter_num = 0
print("迭代次数:%d" % iter_num)
return b, alphas
"""
Desc:
计算w
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
alphas - alphas值
Returns:
w - 直线法向量
"""
def get_w(dataMat, labelMat, alphas):
alphas, dataMat, labelMat = np.array(alphas), np.array(dataMat), np.array(labelMat)
w = np.dot((np.tile(labelMat.reshape(1, -1).T, (1, 2)) * dataMat).T, alphas)
return w.tolist()
"""
Desc:
分类结果可视化
Returns:
dataMat - 数据矩阵
w - 直线法向量
b - 直线截距
Returns:
None
"""
def showClassifer(dataMat, w, b):
data_plus = []
data_minus = []
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus)
data_minus_np = np.array(data_minus)
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7)
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7)
x1 = max(dataMat)[0]
x2 = min(dataMat)[0]
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1, y2 = (-b - a1 * x1) / a2, (-b - a1 * x2) / a2
plt.plot([x1, x2], [y1, y2])
for i, alpha in enumerate(alphas):
if(abs(alpha) > 0):
x, y = dataMat[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolors='red')
plt.show()
if __name__ == '__main__':
dataMat, labelMat = loadDataSet('testSet.txt')
b, alphas = smoSimple(dataMat, labelMat, 0.6, 0.001, 40)
w = get_w(dataMat, labelMat, alphas)
showClassifer(dataMat, w, b)
import matplotlib.pyplot as plt
import numpy as np
import random
"""
Desc:
维护所有需要操作的值
Parameters:
dataMatIn - 数据矩阵
classLabels - 数据标签
C - 松弛变量
toler - 容错率
Returns:
None
"""
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = np.shape(dataMatIn)[0]
self.alphas = np.mat(np.zeros((self.m, 1)))
self.b = 0
self.eCache = np.mat(np.zeros((self.m, 2)))
"""
Desc:
读取数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
"""
Desc:
计算误差
Parameters:
oS - 数据结构
k - 标号为k的数据
Returns:
Ek - 标号为k的数据误差
"""
def calcEk(oS, k):
fXk = float(np.multiply(oS.alphas, oS.labelMat).T * (oS.X * oS.X[k, :].T) + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
"""
Desc:
随机选择alpha_j
Parameters:
i - alpha_i的索引值
m - alpha参数个数
Returns:
j - alpha_j的索引值
"""
def selectJrand(i, m):
j = i
while(j == i):
j = int(random.uniform(0, m))
return j
"""
Desc:
内循环启发方式2
Parameters:
i - 标号为i的数据的索引值
oS - 数据结构
Ei - 标号为i的数据误差
Returns:
j - 标号为j的数据的索引值
maxK - 标号为maxK的数据的索引值
Ej - 标号为j的数据误差
"""
def selectJ(i, oS, Ei):
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1, Ei]
validEcacheList = np.nonzero(oS.eCache[:, 0].A)[0]
if(len(validEcacheList) > 1):
for k in validEcacheList:
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if(deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
"""
Desc:
计算Ek,并更新误差缓存
Parameters:
oS - 数据结构
k - 标号为k的数据的索引值
Returns:
None
"""
def updateEk(oS, k):
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
"""
Desc:
修剪alpha_j
Parameters:
aj - alpha_j值
H - alpha上限
L - alpha下限
Returns:
aj - alpha_j值
"""
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
"""
Desc:
优化的SMO算法
Parameters:
i - 标号为i的数据的索引值
oS - 数据结构
Returns:
1 - 有任意一对alpha值发生变化
0 - 没有任意一对alpha值发生变化或变化太小
"""
