Linux系统启动
本文主要介绍了Linux系统启动流程相关内容,包括UEFI、BIOS启动过程,GPT、MBR分区表、Grub Legacy、Grub 2相关介绍,同时介绍了内核参数,以及SysV、Upstart、SystemD的介绍
文章目录
- 一、概览
- 二、BIOS
- 1. BIOS
- 主要功能
- CMOS与BIOS
- Boot Sequence
- 2. UEFI
- 概述
- UEFI的组成
- 引导
- UEFI启动
- CSM启动
- UEFI与BIOS在启动过程上的区别
- UEFI启动过程
- BIOS启动过程
- 总结
- 三、Boot Loader
- 四、GRUB
- 1. Boot Loader
- 2. Grub概述
- 3. Grub的安装位置
- 4. 启动Kernel前的准备
- 5 .Grub Legacy
- 功能
- 配置文件
- 命令行
- 安装grub
- 手动在grub命令行接口启动系统
- 6. Grub 2
- 配置文件
- 应用
- 五、Kernel
- 启动相关内核参数
- 内核日志级别
- 六、init
- 1. SysV init
- 运行级别
- SysV init运行流程
- /etc/inittab
- /etc/rc.d/rc.sysinit
- /etc/rc.d/rc.local
- Sysvinit 和系统关闭
- 2. Upstart init
- Upstart 简介
- Upstart启动过程
- 配置文件
- /etc/init/*.conf
- 3. Systemd
- Systemd特点
- 更快启动
- 按需启动服务
- 启动挂载点和自动挂载的管理
- 实现事务性依赖关系管理
- 日志服务
- Unit
- Target Unit与运行级别
- CentOS 7启动次序
- 七、相关命令
- init
- runlevel
- uname
- systemctl
- 例
一、概览
开机实际上是一件很复杂的事情,该动作的主要目的就是让冷冰冰的机器帮助我们完成需要的工作。本文所介绍的,只是Linux系统的大致启动过程
需要说明的是,近年来从底层的BIOS到上层的init程序都有了一些变化,而系统启动的大致原理依旧,本章节先以“BIOS”来表示Legacy BIOS与UEFI,以GRUB表示引导程序,以INIT来表示各init程序……,大致说明系统启动过程,后面的章节将分别介绍之
Linux启动大致过程如下
我们知道,计算机只有在CPU加载到指令后才能根据指令完成工作,而其加载的指令存在于RAM(Random Access Memory,随机访问存储器),即我们当前用作内存的介质,而该设备断点后将无法保存数据,那么此时指令从何而来?
在Linux系统初识-计算机体系结构中有介绍过,我们需要外部存储设备来帮助持久保存数据。该设备即外存或辅储,一般使用HDD或SSD为介质
而这就需要在开机时将外存中的指令读取到内存,而后加载到CPU,而这个动作本身,也是需要指令来完成的!这该如何进行?
