docx4j操作word文档之生成页码、合并多个文档
docx4j操作word文档:
- 动态生成表格行数并填充数据
- 单元格内填充图片
- 合并多个word文档(包含页码,纸张方向等等)
1.动态生成表格行数并填充数据
首先创建模板文件.docx,如图:
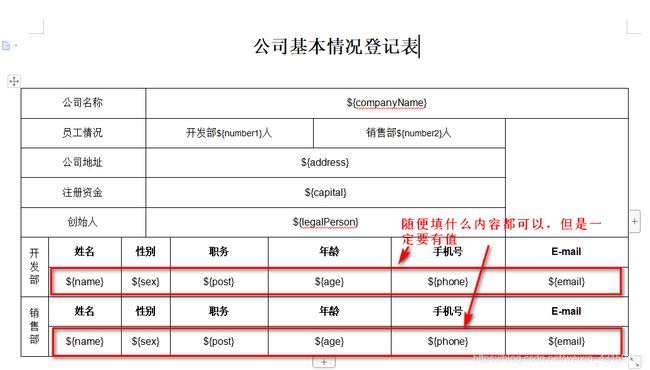
代码如下:
import com.bootdo.common.utils.Docx4jUtils;
import org.docx4j.model.datastorage.migration.VariablePrepare;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.wml.Tbl;
import org.docx4j.wml.Tr;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class Docx4jDemo2 {
public static void main(String[] args) {
Map<String, String> data = new HashMap<>();
data.put("companyName", "阿里巴巴网络技术有限公司");
data.put("number1", "100");
data.put("number2", "100");
data.put("address", "中国杭州");
data.put("capital", "59690万美元");
data.put("legalPerson", "马云");
//模拟开发部数据
List<String[]> dataList = new ArrayList<>();
for (int i = 0; i <= 100; i++) {
//按照模板中单元格顺序添加数据
dataList.add(new String[]{"张三", "男", "员工", "24", "13666666666", "[email protected]"});
}
//模拟销售部数据
List<String[]> dataList2 = new ArrayList<>();
for (int i = 0; i <= 100; i++) {
dataList2.add(new String[]{"李四", "女", "员工", "22", "13888888888", "[email protected]"});
}
//合并文档
WordprocessingMLPackage wordMLPackage=null;
WordprocessingMLPackage wordMLPackage2 =null;
InputStream templateInputStream =null;
try {
//docx4j生成的文档
wordMLPackage = replaceData(data, dataList, dataList2);
//加载本地的word文档
templateInputStream = new FileInputStream("D://1.docx");
wordMLPackage2= WordprocessingMLPackage.load(templateInputStream);
} catch (Exception e) {
e.printStackTrace();
}
List<WordprocessingMLPackage> wordList = new ArrayList<>();
wordList.add(wordMLPackage);
wordList.add(wordMLPackage2);
wordList.add(wordMLPackage);
wordList.add(wordMLPackage2);
try {
mergeWord(wordList);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 加载模板并替换数据
*
* @param data
* @return
* @throws Exception
*/
public static void replaceData(Map<String, String> data, List<String[]> dataList, List<String[]> dataList2) throws Exception {
final String TEMPLATE_NAME = "D://2.docx";
InputStream templateInputStream = new FileInputStream(TEMPLATE_NAME);
//加载模板文件并创建WordprocessingMLPackage对象
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.load(templateInputStream);
MainDocumentPart documentPart = wordMLPackage.getMainDocumentPart();
VariablePrepare.prepare(wordMLPackage);
documentPart.variableReplace(data);
List<Tbl> tbls = Docx4jUtils.getAllTbl(wordMLPackage);
//获取表格对象
Tbl firstTbl = tbls.get(0);
List<Object> trObjList = firstTbl.getContent();
Tr tr = null;
//替换开发部数据
if (dataList != null && !dataList.isEmpty()) {
int index1 = 6;
//获取需要填数据的行
tr = (Tr) trObjList.get(index1);
//填数据
Docx4jUtils.replaceTrData(firstTbl, tr, dataList, index1);
}
//替换销售部数据
if (dataList2 != null && !dataList2.isEmpty()) {
//重新获取表格
trObjList = firstTbl.getContent();
//获取填数据的行的下标(从0开始)
int index2 = 5 + dataList.size() + 2;
tr = (Tr) trObjList.get(index2);
Docx4jUtils.replaceTrData(firstTbl, tr, dataList2, index2);
}
//合并单元格
Docx4jUtils.mergeCellsVertically(firstTbl, 0, 5, 5 + dataList.size());
Docx4jUtils.mergeCellsVertically(firstTbl, 0, 5 + dataList.size() + 1, 5 + dataList.size() + dataList2.size() + 1);
