机器学习入门之线性回归
机器学习入门之线性回归
大家好,我是一枚大三计算机专业的大学生,毕业之后打算往人工智能方向发展,目前的编程语言基本上是自学的(大一大二都玩过去了TAT),最近看了Flare老师的:“Python3入门人工智能 掌握机器学习+深度学习 提升实战能力”,感觉特别不错,所以和大家分享一下内容以及学习笔记。加油!欧里给!
线性回归
线性回归作为机器学习里面很基础的一部分也是很重要的一部分,我们看看百度词条的解释:(看上去很复杂,其实就是一元一次方程)

话不多说,我们开始做一个简单的练习
#一开始,我们先引入一个用来练习的数据集
import pandas as pd
data = pd.read_csv('generated_data.csv')
数据集很简单:
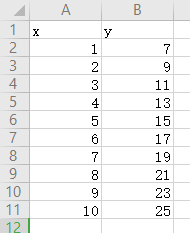 应该可以很轻松看出,x与y之间的关系是y=2x+5
应该可以很轻松看出,x与y之间的关系是y=2x+5
#data赋值
x = data.loc[:,'x']#这里的意思是:把'x'那一列的所有行数据赋值给新的x
y = data.loc[:,'y']#同理
print(x,'\n',y)#结果如下

 (这里注意左边一列为序号,右边为实际值)
(这里注意左边一列为序号,右边为实际值)
#数据可视化
from matplotlib import pyplot as plt
plt.figure(figsize=(10,10))
plt.scatter(x,y)#绘制散点图
plt.show()
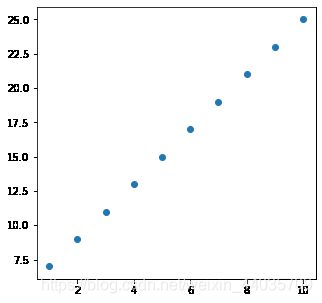 (我们给的数据很规律,所有目测基本在一条直线上)
(我们给的数据很规律,所有目测基本在一条直线上)
建立线性回归模型
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()
lr_model.fit(x,y)
y_predict = lr_model.predict(x)
plt.figure()
plt.plot(y,y_predict)
plt.show()
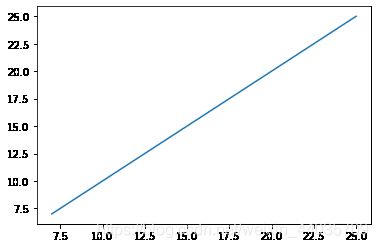