这就需要计算机有“自举”能力,现代计算机的设计中,在我们按下电源键后,主板将会把一段存储在特殊存储器上的代码传入CPU中,注意,该动作使用硬件逻辑完成的,不需要指令的参与,就像我们打开电灯开关,灯就会亮一样
这段代码我们将其称之为BIOS(Basic Input/Output System,基本输入输出系统),他主要负责探测硬件(POST(Power On Self Test,加电自检))、选择启动设备
当上述操作无误后,BIOS将选择的设备中的代码载入CPU,即Boot Loader,用于引导分区上的操作系统,在此处由于分区表类型不同稍有差异
- 对于完全支持UEFI引导:
-
UEFIBoot LoaderKernelINIT
- 对于BIOS引导:
-
BIOSBoot LoaderGrubKernelINIT
由于BIOS本身不能识别文件系统,故要使用其他机制辅助,事实上,上图对于BIOS的引导中,Boot Loader代码也属于Grub程序,而使用UEFI的引导中,Boot Loader即Grub,不同之处下文将详细介绍,为了方便叙述,本文的章节划分按照上图BIOS引导的架构
而后通过Grub实现从当前物理存储设备选择所启动的操作系统,以及内核所在位置与相关启动特性
上述操作完成后,根据Grub中指定的内核与相关参数启动Kernel,在Kernel中启动用户空间的第一个进程,即init程序,至此,系统启动完成
事实上init程序启动后,还会有一些相关配置,此处没有列出,下文将详细介绍
二、BIOS
该过程是计算机加电之后运行的第一段程序,如今,UEFI即将全面取代BIOS,通常,我们将该程序称为固件(Firmware),负责硬件检测,以及为操作系统提供运行时服务
1. BIOS
BIOS(Basic Input/Output System,基本输入输出系统)固件安装在PC的主板(Motherboard)上的独立存储器中,早期位于ROM(Read Only Memory,只读存储器)中,不可更改,后来位于闪存(Flash Memory)中(常为EEPROM),带来的好处是可以在不从主板上移除芯片的情况下重写它,这允许对BIOS固件进行简单的最终用户更新,从而可以添加新功能或修复错误
通常,我们也将存储BIOS的储存器称为BIOS芯片
主要功能
-
BIOS中断服务程序实质上是软件与硬件之间的一个可编程接口,主要用于程序软件功能与硬件之间连接。例如,系统对光驱、硬盘等管理,中断的设置等
-
BIOS系统设置程序:BIOS提供一个“系统设置程序”,主要来设置系统底层的各项参数,如系统的基本情况、CPU特性、软硬盘驱动器等部件的信息,该程序在开机时按某个键就可进入设置状态
-
POST:接通电源后,系统首先由POST(Power On Self Test,加电自检)程序来对内部各个设备进行检查。通常完整的POST自检将包括对CPU、640K基本内存、1M以上的扩展内存、ROM、等进行测试,一旦在自检中发现问题,系统将给出提示信息或鸣笛警告,其测试流程如下1
引导系统重置REST引导CPU。
CPU指向BIOS自我测试的地址FFFFOH并打开CPU运行第一个指令。
CPU内部寄存器的测试。
CMOS 146818 SRAM检查。
ROM BIOS检查码测试。
8254计时/计数器测试。
8237 DMA控制器测试。
74612页寄存器测试。
REFRESH刷新电路测试。
8042键盘控制器测试。
DRAM 64KB基本存储器测试。
CPU保护模式的测试。
8259中断控制器的测试。
CMOS 146818电力及检查码检查。
DRAM IMB以上存储器检查。
显卡测试。
NMI强制中断测试。
8254计时/计数器声音电路测试。
8254计时/计数器计时测试。
CPU保护模式SHUT DOWN测试。
CPU回至实模式(REAL MODE)。
键盘鼠标测试。
8042键盘控制器测试。