//插入图片
File file = new File("D://logo.jpg");
Docx4jUtils.insertImgToTbl(file,wordMLPackage,1,3);
//生成页脚以及页码
Relationship relationship = Docx4jUtils.createFooterPart(wordMLPackage);
Docx4jUtils.createFooterReference(wordMLPackage, relationship);
OutputStream os = new FileOutputStream(new File("D://test.docx"));
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
wordMLPackage.save(outputStream);
outputStream.writeTo(os);
os.close();
outputStream.close();
templateInputStream.close();
}
}
2.单元格内填充图片
填充图片可以实现,但是图片自适用大小比较难,而且,生成文档用WPS和Office打开会有差异。可以参照下述链接:
使用docx4j根据书签自动替换word中的文本和图片,图片自适应大小
3.合并word文档
为了达到演示效果,示例采用两个word文档,一个是上面生成的(纸张方向为横向),一个是已经存在的(纸张方向为纵向)。
因为把文档生成到了本地,现在演示文档合并,又要从本地加载,避免麻烦,所以修改返参为WordprocessingMLPackage。然后合并是直接利用。
/**
* 合并文件
* @param list
* @throws Exception
*/
public static void mergeWord(List<WordprocessingMLPackage> list) throws Exception{
List<BlockRange> blockRanges = new ArrayList<BlockRange>();
HashMap<String, Object> result = new HashMap<>();
if (list != null && !list.isEmpty()) {
for (int i = 0; i < list.size(); i++) {
WordprocessingMLPackage wordMLPackage = list.get(i);
BlockRange block = new BlockRange(wordMLPackage);
blockRanges.add(block);
if (i == 2) {
//是否重新开始页码
block.setRestartPageNumbering(true);
} else {
block.setRestartPageNumbering(false);
}
// block.setStyleHandler(BlockRange.StyleHandler.USE_EARLIER);
block.setNumberingHandler(BlockRange.NumberingHandler.ADD_NEW_LIST);
block.setHeaderBehaviour(BlockRange.HfBehaviour.DEFAULT);
block.setFooterBehaviour(BlockRange.HfBehaviour.DEFAULT);
//设置分节符(下一页)
block.setSectionBreakBefore(BlockRange.SectionBreakBefore.NEXT_PAGE);
}
// Perform the actual merge
DocumentBuilder documentBuilder = new DocumentBuilder();
WordprocessingMLPackage output = documentBuilder.buildOpenDocument(blockRanges);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
output.save(outputStream);
OutputStream os = new FileOutputStream(new File("D://test2.docx"));
outputStream.writeTo(os);
os.close();
outputStream.close();
}
}
工具类代码如下:
import org.docx4j.XmlUtils;
import org.docx4j.dml.wordprocessingDrawing.Inline;
import org.docx4j.jaxb.Context;
import org.docx4j.model.structure.SectionWrapper;
import org.docx4j.openpackaging.exceptions.InvalidFormatException;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.openpackaging.parts.WordprocessingML.BinaryPartAbstractImage;
import org.docx4j.openpackaging.parts.WordprocessingML.FooterPart;
import org.docx4j.openpackaging.parts.WordprocessingML.MainDocumentPart;
import org.docx4j.openpackaging.parts.relationships.Namespaces;
import org.docx4j.relationships.Relationship;
import org.docx4j.wml.*;
import org.docx4j.wml.R;
import javax.xml.bind.JAXBElement;
import javax.xml.namespace.QName;
import java.io.*;
import java.math.BigInteger;
import java.util.*;
public class Docx4jUtils {
public static ObjectFactory factory = Context.getWmlObjectFactory();
//替换tr数据,其他插入
public static void replaceTrData(Tbl tbl, Tr tr, List<String[]> dataList, int trIndex) throws Exception {
TrPr trPr = XmlUtils.deepCopy(tr.getTrPr());
String tcContent = null;