def innerL(i, oS):
Ei = calcEk(oS, i)
if((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if(oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L == H")
return 0
eta = 2.0 * oS.X[i, :] * oS.X[j, :].T - oS.X[i, :] * oS.X[i, :].T - oS.X[j, :] * oS.X[j, :].T
if eta >= 0:
print("eta >= 0")
return 0
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
updateEk(oS, j)
if(abs(oS.alphas[j] - alphaJold) < 0.00001):
print("alpha_j变化太小")
return 0
oS.alphas[i] += oS.labelMat[i] * oS.labelMat[j] * (alphaJold - oS.alphas[j])
updateEk(oS, i)
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[i, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[i, :].T
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.X[i, :] * oS.X[j, :].T - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.X[j, :] * oS.X[j, :].T
if(0 < oS.alphas[i] < oS.C):
oS.b = b1
elif(0 < oS.alphas[j] < oS.C):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
"""
Desc:
完整的线性SMO算法
Parameters:
dataMatIn - 数据矩阵
classLabels - 数据标签
C - 松弛变量
toler - 容错率
maxIter - 最大迭代次数
Returns:
oS.b - SMO算法计算的b
oS.alphas - SMO算法计算的alphas
"""
def smoP(dataMatIn, classLabels, C, toler, maxIter):
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler)
iter = 0
entrieSet = True
alphaPairsChanged = 0
while(iter < maxIter) and ((alphaPairsChanged > 0) or (entrieSet)):
alphaPairsChanged = 0
if entrieSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
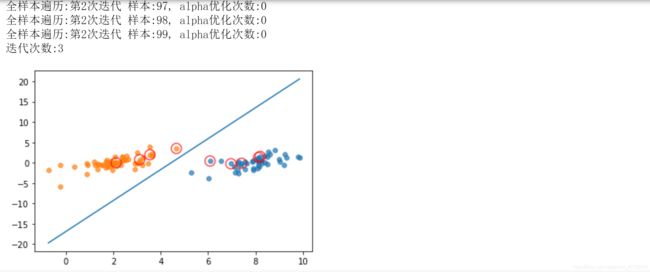
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
else:
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
if entrieSet:
entrieSet = False
elif(alphaPairsChanged == 0):
entrieSet = True
print("迭代次数:%d" % iter)
return oS.b, oS.alphas
"""
Desc:
分类结果可视化
Returns:
dataMat - 数据矩阵
classLabels - 数据标签
w - 直线法向量
b - 直线截距
Returns:
None
"""
def showClassifer(dataMat, classLabels, w, b):
data_plus = []
data_minus = []
for i in range(len(dataMat)):
if classLabels[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus)
data_minus_np = np.array(data_minus)
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1], s=30, alpha=0.7)
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1], s=30, alpha=0.7)
x1 = max(dataMat)[0]
x2 = min(dataMat)[0]
a1, a2 = w
b = float(b)
a1 = float(a1[0])
a2 = float(a2[0])
y1, y2 = (-b - a1 * x1) / a2, (-b - a1 * x2) / a2
plt.plot([x1, x2], [y1, y2])
for i, alpha in enumerate(alphas):
if(abs(alpha) > 0):
x, y = dataMat[i]
plt.scatter([x], [y], s=150, c='none', alpha=0.7, linewidth=1.5, edgecolors='red')
plt.show()
"""
Desc:
计算w
Returns:
dataArr - 数据矩阵
classLabels - 数据标签
alphas - alphas值
Returns:
w - 直线法向量
"""
def calcWs(alphas, dataArr, classLabels):
X = np.mat(dataArr)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(X)
w = np.zeros((n, 1))
for i in range(m):
w += np.multiply(alphas[i] * labelMat[i], X[i, :].T)
return w
if __name__ == '__main__':
dataArr, classLabels = loadDataSet('testSet.txt')
b, alphas = smoP(dataArr, classLabels, 0.6, 0.001, 40)