8259中断控制器IRQ0至IRQ18建立。
磁盘驱动器及界面测试。
设置并行打印机及串列RS232的界面。
检查CMOS IC时间、日期。
检查完成
- BIOS系统启动自举程序:系统完成POST自检后,BIOS就首先按照系统CMOS设置中保存的启动顺序搜索软硬盘驱动器及CD-ROM,网络服务器等有效地启动驱动器,读入操作系统引导记录,然后将系统控制权交给引导记录,并由引导记录来完成系统的顺序启动
CMOS与BIOS
很多人对二者傻傻分不清,这里说明一下
BIOS是一段程序,存位于EEPROM(Electrically-Erasable Programmable Read-Only Memory,电可擦除可编程只读存储器),是一种可以通过电子方式多次复写的半导体存储设备,可以用特定的电压,来抹除芯片上的信息,以便写入新的数据(注意,早期的BIOS并非如此,上文有介绍)
而BIOS设置的配置记录放在CMOS(Complementary Metal Oxide Semiconductor,互补金属氧化物半导体)芯片中,该芯片属于RAM,断电后数据将丢失
故主板上有一块电池,为该存储器供电,若取出电池,则可重置这些信息,如BIOS密码、启动次序、时间等
Boot Sequence
在BIOS提供的配置页面中,提供了让用户选择启动次序(Boot Sequence)的接口,如下图

上图为VMware Workstation 15的BIOS界面,实际界面样式因不同主板或BIOS程序而异,然意义相同
配置启动设备后,BIOS工作完成后将根据这里配置的顺序从对应设备中寻找启动代码,即查看该设备首512字节是否是以0x55 0xAA结尾,若不是,则认为该设备无启动能力,继续寻找下一个设备,否则加载该代码,控制权移交至该代码,BIOS工作完成
可参看Linux存储管理相关内容
2. UEFI
UEFI(Unified Extensible Firmware Interface,统一可扩展固件接口)是一种个人计算机系统规格,用来定义操作系统与系统固件之间的软件界面,作为BIOS的替代方案
概述
UEFI的前身是Intel在1998年开始开发的Intel Boot Initiative,后来被重命名为可扩展固件接口(Extensible Firmware Interface,缩写EFI)。Intel在2005年将其交由统一可扩展固件接口论坛(Unified EFI Forum)来推广与发展,为了凸显这一点,EFI也更名为UEFI(Unified EFI)。UEFI论坛的创始者是11家知名计算机公司,包括Intel、IBM等硬件厂商,软件厂商Microsoft,及BIOS厂商AMI(英语:American Megatrends)、Insyde及Phoenix
目前的最新版本为UEFI-2.7A2
UEFI在概念上非常类似于一个小型的操作系统,并且具有操控所有硬件资源的能力,而其一些特性与操作系统有着本质区别
-
它只是硬件和预启动软件间的接口规范
-
UEFI环境下不提供中断的机制,也就是说每个EFI驱动程序必须用轮询(polling)的方式来检查硬件状态,并且需要以解释的方式运行,较操作系统下的机械码驱动效率更低
-
UEFI系统不提供复杂的缓存器保护功能,它只具备简单的缓存器管理机制,具体来说就是指运行在x64或x86处理器的64位模式或保护模式下,以最大寻址能力为限把缓存器分为一个平坦的段(Segment),所有的程序都有权限访问任何一段位置,并不提供真实的保护服务

UEFI的组成
x64计算机平台的UEFI通常包含以下几个部分:3
- Pre-EFI初始化模块
- EFI驱动程序执行环境(DXE)
- EFI驱动程序
- 兼容性支持模块(CSM)
- EFI应用程序
- GUID磁盘分区表
在实现中,统一可扩展固件接口(UEFI)初始化模块和驱动执行环境通常被集成在一个只读存储器中(多为NVRAM)
