scrapy_redis分布式爬虫总结 /// scrapy爬虫部署总结
scrapy_redis分布式
1.安装
pip3 install scrapy-redis
2.工作流程
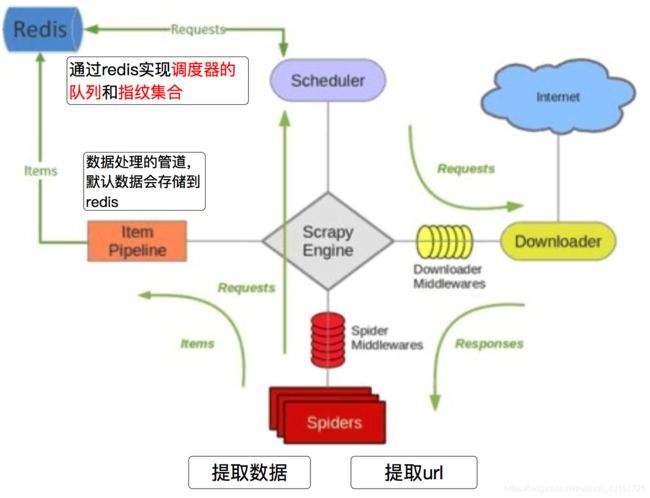
3.简单描述Scrpay框架中各模块的功能作用是什么?可以根据提示回答(提示Scrapy包含模块有Scrapy Engine(引擎)、Scheduler(调度器)、Downloader(下载器)、Spider(爬虫)等)
1.Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
2.Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,
当引擎需要时,交还给引擎
3.Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,
并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
4.Spider(爬虫文件):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,
并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
5.Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
6.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
7. Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件

4.为什么使用redis数据库,redis数据库完成了什么功能?
(1)简介
* Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、
* Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。
* 从2013年5月开始,Redis的开发由Pivotal赞助。
Redis是 NoSQL技术阵营中的一员,它通过多种键值数据类型来适应不同场景下的存储需求,
借助一些高层级的接口使用其可以胜任,如缓存、队列系统的不同角色
(2)Redis 特性
* Redis 与其他 key - value 缓存产品有以下三个特点:
* * Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
* * Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
* * Redis支持数据的备份,即master-slave模式的数据备份。
(3)Redis 优势
* 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
* 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
* 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
* 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
5.scrapy-redis源码总结
一、dmoz (class DmozSpider(CrawlSpider))
scrapy crawl dmoz
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider): """Follow categories and extract links.""" name = 'dmoz' allowed_domains = ['dmoz.org'] start_urls = ['http://www.dmoz.org/'] #定义了一个url的提取规则,将满足条件的交给callback函数处理 rules = [ Rule(LinkExtractor( restrict_css=('.top-cat', '.sub-cat', '.cat-item') ), callback='parse_directory', follow=True), ] def parse_directory(self, response): for div in response.css('.title-and-desc'): #这里将获取到的内容交给引擎 yield { 'name': div.css('.site-title::text').extract_first(), 'description': div.css('.site-descr::text').extract_first().strip(), 'link': div.css('a::attr(href)').extract_first(), }
二、myspider_redis (class MySpider(RedisSpider))
from scrapy_redis.spiders import RedisSpider class MySpider(RedisSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'myspider_redis' #手动设置允许爬取的域 allowed_domains = ['设置允许爬取的域'] # 注意redis-key的格式: redis_key = 'myspider:start_urls' # 可选:等效于allowd_domains(),__init__方法按规定格式写,使用时只需要修改super()里的类名参数即可,一般不用 def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) # 修改这里的类名为当前类名 super(MySpider, self).__init__(*args, **kwargs) def parse(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }
三、mycrawler_redis (class MyCrawler(RedisCrawlSpider))
from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from scrapy_redis.spiders import RedisCrawlSpider class MyCrawler(RedisCrawlSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = 'mycrawler_redis' allowed_domains = ['设置允许爬取的域'] redis_key = 'mycrawler:start_urls' rules = ( # follow all links Rule(LinkExtractor(), callback='parse_page', follow=True), ) # __init__方法必须按规定写,使用时只需要修改super()里的类名参数即可(一般不用) def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop('domain', '') self.allowed_domains = filter(None, domain.split(',')) # 修改这里的类名为当前类名 super(MyCrawler, self).__init__(*args, **kwargs) def parse_page(self, response): return { 'name': response.css('title::text').extract_first(), 'url': response.url, }
总结:
这里表示启用scrapy-redis里的去重组件,不实用scrapy默认的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
使用了scrapy-redis里面的调度器组件,不使用scrapy默认的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
允许暂停,redis请求的记录不会丢失,不清除Redis队列,可以恢复和暂停
SCHEDULER_PERSIST = True