w = calcWs(alphas, dataArr, classLabels)
showClassifer(dataArr, classLabels, w, b)
import matplotlib.pyplot as plt
import numpy as np
import random
"""
类说明:维护所有需要操作的值
Parameters:
dataMatIn - 数据矩阵
classLabels - 数据标签
C - 松弛变量
toler - 容错率
kTup - 包含核函数信息的元组,第一个参数存放该核函数类别,第二个参数存放必要的核函数需要用到的参数
Returns:
None
"""
class optStruct:
def __init__(self, dataMatIn, classLabels, C, toler, kTup):
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = np.shape(dataMatIn)[0]
self.alphas = np.mat(np.zeros((self.m, 1)))
self.b = 0
self.eCache = np.mat(np.zeros((self.m, 2)))
self.K = np.mat(np.zeros((self.m, self.m)))
for i in range(self.m):
self.K[:, i] = kernelTrans(self.X, self.X[i, :], kTup)
"""
Desc:
通过核函数将数据转换更高维空间
Parameters:
X - 数据矩阵
A - 单个数据的向量
kTup - 包含核函数信息的元组
Returns:
K - 计算的核K
"""
def kernelTrans(X, A, kTup):
m, n = np.shape(X)
K = np.mat(np.zeros((m, 1)))
if kTup[0] == 'lin':
K = X * A.T
elif kTup[0] == 'rbf':
for j in range(m):
deltaRow = X[j, :] - A
K[j] = deltaRow * deltaRow.T
K = np.exp(K / (-1 * kTup[1] ** 2))
else:
raise NameError('核函数无法识别')
return K
"""
Desc:
读取数据
Parameters:
fileName - 文件名
Returns:
dataMat - 数据矩阵
labelMat - 数据标签
"""
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
"""
Desc:
计算误差
Parameters:
oS - 数据结构
k - 标号为k的数据
Returns:
Ek - 标号为k的数据误差
"""
def calcEk(oS, k):
fXk = float(np.multiply(oS.alphas, oS.labelMat).T * oS.K[:, k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
"""
Desc:
随机选择alpha_j
Parameters:
i - alpha_i的索引值
m - alpha参数个数
Returns:
j - alpha_j的索引值
"""
def selectJrand(i, m):
j = i
while(j == i):
j = int(random.uniform(0, m))
return j
"""
Desc:
内循环启发方式2
Parameters:
i - 标号为i的数据的索引值
oS - 数据结构
Ei - 标号为i的数据误差
Returns:
j - 标号为j的数据的索引值
maxK - 标号为maxK的数据的索引值
Ej - 标号为j的数据误差
"""
def selectJ(i, oS, Ei):
maxK = -1
maxDeltaE = 0
Ej = 0
oS.eCache[i] = [1, Ei]
validEcacheList = np.nonzero(oS.eCache[:, 0].A)[0]
if(len(validEcacheList) > 1):
for k in validEcacheList:
if k == i:
continue
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if(deltaE > maxDeltaE):
maxK = k
maxDeltaE = deltaE
Ej = Ek
return maxK, Ej
else:
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
"""
Desc:
计算Ek,并更新误差缓存
Parameters:
oS - 数据结构
k - 标号为k的数据的索引值
Returns:
None
"""
def updateEk(oS, k):
Ek = calcEk(oS, k)
oS.eCache[k] = [1, Ek]
"""
Desc:
修剪alpha_j
Parameters:
aj - alpha_j值
H - alpha上限
L - alpha下限
Returns:
aj - alpha_j值
"""
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
"""
Desc:
优化的SMO算法
Parameters:
i - 标号为i的数据的索引值
oS - 数据结构
Returns:
1 - 有任意一对alpha值发生变化
0 - 没有任意一对alpha值发生变化或变化太小
"""
def innerL(i, oS):
Ei = calcEk(oS, i)
if((oS.labelMat[i] * Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i] * Ei > oS.tol) and (oS.alphas[i] > 0)):
j, Ej = selectJ(i, oS, Ei)
alphaIold = oS.alphas[i].copy()
alphaJold = oS.alphas[j].copy()
if(oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L == H:
print("L == H")
return 0
eta = 2.0 * oS.K[i, j] - oS.K[i, i] - oS.K[j, j]