Pre-EFI初始化程序在系统开机的时候最先得到执行,完成存储器的初始化工作,然后加载UEFI DXE(驱动程序执行环境)
当DXE被加载运行时,系统便具有了枚举并加载其他UEFI驱动程序的能力。在基于PCI Express架构的x64计算机系统中,系统会加载UEFI内置的驱动程序模块,完成UEFI固件、CPU、存储器、芯片组及主板的进一步初始化,然后初始化各PCIe控制器、PCIe适配器(如RAID扩展卡或显卡)及芯片组内置PCIe适配器(如芯片组内置的SATA、USB、网卡等功能)并加载这些PCIe设备的UEFI驱动程序(如果有的话,也有可能是加载PCIe设备的Legacy Option ROM)
UEFI驱动程序不仅可以包含在PCIe适配器的ROM中(作为PCIe设备的UEFI Option ROM),还可以以.EFI文件的形式被方便的加载
在UEFI规范中,一种突破传统MBR磁盘分区结构限制的GUID磁盘分区系统(GPT)被引入,新结构中,磁盘的主分区数不再受限制(在MBR结构下,只能存在4个主分区),另外UEFI+GPT磁盘分割表结合还可以支持2.1 TB以上硬盘,并且分区类型将由GUID来表示
GPT磁盘分区表的硬盘可包含EFI系统分区(ESP),EFI系统分区(ESP)可以被UEFI固件访问,可用于存放操作系统的引导程序、EFI应用程序(如OEM的备份程序和硬件诊断程序)等等
EFI系统分区采用FAT文件系统,在Windows操作系统下默认在“本机”中隐藏。UEFI固件通过运行EFI系统分区中的引导程序文件(扩展名为.EFI的UEFI应用程序)引导操作系统。CSM是在x86平台UEFI系统中的一个特殊的模块,它将为不具备UEFI引导能力的操作系统以及16位的传统Option ROM(即非EFI的Option ROM)提供类似于传统BIOS的系统服务
Secure Boot功能要求原生UEFI(即关闭CSM),因此在UEFI固件设置中打开CSM前,需要在UEFI固件设置中关闭Secure Boot
下图为

引导
UEFI启动
与BIOS不同,UEFI不依赖于引导扇区,而是将引导管理器定义为UEFI规范的一部分。当计算机启动时,启动管理器会检查启动配置并根据其设置加载到内存中,然后执行指定的OS加载程序或操作系统内核。引导配置由存储在NVRAM中的变量定义,包括指示OS加载器和OS内核的文件系统路径的变量
UEFI可以自动检测OS加载程序,从而可以从USB闪存驱动器等可移动设备轻松启动。这种自动检测依赖于到OS加载器的标准化文件路径,路径根据计算机体系结构而变化
从GPT分区磁盘引导UEFI系统通常称为UEFI-GPT引导。尽管UEFI规范要求完全支持MBR分区表[28],但某些UEFI固件实现会立即切换到基于BIOS的CSM引导,具体取决于引导磁盘分区表的类型,从而有效防止UEFI引导从MBR分区磁盘上的EFI系统分区。这样的引导方案通常被称为UEFI-MBR
引导管理器通常具有文本用户界面,因此用户可以从可用引导选项列表中选择所需的OS(或系统实用程序)
CSM启动
为了确保向后兼容性,PC级机器上的大多数UEFI固件实现还支持从MBR分区磁盘通过传统BIOS模式启动,通过提供传统BIOS兼容性的兼容性支持模块(CSM)。在这种情况下,通过忽略分区表并依赖引导扇区的内容,以与基于BIOS的传统系统相同的方式执行引导
从MBR分区磁盘启动BIOS样式通常称为BIOS-MBR,无论是在UEFI还是基于BIOS的传统系统上执行。此外,还可以从GPT磁盘启动传统的基于BIOS的系统,并且这种启动方案通常称为BIOS-GPT
在兼容性支持模块允许传统的操作系统和一些选项ROM仍然使用不支持UEFI。它还提供了所需的传统系统管理模式(SMM)功能,称为CompatibilitySmm,作为UEFI SMM提供的功能的补充。这是可选的,高度芯片组和平台特定。这种传统SMM功能的一个示例是通过模拟其经典的PS / 2对应物,为键盘和鼠标提供USB传统支持
