监督学习之四——支持向量机(Support Vector Machines,SVM)
文章目录
- 1 支持向量机基本概念(Support Vector Machines,SVM)
- 1.1 SVM
- 1.2 支持向量和间隔
- 1.3 SVM基本型
- 1.4 对偶问题
- 1.5 KKT条件
- 1.6 序列最小最优化(SMO)算法
- 1.7 线性不可分支持向量机与软间隔最大
- 2 SVR(Support Vector Regressor)数学原理
- 3 常用kernel函数
1 支持向量机基本概念(Support Vector Machines,SVM)
1.1 SVM
通常SVM会构造一个或一组距离数据点最大间距(margin)的超平面用于分类、回归和异常值检测,因此SVM也被称作大间距分类器。
对于多元分类,SVM采用ovo(一对一)的方法。
1.2 支持向量和间隔
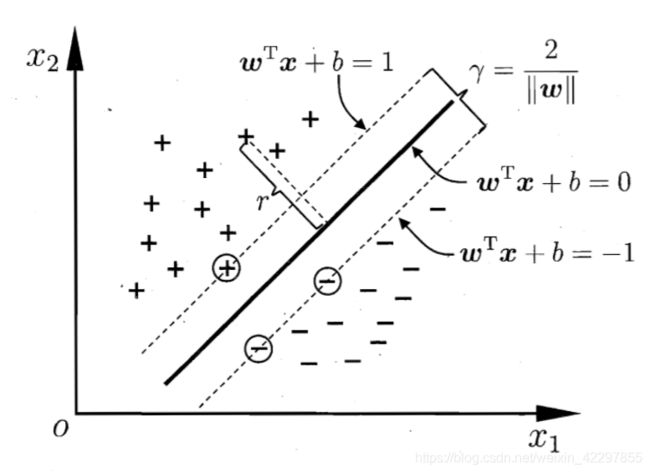
对于超平面方程 w T x + b = 0 {\bf w^Tx}+b=0 wTx+b=0,样本空间里任意点 x \bf x x到该超平面的距离为 r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ r=\frac{|{\bf w^Tx}+b|}{||\bf w||} r=∣∣w∣∣∣wTx+b∣,若该超平面能将所有样本都正确分类,则总存在一个平面(缩放变换)使得:
w T x + b ≥ 1 , y i = 1 {\bf w^Tx}+b\ge1,y_i=1 wTx+b≥1,yi=1
w T x + b ≤ − 1 , y i = − 1 {\bf w^Tx}+b\le-1,y_i=-1 wTx+b≤−1,yi=−1
则距离超平面最近的使得上式等号成立的几个训练样本就是支持向量。间隔就是两个异类支持向量到超平面的距离和为 γ = 2 ∣ ∣ w ∣ ∣ \gamma=\frac{2}{||\bf w||} γ=∣∣w∣∣2。如下图所示(图片来源《机器学习》周志华)。
1.3 SVM基本型
根据间隔和支持向量的概念得到基本型(凸二次优化问题)
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 \min_{w,b}\frac{1}{2}||w||^2 w,bmin21∣∣w∣∣2
s . t . y i ( w T x + b ) ≥ 1 s.t.\quad y_i({\bf w^Tx}+b)\ge1 s.t.yi(wTx+b)≥1
1.4 对偶问题
利用拉格朗日乘子法得到其对偶问题。


1.5 KKT条件

模型只需记录不为0的 α i \alpha_i αi,故该式说明最终模型仅跟支持向量有关。
1.6 序列最小最优化(SMO)算法
对于1.4中的对偶问题,这是一个二次规划问题,我们可以利用SMO算法高效算出。