if eta >= 0:
print("eta >= 0")
return 0
oS.alphas[j] -= oS.labelMat[j] * (Ei - Ej) / eta
oS.alphas[j] = clipAlpha(oS.alphas[j], H, L)
updateEk(oS, j)
if(abs(oS.alphas[j] - alphaJold) < 0.00001):
print("alpha_j变化太小")
return 0
oS.alphas[i] += oS.labelMat[i] * oS.labelMat[j] * (alphaJold - oS.alphas[j])
updateEk(oS, i)
b1 = oS.b - Ei - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, i] - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.K[j, i]
b2 = oS.b - Ej - oS.labelMat[i] * (oS.alphas[i] - alphaIold) * oS.K[i, j] - oS.labelMat[j] * (oS.alphas[j] - alphaJold) * oS.K[j, j]
if(0 < oS.alphas[i] < oS.C):
oS.b = b1
elif(0 < oS.alphas[j] < oS.C):
oS.b = b2
else:
oS.b = (b1 + b2) / 2.0
return 1
else:
return 0
"""
Desc:
完整的线性SMO算法
Parameters:
dataMatIn - 数据矩阵
classLabels - 数据标签
C - 松弛变量
toler - 容错率
maxIter - 最大迭代次数
kTup - 包含核函数信息的元组
Returns:
oS.b - SMO算法计算的b
oS.alphas - SMO算法计算的alphas
"""
def smoP(dataMatIn, classLabels, C, toler, maxIter, kTup = ('lin', 0)):
oS = optStruct(np.mat(dataMatIn), np.mat(classLabels).transpose(), C, toler, kTup)
iter = 0
entrieSet = True
alphaPairsChanged = 0
while(iter < maxIter) and ((alphaPairsChanged > 0) or (entrieSet)):
alphaPairsChanged = 0
if entrieSet:
for i in range(oS.m):
alphaPairsChanged += innerL(i, oS)
print("全样本遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
else:
nonBoundIs = np.nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i, oS)
print("非边界遍历:第%d次迭代 样本:%d, alpha优化次数:%d" % (iter, i, alphaPairsChanged))
iter += 1
if entrieSet:
entrieSet = False
elif(alphaPairsChanged == 0):
entrieSet = True
print("迭代次数:%d" % iter)
return oS.b, oS.alphas
"""
Desc:
测试函数
Parameters:
k1 - 使用高斯核函数的时候表示到达率
Returns:
None
"""
def testRbf(k1 = 1.3):
dataArr, labelArr = loadDataSet('testSetRBF.txt')
b, alphas = smoP(dataArr, labelArr, 200, 0.0001, 100, ('rbf', k1))
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
svInd = np.nonzero(alphas.A > 0)[0]
sVs = datMat[svInd]
labelSV = labelMat[svInd]
print("支持向量个数:%d" % np.shape(sVs)[0])
m, n = np.shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
print('训练集错误率:%.2f%%' % ((float(errorCount) / m) * 100))
dataArr, labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat = np.mat(dataArr)
labelMat = np.mat(labelArr).transpose()
m, n = np.shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs, datMat[i, :], ('rbf', k1))
predict = kernelEval.T * np.multiply(labelSV, alphas[svInd]) + b
if np.sign(predict) != np.sign(labelArr[i]):
errorCount += 1
print('训练集错误率:%.2f%%' % ((float(errorCount) / m) * 100))
"""
Desc:
数据可视化
Parameters:
dataMat - 数据矩阵
labelMat - 数据标签
Returns:
None
"""
def showDataSet(dataMat, labelMat):
data_plus = []
data_minus = []
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus)
data_minus_np = np.array(data_minus)
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1])
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1])
plt.show()
if __name__ == '__main__':
testRbf()