该方案作为目前UEFI与BIOS的过度阶段的缓冲,英特尔宣布计划到2020年逐步停止对CSM的支持
UEFI与BIOS在启动过程上的区别
UEFI启动过程
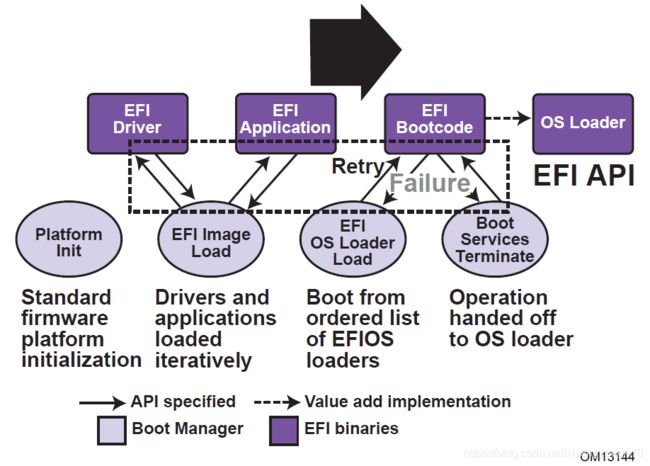
对应到UEFI个模块为,如下图。事实上,左半部分中,SEC,PEI,DXE称之为PI(Platform Initialization)规范,UEFI纯粹地是一个接口规范,它不会具体涉及平台固件是如何实现的。“如何实现”这一内容是PI要解决的问题
BDS,TSL,和RT一起,属于UEFI规范

- SEC阶段
- SEC阶段内存尚未被初始化,故UEFI将CPU缓存作为内存使用,即 Cache As RAM
- PEI阶段
- 和BIOS的初始化阶段类似,PEI阶段用以唤醒CPU及内存初始化。PEI用SEC设置好的Cache As RAM,执行一些PEIM(初始化模块),用于初始化一些硬件
- DXE阶段:
- DXE的主要功能在加载驱动。此阶段所有的内存、CPU、PCI、USB、SATA和Shell等都会被初始化
- BDS阶段:
- 在BDS(引导设备选择)阶段,它负责执行所有符合UEFI驱动模型(UEFI driver model)的驱动。这是一个发现并一个个连接的过程,一个个启动设备被发现,其设备路径(device path)也被连接起来。在万事俱备后,一个界面被显示出来(嵌入式系统上可以没有),供用户进行设置和选择启动设备,这就是大家熟悉的BIOS界面,用户可以自开机管理者程序页,选择要从哪个侦测到的开机设备来启动
- TSL阶段:
- 然后进入TSL(短暂系统载入)阶段,由操作系统接手开机。除此之外,也可以在BDS阶段选择UEFI Shell,让系统进入命令列,进行基本诊断和维护
BIOS启动过程
BIOS启动过程较为简单,一下做大致介绍
-
- 初始化
-
系统加电,CPU会自行重置为初始状态。BIOS boot block初始化阶段启动,此时内存尚未初始化,没有内容可以执行,所以厂商让CPU去寻找系统BIOS ROM中的reset vector(重置向量) :用一个固定的位置来启动所谓的BIOS boot program
-
一般来说程序会在内存的
FFFF0h处,也就是在UMA(上层记忆区域)靠结尾的地方。为避免ROM大小改变造成兼容问题,所以一般会选择放这里。它的内容只有一个jump指令,进一步跳到真正的BIOS启动程序 -
各家IBV (independent BIOS vender;独立BIOS供应商)可以放在不同的位置,只要通过jump来指定即可
-
在该阶段,系统的CPU、芯片组、Super I/O和USB只有部分初始化,仅获取足够信息来应付万一BIOS开机失败,可以利用其他储存设备来救援BIOS的boot block
-
- POST
-
然后BIOS开始施行POST,它通常被放在内存
C0000h处,作用是显卡的初始化,而大部分的显示卡都会在显示器上显示其相关讯息。这就是为何各位在开机的时候,首先会在显示器的画面左上角出现有关显示卡讯息的原因。 -
下一步BIOS会显示启动画面,并开始更深入的检测,如果这时候遇到任何错误,就会在画面上显示错误消息
-
- 记录系统的配置
-
此时BIOS会对系统进行进一步的确认,看看你的电脑究竟安装了那些系统资源或设备。有些电脑会逐步显示这些被侦测到的设备,例如BIOS支持随插即用,那它将会侦测和配置随插即用装置,并显示由BIOS侦测到的随插即用设备
-
在这些检测结束后,BIOS会打出一个总结表于画面上。而这个总结表在部分IBV的设定中是可以让使用者开启或关闭的。当然也有些IBV为加速开机把这一步直接隐藏省略
-
- 提供常驻程序
- 提供操作系统或应用程序调用的中断向量,如INT 10h(VGA图形及文字输出中断)等
-