String[] tcMarshaArr = getTcMarshalStr(tr);
String[] dataArr = null;
for (int i = 0, iLen = dataList.size(); i < iLen; i++) {
dataArr = dataList.get(i);
Tr newTr = null;
Tc newTc = null;
if (i == 0) {
newTr = tr;
} else {
newTr = factory.createTr();
if (trPr != null) {
newTr.setTrPr(trPr);
}
newTc = factory.createTc();
newTr.getContent().add(newTc);
}
for (int j = 0, jLen = dataArr.length; j < jLen; j++) {
tcContent = tcMarshaArr[j];
if (tcContent != null) {
tcContent = tcContent.replaceAll("()(.*?)( )", "" + dataArr[j] + "");
newTc = (Tc) XmlUtils.unmarshalString(tcContent);
} else {
newTc = factory.createTc();
setNewTcContent(newTc, dataArr[j]);
}
// 新增tr
if (i != 0) {
newTr.getContent().add(newTc);
} else {
// 替换
newTr.getContent().set(j + 1, newTc);
}
}
if (i != 0) {
tbl.getContent().add(trIndex + i, newTr);
}
}
}
/**
* 获取单元格字符串
*
* @param tr 行对象
* @return 字符数组
*/
public static String[] getTcMarshalStr(Tr tr) {
List<Object> tcObjList = tr.getContent();
String[] marshaArr = new String[7];
// 跳过层次
for (int i = 1, len = tcObjList.size(); i < len; i++) {
marshaArr[i - 1] = XmlUtils.marshaltoString(tcObjList.get(i), true, false);
}
return marshaArr;
}
/**
* 设置单元格内容
*
* @param tc 单元格
* @param content 内容
*/
public static void setNewTcContent(Tc tc, String content) {
P p = factory.createP();
tc.getContent().add(p);
R run = factory.createR();
p.getContent().add(run);
if (content != null) {
String[] contentArr = content.split("\n");
Text text = factory.createText();
text.setSpace("preserve");
text.setValue(contentArr[0]);
run.getContent().add(text);
for (int i = 1, len = contentArr.length; i < len; i++) {
Br br = factory.createBr();
run.getContent().add(br);// 换行
text = factory.createText();
text.setSpace("preserve");
text.setValue(contentArr[i]);
run.getContent().add(text);
}
}
}
/**
* 跨行合并
*
* @param tbl 表名
* @param col 列数
* @param fromRow 起始行数
* @param toRow 结束行数
*/
public static void mergeCellsVertically(Tbl tbl, int col, int fromRow, int toRow) {
if (col < 0 || fromRow < 0 || toRow < 0) {
return;
}
for (int rowIndex = fromRow; rowIndex <= toRow; rowIndex++) {
Tc tc = getTc(tbl, rowIndex, col);
if (tc == null) {
break;
}
TcPr tcPr = getTcPr(tc);
TcPrInner.VMerge vMerge = tcPr.getVMerge();
if (vMerge == null) {
vMerge = factory.createTcPrInnerVMerge();
tcPr.setVMerge(vMerge);
}
if (rowIndex == fromRow) {
vMerge.setVal("restart");
} else {
vMerge.setVal("continue");
}
}
}
/**
* @param tc
* @return
*/
public static TcPr getTcPr(Tc tc) {
TcPr tcPr = tc.getTcPr();
if (tcPr == null) {
tcPr = new TcPr();
tc.setTcPr(tcPr);
}
return tcPr;
}
//得到指定类型的元素
public static List<Object> getAllElementFromObject(Object obj,
Class<?> toSearch) {
List<Object> result = new ArrayList<Object>();
if (obj instanceof JAXBElement) {
obj = ((JAXBElement<?>) obj).getValue();
}
if (obj.getClass().equals(toSearch)) {
result.add(obj);
} else if (obj instanceof ContentAccessor) {
List<?> children = ((ContentAccessor) obj).getContent();
for (Object child : children) {
result.addAll(getAllElementFromObject(child, toSearch));
}
}
return result;
}
//得到所有的表格