scrapy-redis默认的请求队列形式(有自己的优先级顺序)
是按照redis的有序集合排序出队列的
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
队列形式,请求先进先出
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
使用了栈的形式,请求先进后出
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = { 'example.pipelines.ExamplePipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, }
指定要存储的redis的主机的ip,默认存储在127.0.0.1
REDIS_HOST = 'redis的主机的ip'
定要存储的redis的主机的port,默认6379
REDIS_PORT = '6379'
导出分布式爬虫redis数据库中存储的数据
将数据导出存储进入mongodb
# -*- coding: utf-8 -*- import json import redis import pymongo def main(): # 指定Redis数据库信息 rediscli = redis.StrictRedis(host='localhost', port=6379, db=0) # 指定MongoDB数据库信息 mongocli = pymongo.MongoClient(host='localhost', port=27017) # 指定数据库 db = mongocli['数据库名称'] # 指定集合 sheet = db['集合名称'] while True: # FIFO模式为 blpop,LIFO模式为 brpop,获取键值 source, data = rediscli.blpop(“项目名:items") data = data.decode('utf-8') item = json.loads(data) try: sheet.insert(item) print ("Processing:insert successed" % item) except Exception as err: print ("err procesing: %r" % item) if __name__ == '__main__': main()
将数据导出存入 MySQL
# -*- coding: utf-8 -*- import json import redis import pymysql def main(): # 指定redis数据库信息 rediscli = redis.StrictRedis(host='localhost', port = 6379, db = 0) # 指定mysql数据库 mysqlcli = pymysql.connect(host='localhost', user='用户', passwd='密码', db = '数据库', port=3306, charset='utf8') # 使用cursor()方法获取操作游标 cur = mysqlcli.cursor() while True: # FIFO模式为 blpop,LIFO模式为 brpop,获取键值 source, data = rediscli.blpop("redis中对应的文件夹:items") item = json.loads(data.decode('utf-8')) try: # 使用execute方法执行SQL INSERT语句 cur.execute("sql语句",['数据',....]) # 提交sql事务 mysqlcli.commit() print("inserted successed") except Exception as err: #插入失败 print("Mysql Error",err) mysqlcli.rollback() if __name__ == '__main__': main()
scrapy爬虫部署总结
step1安装使用到的相关库
scrapyd
是运行scrapy爬虫的服务程序,它支持以http命令方式发布、删除、启动、停止爬虫程序。而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本
pip3 install scrapyd
scrapyd-client
发布爬虫需要使用另一个专用工具,就是将代码打包为EGG文件,其次需要将EGG文件上传到远程主机上这些操作需要scrapyd-client来帮助我们完成
pip3 install scrapyd-client
安装完成后可以使用如下命令来检查是否安装成功
scrapyd-deploy -h
step2 修改scrapy项目目录下的scrapy.cfg配置文件
首先需要修改scrapyd.egg (项目的配置文件)
[deploy]
url=http://localhost:6800
project=项目名称
修改完成后即可开始部署共作
本地部署
在此之前,开启scrapyd和redis
项目部署相关命令: 注意这里是项目的名称而不是工程的名称
scrapyd-deploy -p 项目名称
也可以指定版本号
scrapyd-deploy -p 项目名称 --version 版本号
注意:
windows下可能会失败,需要对配置进行修改,首先找到你的项目所在的python环境,找到Scripts文件夹,注意要查看这个文件夹是否在你计算机的环境变量里,没有的话需要添加至环境变量。然后进入Scripts文件夹查看有没有scrapy-deploy这么一个文件,本人在调试的时候发现自己缺少这么一个文件,注意,没有后缀名。没有的话可以来这里下载https://pan.baidu.com/s/1ndDhFqDaVGCv58QTueFIzw。然后,新建一个文本txt,输入
00041d4a936ac0ac7047062a5073c7bf.png
保存退出,最后将文件重命名为scrapy-deploy.bat。重新运行代码即可。
运行爬虫
project (string, required) - the project name
spider (string, required) - the spider name
curl http://localhost:6800/schedule.json -d project=myproject(项目名称) -d spider=somespider(爬虫名称)
关闭爬虫
project (string, required) - the project name
job (string, required) - the job id
curl http://localhost:6800/cancel.json -d project=myproject -d job='jobid'
获取部署的爬虫项目列表
curl http://localhost:6800/listprojects.json
获取项目下的爬虫文件列表
curl http://localhost:6800/listspiders.json?project=myproject
获取工程下的爬虫运行状态
curl http://localhost:6800/listjobs.json?project=myproject
删除部署的爬虫项目
project (string, required) - the project name
curl http://localhost:6800/delproject.json -d project=myproject
远端部署
step1.购买linux系统服务器
step2.在终端上登录服务器
step3.配置项目运行环境
配置python环境(ubuntu自带python3环境))
安装pip3:sudo apt install python3-pip
安装scrapy:pip3 install scrapy -i https://pypi.douban.com/simple/
如果安装失败添加如下依赖:
安装scrapyd: pip3 install scrapyd
安装scrapyd-client: pip3 install scrapyd-client
添加爬虫运行的三方库:
pip3 install requests
pip3 install pymysql
pip3 install pymongodb
step4: 修改scrapyd的配置文件,允许外网访问
查找配置文件的路径:find -name default_scrapyd.