- 加载系统
- 到这里是系统检测的部分,接下来BIOS便开始寻找引导设备,用户可以通过在BIOS的设定来决定搜寻顺序
总结
此处将UEFI与BIOS的引导方式总结如下
- BIOS
-
BIOS只认识设备,不认识分区、不认识文件
-
启动过程:根据CMOS中保存的顺序,查看存储设备,其前512字节是不是以0x55 0xAA结尾?若是则执行这段代码,完成
- UEFI
-
UEFI认识设备,还认识设备ROM,还认识分区表、认识文件系统以及文件
-
启动过程:经过一系列初始化后,按照设置里的顺序寻找启动项,一般有两种类型
- 文件启动项,大约记录的是某个磁盘的某个分区的某个路径下的某个文件。对于文件启动项,固件会直接加载这个EFI文件,并执行
- 设备启动项,大约记录的就是“某个U盘”、“某个硬盘”。(此处只讨论U盘、硬盘)对于设备启动项,UEFI标准规定了默认的路径“\EFI\Boot\bootX64.efi”。UEFI会加载磁盘上的这个文件。文件不存在则失败
-
UEFI-2以后,新增了SecureBoot功能。开了SecureBoot之后,主板会验证即将加载的efi文件的签名,如果开发者不是受信任的开发者,就会拒绝加载
三、Boot Loader
事实上在UEFI+GPT的引导方式下无需该步骤,从上文可看出,若使用该方式引导,由于UEFI可直接识别文件系统,在BDS阶段选择操作系统后即可进入下一步
本章主要介绍没有使用GPT分区表或GPT分区表不被识别的情况,如
- BISO+MBR
- UEFI+MBR
- BIOS+GPT
此处纠正一个问题,很多人认为BIOS+GPT无法引导,其实是可以的,上文已有介绍,GPT分区中LBA0位MBR兼容区。只是由于微软在默认情况下不允许Windows操作系统通过BIOS引导GPT分区而已
然而我们也可以经过配置是的Windows在BIOS+GPT方式下启动,chainloader指定ESP中的bootmgfw.efi即可
故对于BIOS与UEFI、BMR与GPT,其各种组合都是可以引导的,即
- BISO+MBR
- UEFI+MBR
- BIOS+GPT
- UEFI+GPT
若使用UEFI+MBR,则需要使用CSM,即打开兼容性支持模块,如此,UEFI将会读取MBR中的代码,这段过程与BIOS+MBR基本无异
当BIOS(或使用SCM的UEFI)选择到指定的启动设备后,由于它不能识别文件系统,故将读取选择设备的首部446字节,这是一段代码,即Boot Loader(引导加载器),由于代码较为简短,无法执行复杂功能,故其主要用于将执行流执行另一部分
前面已经提及,Boot Loader为Grub的一部分(第一部分),而上面指向的另一部分即Grub的第二部分
可参考Linux存储管理-MBR相关内容
四、GRUB
1. Boot Loader
严格来讲,该章节应该交Boot Loader,而由于上一章MBR中占用,且如今Grub为最著名的Boot Loader程序,此处将其命名为GRUB
这里对Boot Loader程序做简要说明,该程序用于接管BIOS/UEFI交过来的控制系统权,用于加载系统内核
对于Windows,该程序为ntloader,nt即New Technology,而Windows中更新的Boot Loader程序为Windows Boot Manager
对于Linux平台,有两种较为常见
-
LILO,即LInux,LOader,Linux加载器,不能引导1024柱面(Cylinder)以后分区上的内核,故不支持大硬盘,常用于嵌入式平台
-
GRUB,即GRand Unified Bootloader
- Grub 0.x:Grub Legacy
- Grub 2
2. Grub概述
事实上,我们所谓的Grub应该被称为GNU Grub(就像我们每次说的Linux,Stallman先生都会强调:应该是GNU Linux!)