1.7 线性不可分支持向量机与软间隔最大
当样本线性不可分时,我们可以采用核函数用超平面将样本分开,但可能导致过拟合,缓解该问题的方法就是软间隔。具体来说,前面介绍的支持向量机形式是要求所有样本均满足约束 y i ( w T x + b ) ≥ 1 , y_i({\bf w^Tx}+b)\ge1, yi(wTx+b)≥1,
即所有样本都必须划分正确,这称为“硬间隔”(hardmargin),而软间隔则是允许某些样本不满足该约束。
修改目标函数为
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 m max ( 0 , 1 − y i ( w T x i + b ) ) , \displaystyle \min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{i=1}^{m} \max(0,1-y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)), w,bmin21∥w∥2+Ci=1∑mmax(0,1−yi(wTxi+b)),
在使得间隔最大的同时,还要满足不符合约束的样本尽可能少,其中C>0,这里采用的是“hinge损失函数”
ℓ hinge ( z ) = max ( 0 , 1 − z ) \ell_{\text {hinge}}(z)=\max (0,1-z) ℓhinge(z)=max(0,1−z)
引入松弛变量则得到软间隔支持向量机
min w , b , ξ i 1 2 ∥ w ∥ 2 + C ∑ i = 1 m ξ i \min _{\boldsymbol{w}, b, \xi_{i}} \frac{1}{2}\|\boldsymbol{w}\|^{2}+C \sum_{i=1}^{m} \xi_{i} w,b,ξimin21∥w∥2+Ci=1∑mξi
s . t . y i ( w T x i + b ) ⩾ 1 − ξ i s.t. \quad y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1-\xi_{i} s.t.yi(wTxi+b)⩾1−ξi
ξ i ⩾ 0 , i = 1 , 2 , … , m \xi_{i} \geqslant 0, i=1,2, \dots, m ξi⩾0,i=1,2,…,m
依然使用拉格朗日乘子法得到其对偶问题
max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s.t. ∑ i = 1 m α i y i = 0 0 ⩽ α i ⩽ C , i = 1 , 2 , … , m \begin{aligned} \max _{\boldsymbol{\alpha}} & \sum_{i=1}^{m} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{m} \sum_{j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j} \\ \text { s.t. } & \sum_{i=1}^{m} \alpha_{i} y_{i}=0 \\ & 0 \leqslant \alpha_{i} \leqslant C, \quad i=1,2, \ldots, m \end{aligned} αmax s.t. i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxji=1∑mαiyi=00⩽αi⩽C,i=1,2,…,m
可以看出区别就在第二条约束上,同样可以利用SMO算法求解。
2 SVR(Support Vector Regressor)数学原理

数学模型:
min w , b , ζ , ζ ∗ 1 2 w T w + C ∑ i = 1 n ( ζ i + ζ i ∗ ) \displaystyle \min_ {w, b, \zeta, \zeta^*} \frac{1}{2} w^T w + C \sum_{i=1}^{n} (\zeta_i + \zeta_i^*) w,b,ζ,ζ∗min21wTw+Ci=1∑n(ζi+ζi∗)
s.t. y i − w T ϕ ( x i ) − b ≤ ε + ζ i , \textrm{s.t. } \quad y_i - w^T \phi (x_i) - b \leq \varepsilon + \zeta_i, s.t. yi−wTϕ(xi)−b≤ε+ζi,
w T ϕ ( x i ) + b − y i ≤ ε + ζ i ∗ , w^T \phi (x_i) + b - y_i \leq \varepsilon + \zeta_i^*, wTϕ(xi)+b−yi≤ε+ζi∗,
ζ i , ζ i ∗ ≥ 0 , i = 1 , . . . , n \zeta_i, \zeta_i^* \geq 0, i=1, ..., n ζi,ζi∗≥0,i=1,...,n
对偶问题:
min α , α ∗ 1 2 ( α − α ∗ ) T X T X ( α − α ∗ ) + ε e T ( α + α ∗ ) − y T ( α − α ∗ ) \displaystyle \min_{\alpha, \alpha^*} \frac{1}{2} (\alpha - \alpha^*)^T X^TX (\alpha - \alpha^*) + \varepsilon e^T (\alpha + \alpha^*) - y^T (\alpha - \alpha^*) α,α∗min21(α−α∗)TXTX(α−α∗)+εeT(α+α∗)−yT(α−α∗)
s.t. e T ( α − α ∗ ) = 0 , \textrm {s.t. } \quad e^T (\alpha - \alpha^*) = 0, s.t. eT(α−α∗)=0,
0 ≤ α i , α i ∗ ≤ C , i = 1 , . . . , n 0 \leq \alpha_i, \alpha_i^* \leq C, i=1, ..., n 0≤αi,αi∗≤C,i=1,...,n
决策函数:
∑ i = 1 n ( α i − α i ∗ ) K ( x i , x ) + b \sum_{i=1}^n (\alpha_i - \alpha_i^*) K(x_i, x) + b i=1∑n(αi−αi∗)K(xi,x)+b
3 常用kernel函数
线性核函数
⟨ x , x ′ ⟩ \langle x, x'\rangle ⟨x,x′⟩
多项式核函数
( γ ⟨ x , x ′ ⟩ + r ) d (\gamma \langle x, x'\rangle + r)^d (γ⟨x,x′⟩+r)d
rbf
exp ( − γ ∥ x − x ′ ∥ 2 ) , γ > 0 \exp(-\gamma \|x-x'\|^2),\gamma>0 exp(−γ∥x−x′∥2),γ>0
拉普拉斯核
exp ( − ∣ ∣ x i − x j ∣ ∣ σ ) , σ > 0 \exp(-\frac{||x_i-x_j||}{\sigma}),\sigma>0 exp(−σ∣∣xi−xj∣∣),σ>0
Sigmoid核函数
tanh ( γ ⟨ x , x ′ ⟩ + r ) , γ > 0 , r < 0 \tanh(\gamma \langle x,x'\rangle + r),\gamma>0,r<0 tanh(γ⟨x,x′⟩+r),γ>0,r<0
自定义核函数:参考这里