public static List<Tbl> getAllTbl(WordprocessingMLPackage wordMLPackage) {
MainDocumentPart mainDocPart = wordMLPackage.getMainDocumentPart();
List<Object> objList = Docx4jUtils.getAllElementFromObject(mainDocPart, Tbl.class);
if (objList == null) {
return null;
}
List<Tbl> tblList = new ArrayList<Tbl>();
for (Object obj : objList) {
if (obj instanceof Tbl) {
Tbl tbl = (Tbl) obj;
tblList.add(tbl);
}
}
return tblList;
}
//得到指定位置的单元格
public static Tc getTc(Tbl tbl, int row, int cell) {
if (row < 0 || cell < 0) {
return null;
}
List<Tr> trList = getTblAllTr(tbl);
if (row >= trList.size()) {
return null;
}
List<Tc> tcList = getTrAllCell(trList.get(row));
if (cell >= tcList.size()) {
return null;
}
return tcList.get(cell);
}
//得到表格所有的行
public static List<Tr> getTblAllTr(Tbl tbl) {
List<Object> objList = getAllElementFromObject(tbl, Tr.class);
List<Tr> trList = new ArrayList<Tr>();
if (objList == null) {
return trList;
}
for (Object obj : objList) {
if (obj instanceof Tr) {
Tr tr = (Tr) obj;
trList.add(tr);
}
}
return trList;
}
//获取某一行的单元格
public static List<Tc> getTrAllCell(Tr tr) {
List<Object> objList = getAllElementFromObject(tr, Tc.class);
List<Tc> tcList = new ArrayList<Tc>();
if (objList == null) {
return tcList;
}
for (Object tcObj : objList) {
if (tcObj instanceof Tc) {
Tc objTc = (Tc) tcObj;
tcList.add(objTc);
}
}
return tcList;
}
/**
* @Description:设置单元格内容,content为null则清除单元格内容
*/
public void setTcContent(Tc tc, RPr rpr, String content) {
List<Object> pList = tc.getContent();
P p = null;
if (pList != null && pList.size() > 0) {
if (pList.get(0) instanceof P) {
p = (P) pList.get(0);
}
} else {
p = new P();
tc.getContent().add(p);
}
R run = null;
List<Object> rList = p.getContent();
if (rList != null && rList.size() > 0) {
for (int i = 0, len = rList.size(); i < len; i++) {
// 清除内容(所有的r
p.getContent().remove(0);
}
}
run = new R();
p.getContent().add(run);
if (content != null) {
String[] contentArr = content.split("\n");
Text text = new Text();
text.setSpace("preserve");
text.setValue(contentArr[0]);
run.setRPr(rpr);
run.getContent().add(text);
for (int i = 1, len = contentArr.length; i < len; i++) {
Br br = new Br();
run.getContent().add(br);// 换行
text = new Text();
text.setSpace("preserve");
text.setValue(contentArr[i]);
run.setRPr(rpr);
run.getContent().add(text);
}
}
}
//向表格插入图片
public static void insertImgToTbl(File file, WordprocessingMLPackage wordMLPackage, int rowIndex, int colIndex) throws Exception {
factory = Context.getWmlObjectFactory();
List<Tbl> tbls = getAllTbl(wordMLPackage);
Tbl tbl = tbls.get(0);
Tr tr = getTblAllTr(tbl).get(rowIndex);
Tc tc = getTc(tbl, rowIndex, colIndex);
Inline newInline = createInlineImage(file, wordMLPackage);
P paragraphWithImage = addInlineImageToParagraph(newInline);
PPr pPr = factory.createPPr();
PPrBase.Spacing spacing = new PPrBase.Spacing();
spacing.setBefore(BigInteger.valueOf(0));
spacing.setAfter(BigInteger.valueOf(0));
spacing.setLine(BigInteger.valueOf(0));
pPr.setSpacing(spacing);
paragraphWithImage.setPPr(pPr);
tc.getContent().add(paragraphWithImage);
//tr.getContent().add(tc);
}
/**
* 我们将文件转换成字节数组, 并用它创建一个内联图片.