Grub 2引入了一些更为有效的能力:
-
支持多种文件系统,如ext4、xfs、ntfs等
-
Grub 2可以访问已经安装的设备上的数据,可以直接从LAM和RAID中读取数据
-
Grub 2使用了模块机制,引入很多模块,通过动态加载模块来扩展功能,这样允许core镜像足够小。
-
支持自动解压
-
支持脚本语言,包括简单的语法,如条件判断,循环,变量和函数
-
国际化语音,包括支持非ASCII的字符集和类似gettext的消息分类,字体,图形控制台等
-
支持rescue模式,可用于系统无法引导的情况
-
Grub 2有更可靠的方法在磁盘上有多个文件系统时发现文件和目标内核,可以用命令发现系统设备编号或者是UUID
-
有一个灵活的命令接口。如果没有配置文件的存在,grub2会自动进入命令模式
传统Grub在运行时由三个阶段
- Stage 1:位于MBR,用于引导Stage 2
- Stage 1_5:位于MBR之后的扇区,为识别内核文件所在的文件系统提供文件系统识别扩展
- Stage 2:位于/boot分区,主要的引导工作在此完成
其中Stage 1_5非必要
3. Grub的安装位置
这里需要说明的文件为
-
Boot.img:Stage 1对应的文件,MBR分区格式的磁盘中,放在MBR里; GPT分区格式的磁盘中,放在Protective MBR中
-
Core.img:Stage 1_5对应的文件,32256字节大小。MBR分区格式的磁盘中,放在紧邻MBR的若干扇区中;GPT分区格式的磁盘中,则放在34号扇区开始的位置(第一个分区所处的位置),而对应的GPT分区表中的第一个分区的entry被置空
-
/boot/grub:步骤2对应的文件目录,放在系统分区或者单独的Boot分区中
- Grub程序各部分安装的位置如图
-
- MBR分区表:

- MBR分区表:
-
- GPT分区表

- GPT分区表
4. 启动Kernel前的准备
在Grub加载Kernel后,Kernel将启动init程序,以下为./linux.init/main.c部分代码:
static int __ref kernel_init(void *unused)
{
kernel_init_freeable();
/* need to finish all async __init code before freeing the memory */
async_synchronize_full();
free_initmem();
mark_rodata_ro();
system_state = SYSTEM_RUNNING;
numa_default_policy();
flush_delayed_fput();
if (ramdisk_execute_command) {
if (!run_init_process(ramdisk_execute_command))
return 0;
pr_err("Failed to execute %s\n", ramdisk_execute_command);
}
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
if (!run_init_process(execute_command))
return 0;
pr_err("Failed to execute %s. Attempting defaults...\n",
execute_command);
}
if (!run_init_process("/sbin/init") ||
!run_init_process("/etc/init") ||
!run_init_process("/bin/init") ||
!run_init_process("/bin/sh"))
return 0;
panic("No init found. Try passing init= option to kernel. "
"See Linux Documentation/init.txt for guidance.");
}
内核会从三出搜索该程序,若依然没有找到,则启动一个shell,这些程序位于/(根)下,故而此时Kernel需要有加载根文件系统的能力,而/的文件系统与/boot可以位于不同分区,加之Kernel中不可能将所有文件系统的驱动都包含,而此时需要如何访问/?
我们知道,Boot Loader程序有时需要借助Stage 1_5阶段来加载/boot所在分区的相应驱动
同样的,将相关文件系统的驱动做成一个特定文件,在Kernel访问/之前,先加载该文件即可
显然,该文件需要内核能直接访问,故其在/boot中,在CentOS 5中,该文件为ramdisk,对应文件名一般为initrd,而在CentOS 6之后,该文件为ramfs,对应文件名一般为initramfs
从名称上可以看出,CentOS 5中通过将RAM模拟为块设备,而Linux的缓存机制导致将可能再次在RAM中缓存该内容,造成不必要的浪费,而ramfs本身就是一个tmpfs的内存盘,拥有最小化的设计,绕过了缓存机制,也消除了多余的内存占用
因此,Kernel与initrd(或initramfs)必须存储在Boot Loader程序可以访问的位置,并且需要将initrd(或initramfs)加载后传递其地址给Kernel,如此,内核即可访问根文件系统
5 .Grub Legacy
功能
-
提供菜单,选择要启动时的内核或系统;
- 允许传递参数给内核
- 可以隐藏选择界面
-
提供交互式接口
e:编辑模式,用于编辑菜单c:命令模式,交互式接口
-
基于密码的保护
- 启用内核映像,定义在相应的
title下 - 传递参数,即进入编辑模式,定义在全局段中
- 启用内核映像,定义在相应的
配置文件
配置文件的读取主要在Stage 2完成,其配置文件为/etc/grub.conf,该文件指向/boot/grub/grub.conf,如下为RHEL 5中的一个实例,以之为例说明个字段意义
default=0 # 设定默认启动的title的编号,从0开始
timeout=5 # 等待用户选择的内核或OS超时时长,单位:秒
splashimage=(hd0,0)/grub/splash.xpm.gz
# 指定grub的背景图片,gimp工具可以编辑图片,要保存为.xpm格式,然后使用gzip压缩(.gz)
hiddenmenu # 隐藏菜单
password redhat # grub的密码(明文),菜单编辑密码
password --md5 $1$HKXJ51$B9Z8A.X//XA.AtzU1.KuG.