修改配置文件: sudo vim 路径

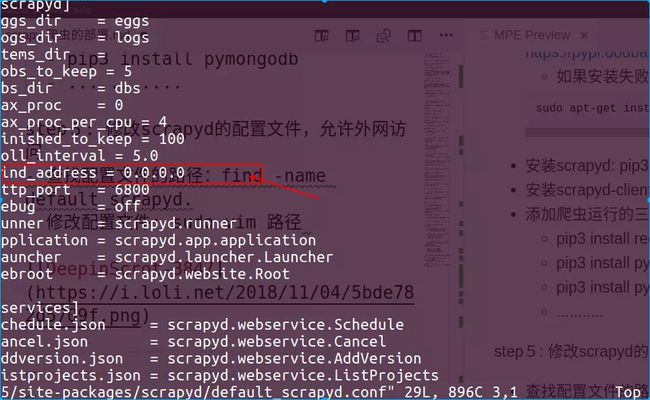
注意:此时启动scrapayd服务6800端口还不能访问
step5:要去服务器安全组配置
进入服务安全组选项添加安全组
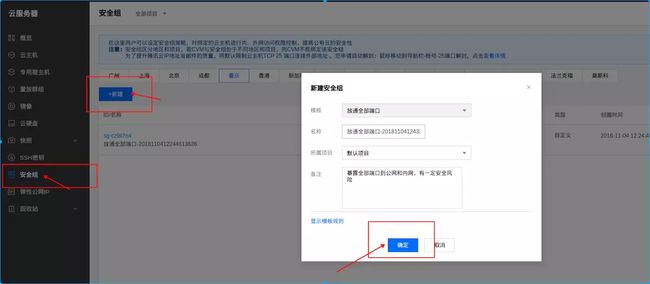
添加成功后,点击修改规则,添加如下信息(配置目的:允许访问6800端口
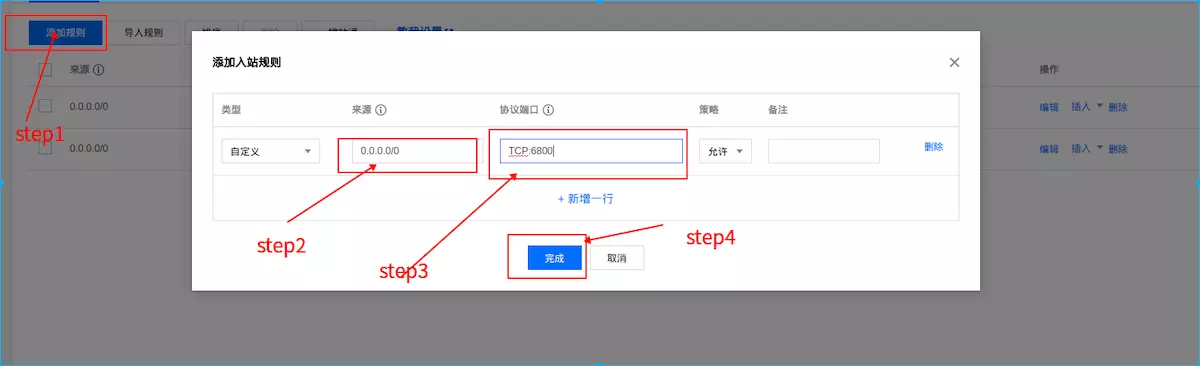
完成后返回到云主机菜单,找到配置安全组菜单,跟换为刚才添加的安全组

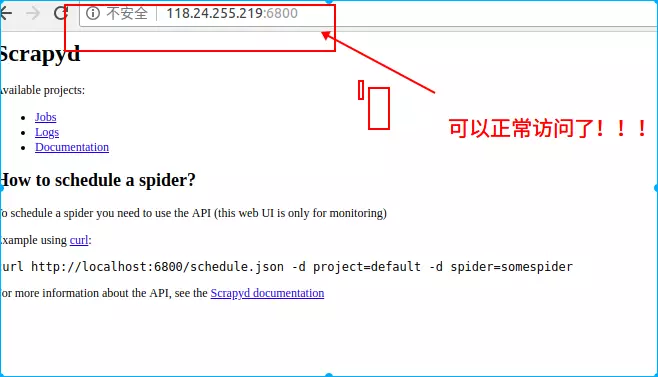
最终完成后,在浏览器中输入ip地址和端口,显示如下图,说明配置成功
最后部署爬虫项目到服务器:
首先需要修改scrapyd.egg (项目的配置文件)
[deploy]
url = http://118.24.255.219:6800
project=项目名称
之后的操作步骤与本地部署一致
如果涉及到数据库,则需要在远程服务器中安装mysql
sudo apt update
sudo apt-get install mysql-server mysql-client
修改配置文件允许外网访问
找到mysql配置文件并做如下修改:允许远程连接
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
将
bind-address= 127.0.0.1
注释掉或则修改为
bind-address= 0.0.0.0
授权root账户允许远程访问:
grant all privileges on . to root@'%' identified by 'password' with grant option;
注意:如果还是不能远程访问就重启mysql服务
sudo service mysql stop sudo service mysql start
部署流程
相关api调用说明
gerapy作用和使用流程总结