*
* @param file
* @return
* @throws Exception
*/
private static Inline createInlineImage(File file, WordprocessingMLPackage wordMLPackage) throws Exception {
byte[] bytes = convertImageToByteArray(file);
BinaryPartAbstractImage imagePart = BinaryPartAbstractImage.createImagePart(wordMLPackage, bytes);
int docPrId = 1;
int cNvPrId = 2;
return imagePart.createImageInline("Filename hint", "Alternative text", docPrId, cNvPrId, false, 1800);
}
/**
* 将图片从文件转换成字节数组.
*
* @param file
* @return
* @throws FileNotFoundException
* @throws IOException
*/
private static byte[] convertImageToByteArray(File file) throws FileNotFoundException, IOException {
InputStream is = new FileInputStream(file);
long length = file.length();
// You cannot create an array using a long, it needs to be an int.
if (length > Integer.MAX_VALUE) {
System.out.println("File too large!!");
}
byte[] bytes = new byte[(int) length];
int offset = 0;
int numRead = 0;
while (offset < bytes.length && (numRead = is.read(bytes, offset, bytes.length - offset)) >= 0) {
offset += numRead;
}
// Ensure all the bytes have been read
if (offset < bytes.length) {
System.out.println("Could not completely read file " + file.getName());
}
is.close();
return bytes;
}
/**
* 向新的段落中添加内联图片并返回这个段落
*
* @param inline
* @return
*/
private static P addInlineImageToParagraph(Inline inline) {
// Now add the in-line image to a paragraph
ObjectFactory factory = new ObjectFactory();
P paragraph = factory.createP();
R run = factory.createR();
paragraph.getContent().add(run);
Drawing drawing = factory.createDrawing();
run.getContent().add(drawing);
drawing.getAnchorOrInline().add(inline);
return paragraph;
}
/**
* @Description: 设置页面大小及纸张方向 landscape横向
*/
public static void setDocumentSize(WordprocessingMLPackage wordPackage,
ObjectFactory factory, String width, String height,
STPageOrientation stValue) {
SectPr sectPr = getDocSectPr(wordPackage);
SectPr.PgSz pgSz = sectPr.getPgSz();
//System.out.println(pgSz.getH().toString()+"-"+pgSz.getW().toString()+"-"+pgSz.getOrient().value());
if (pgSz == null) {
pgSz = factory.createSectPrPgSz();
sectPr.setPgSz(pgSz);
}
if (StringUtils.isNotBlank(width)) {
pgSz.setW(new BigInteger(width));
}
if (StringUtils.isNotBlank(height)) {
pgSz.setH(new BigInteger(height));
}
if (stValue != null) {
pgSz.setOrient(stValue);
}
// System.out.println(pgSz.getCode().toString()+"-"+pgSz.getH().toString()+"-"+pgSz.getW().toString()+"-"+pgSz.getOrient().value());
}
/**
* @Description: 设置分节符 nextPage:下一页 continuous:连续 evenPage:偶数页 oddPage:奇数页
*/
public static void setDocSectionBreak(WordprocessingMLPackage wordPackage, ObjectFactory factory, String sectValType) {
P p = factory.createP();
PPr pPr = factory.createPPr();
SectPr sectPr = factory.createSectPr();
SectPr.Type sectType = factory.createSectPrType();
sectType.setVal(sectValType);
sectPr.setType(sectType);
pPr.setSectPr(sectPr);
p.setPPr(pPr);
wordPackage.getMainDocumentPart().addObject(p);
}
public static SectPr getDocSectPr(WordprocessingMLPackage wordPackage) {