以上我们可以很清晰的看出:我们训练出来的回归直线基本与原数据重合,也就是每个点到回归直线的距离之和最短。其中,coef_可以计算出斜率a,intercept_可以计算出截距b(也就是y=ax+b),最后是线性回归两个很重要的特征值:MSE均方误差以及R2方差(均方误差越小越好,方差约接近零越好)
掌握以上知识点,下面我们实战一下:线性回归预测房价
#导入数据集
import pandas as pd
import numpy as np
data = pd.read_csv('usa_housing_price.csv')
#数据可视化
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(10,10))
fig1 =plt.subplot(231)
plt.scatter(data.loc[:,'Avg. Area Income'],data.loc[:,'Price'])
plt.title('Price VS Income')
。。。部分省略。。。
plt.show()
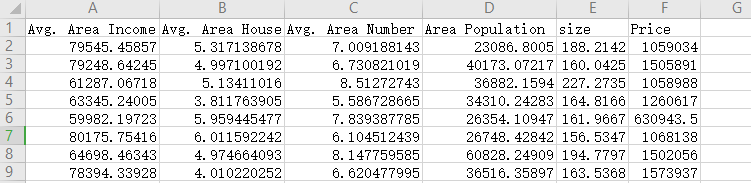
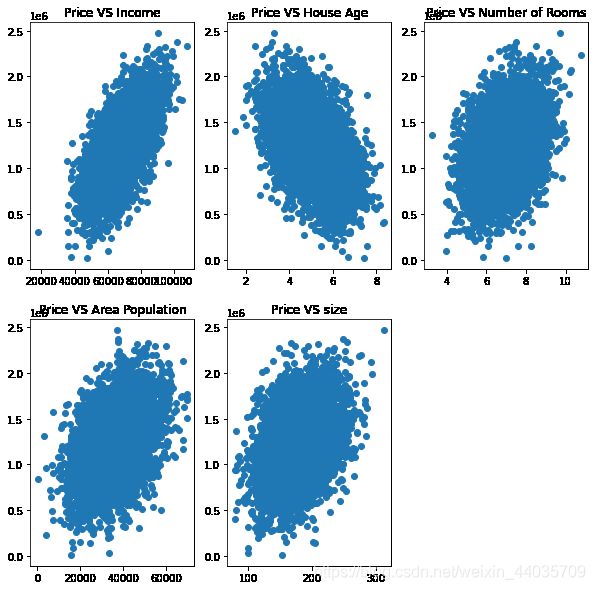
我们先用单因子建立线性回归模型,看看结果如何?
#define X and y
X = data.loc[:,'size']
y = data.loc[:,'Price']
X = np.array(X).reshape(-1,1)#这里注意转化X的格式,-1为任意行,1为一列。(不转换训练的时候会报错)
#set up the linear regression model
from sklearn.linear_model import LinearRegression
LR1 = LinearRegression()
#train the model
LR1.fit(X,y)
y_predict_1 = LR1.predict(X)
fig6 = plt.figure(figsize=(8,5))
plt.scatter(X,y)
plt.plot(X,y_predict_1,'r')
plt.show()
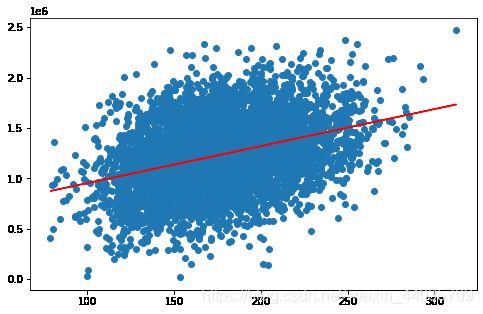 在单因子的情况下,此时的数据是非常离散的,比如在size=200的情况下,房价最高可以去到20w,最低甚至到3w,所以只用一个条件预测房价,是不准确的。
在单因子的情况下,此时的数据是非常离散的,比如在size=200的情况下,房价最高可以去到20w,最低甚至到3w,所以只用一个条件预测房价,是不准确的。
多因子建立线性回归模型
#define X_multi
X_multi = data.drop(['Price'],axis=1)
#set up 2nd linear model
LR_multi = LinearRegression()
#train the model
LR_multi.fit(X_multi,y)
y_predict_multi = LR_multi.predict(X_multi)
fig7 = plt.figure(figsize=(8,5))
plt.scatter(y,y_predict_multi)#因为X_multi是多因子的,维度与y_predict_multi不用无法作图,所以我们用实际房价与预测房价作图
plt.show()
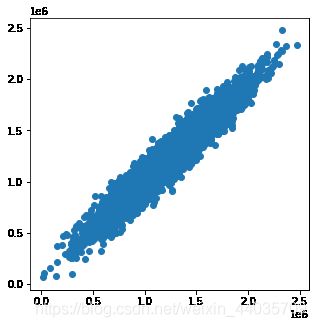 实际房价与预测房价基本在一条45°的线上,而且波动范围也在接受范围之内,模型建立成功!
实际房价与预测房价基本在一条45°的线上,而且波动范围也在接受范围之内,模型建立成功!
#预测收入65000,房子年龄5年,5房间,人口密度30000,面积200平大概买多少钱
X_test = [65000,5,5,30000,200]
X_test = np.array(X_test).reshape(1,-1)
y_test_predict = LR_multi.predict(X_test)
print(y_test_predict)
结果是:[817052.19516298],81.7万
最后总结
因为事物的复杂性,有时候我们不能通过一个条件进行分析,(总不能因为橘子难看就不吃吧,丑橘好吃的不得了!!!)第一次写博客,没啥经验也有很多疏漏的地方,欢迎各位在评论区指出哈,我个人也才学习机器学习一点浅薄的知识,希望有朝一日,能设计出钢铁侠里面的贾维斯AI,啊哈哈哈哈哈哈~