SectPr sectPr = wordPackage.getDocumentModel().getSections().get(0).getSectPr();
return sectPr;
}
/**
* 创建分页符
*
* @return
*/
public static P getPageBreak() {
P p = new P();
R r = new R();
org.docx4j.wml.Br br = new org.docx4j.wml.Br();
br.setType(STBrType.PAGE);
r.getContent().add(br);
p.getContent().add(r);
return p;
}
//添加页脚并添加页码
/**
* 创建页脚的组件
*
* @return
* @throws InvalidFormatException
*/
public static Relationship createFooterPart(WordprocessingMLPackage wordMLPackage) throws InvalidFormatException {
FooterPart footerPart = new FooterPart();
footerPart.setPackage(wordMLPackage);
footerPart.setJaxbElement(createFooterWithPageNr());
return wordMLPackage.getMainDocumentPart().addTargetPart(footerPart);
}
/**
* First we retrieve the document sections from the package. As we want to add
* a footer, we get the last section and take the section properties from it.
* The section is always present, but it might not have properties, so we check
* if they exist to see if we should create them. If they need to be created,
* we do and add them to the main document part and the section.
* Then we create a reference to the footer, give it the id of the relationship,
* set the type to header/footer reference and add it to the collection of
* references to headers and footers in the section properties.
* 创建页脚引用关系
*
* @param relationship
*/
public static void createFooterReference(WordprocessingMLPackage wordMLPackage, Relationship relationship) {
List<SectionWrapper> sections = wordMLPackage.getDocumentModel().getSections();
SectPr sectionProperties = sections.get(sections.size() - 1).getSectPr();
// There is always a section wrapper, but it might not contain a sectPr
if (sectionProperties == null) {
sectionProperties = factory.createSectPr();
wordMLPackage.getMainDocumentPart().addObject(sectionProperties);
sections.get(sections.size() - 1).setSectPr(sectionProperties);
}
FooterReference footerReference = factory.createFooterReference();
footerReference.setId(relationship.getId());
footerReference.setType(HdrFtrRef.DEFAULT);
sectionProperties.getEGHdrFtrReferences().add(footerReference);
}
/**
* As in the previous example, we create a footer and a paragraph object. But
* this time, instead of adding text to a run, we add a field. And just as with
* the table of content, we have to add a begin and end character around the
* actual field with the page number. Finally we add the paragraph to the
* content of the footer and then return it.
* 生成页码
*
* @return
*/
public static Ftr createFooterWithPageNr() {
Ftr ftr = factory.createFtr();
P paragraph = factory.createP();
addFieldBegin(paragraph);
addPageNumberField(paragraph);
addFieldEnd(paragraph);
ftr.getContent().add(paragraph);
return ftr;
}
/**
* Creating the page number field is nearly the same as creating the field in
* the TOC example. The only difference is in the value. We use the PAGE
* command, which prints the number of the current page, together with the
* MERGEFORMAT switch, which indicates that the current formatting should be
* preserved when the field is updated.
*
* @param paragraph
*/
public static void addPageNumberField(P paragraph) {
R run = factory.createR();
Text txt = new Text();
txt.setSpace("preserve");
txt.setValue(" PAGE \\* MERGEFORMAT ");
run.getContent().add(factory.createRInstrText(txt));
paragraph.getContent().add(run);
// STNumberFormat.DECIMAL_FULL_WIDTH_2; //双字节阿拉伯数字
// STNumberFormat.DECIMAL_HALF_WIDTH;//单字节阿拉伯数字
}
/**
* Every fields needs to be delimited by complex field characters. This method
* adds the delimiter that precedes the actual field to the given paragraph.
*
* @param paragraph
*/
public static void addFieldBegin(P paragraph) {
R run = factory.createR();
FldChar fldchar = factory.createFldChar();
fldchar.setFldCharType(STFldCharType.BEGIN);
run.getContent().add(fldchar);
paragraph.getContent().add(run);
}
/**
* Every fields needs to be delimited by complex field characters. This method
* adds the delimiter that follows the actual field to the given paragraph.
*
* @param paragraph
*/
public static void addFieldEnd(P paragraph) {
FldChar fldcharend = factory.createFldChar();
fldcharend.setFldCharType(STFldCharType.END);
R run3 = factory.createR();
run3.getContent().add(fldcharend);
paragraph.getContent().add(run3);
}
/**
* Adds a page break to the document.
*
* @param documentPart
*/
public static void addPageBreak(MainDocumentPart documentPart) {
Br breakObj = new Br();
breakObj.setType(STBrType.PAGE);
P paragraph = factory.createP();
paragraph.getContent().add(breakObj);
documentPart.getJaxbElement().getBody().getContent().add(paragraph);
}
//生成目录
/**
* 将目录表添加到文档.
*
* 首先我们创建段落. 然后添加标记域开始的指示符, 然后添加域内容(真正的目录表), 接着添加域
* 结束的指示符. 最后将段落添加到给定文档的JAXB元素中.
*
* @param documentPart
*/
public static void addTableOfContent(MainDocumentPart documentPart) {
P paragraph = factory.createP();
addFieldBegin2(paragraph);
addTableOfContentField(paragraph);
addFieldEnd2(paragraph);
documentPart.getJaxbElement().getBody().getContent().add(paragraph);
}
public static void addTableOfContentField(P paragraph) {
R run = factory.createR();
Text txt = new Text();
txt.setSpace("preserve");
txt.setValue("TOC \\o \"1-3\" \\h \\z \\u");
run.getContent().add(factory.createRInstrText(txt));
paragraph.getContent().add(run);
}
private static void addFieldBegin2(P paragraph) {
R run = factory.createR();
FldChar fldchar = factory.createFldChar();
fldchar.setFldCharType(STFldCharType.BEGIN);
fldchar.setDirty(true);
run.getContent().add(getWrappedFldChar(fldchar));
paragraph.getContent().add(run);
}
private static void addFieldEnd2(P paragraph) {
R run = factory.createR();
FldChar fldcharend = factory.createFldChar();
fldcharend.setFldCharType(STFldCharType.END);
run.getContent().add(getWrappedFldChar(fldcharend));
paragraph.getContent().add(run);
}
public static JAXBElement getWrappedFldChar(FldChar fldchar) {
return new JAXBElement(new QName(Namespaces.NS_WORD12, "fldChar"), FldChar.class, fldchar);
}
}
总结
至此,已经实现了动态生成表格行数,单元格插入图片,以及合并多个word文档,同时设置纸张方向、分页符、页脚和页码等等。目录的生成在工具类里也有,本人亲测可用。
提示:文档中的各种样式,包括字体,颜色,表格边框等等都可以在模板中设置好,也可以用java代码实现,具体api网上有许多,这里就不写了。生成目录时,一定要在模板中的文档标题设置大纲级别,因为目录的生成会依靠这个。
jar包:
合并文件时用到了Plutext-Enterprise-3.3.0.6.jar这个包,但是在Maven仓库找不到,百度云链接如下:
https://pan.baidu.com/s/1k5TraeDfA_bpDoQxMmY5RA
提取码:mabl