# grub加密密码,可以使用grub-md5-crypt命令来计算密码
title Red Hat Enterprise Linux Server (2.6.18-308.el5)
# 内核标题,或操作系统名称,字符串,可自由修改
root (hd0,0)
# 内核文件所在的设备;对grub而言,所有类型硬盘一律hd,格式为
(hd#,N);
# hd#, #表示第几个磁盘;从0开始编号
# N表示对应磁盘的分区;从0开始编号
kernel /vmlinuz-2.6.18-308.el5 ro root=/dev/vol0/root rhgb quiet
# 内核文件路径,及传递给内核的参数,参数即/proc/cmdline中的内容
# 参数: ro root=/path/to/DEVICE
# 将/path/to/DEVICE所代表的设备当做内核启动时的根,以只读方式挂载
# quiet:静默模式, 内核初始化的信息不再输出
initrd /initrd-2.6.18-308.el5.img
# 文件:通常为cpio归档,并使用gzip压缩,通常以.img作为扩展名
# ramdisk文件路径,即临时的根,是一个完整意义上的Linux
# 注意:以上两项显示根下的文件是由于文件位于/boot/目录,该目录是单独的分区,而此时没有文件系统,遂grub直接访问该分区
# 若/boot没有单独分区,则会正常显示
password --md5 $1$HKXJ51$B9Z8A.X//XA.AtzU1.KuG. # 将该字段放置于所有title上面,为全局密码,放在某一title中,为内核启动密码
title Install Red Hat Enterprise Linux 5
root (hd0,0)
kernel /vmlinuz-5 ks=http://172.16.0.1/workstation.cfg ksdevice=eth0 noipv6
initrd /initrd-5
password --md5 $1$FSUEU/$uhUUc8USBK5QAXc.BfW4m.
命令行
help:获取帮助列表
help KEYWORD:命令详细帮助
find:查找文件
find (hd#,N)/PATH/TO/SOMEFILE
设定根设备后可省略设备
root:设定根设备
root (hd#,N)
kernel:指定本次启动使用的kernel
kernel /PATH/TO/KERNEL_FILE
额外可添加内核支持使用的cmdline参数
init=/PATH/TO/INIT
selinux=0
root=/PATH/TO/ROOT
…
initrd:为选定的内核提供额外文件的ramdisk
initrd /PATH/TO/INITRAMFS_FILE
该文件版本需要与kernel版本完全匹配
boot:引导启动选定的内核
安装grub
可使用grub-install命令安装grub,使用方式为
grub-install --root-directory=DIR /dev/DISK
还可以在grub交互界面安装:
grub> root (hd#,#)
grub> setup (hd#)
- grub指定设备的方式
-
-
hd(#,#) -
hd#: 磁盘编号,用数字表示; 从0开始编号 -
#: 分区编号,用数字表示; 从0开始编号
-
手动在grub命令行接口启动系统
grub> root (hd#,#)
grub> kernel /vmlinuz-VERSION-RELEASE ro root=/dev/DEVICE
grub> initrd /initramfs-VERSION-RELEASE.img
grub> boot
6. Grub 2
Grub 2的软件包名即grub2,他与Grub Legacy的区别上文已有介绍
配置文件
-
/boot/grub2/grub.cfg:启动项配置,可由grub2-mkconfig生成 -
/etc/default/grub:grub2-mkconfig工具生成配置时的参考信息 -
/etc/grub.d/*:该目录下主要为一些脚本,分别配合对应grub.cfg上的各个部分
应用
- 查看当前默认启动项
-
grub2-editenv list - 设置默认启动项
-
方式一:
grub2-set-default -
方式二:修改
/etc/default/grub,修改GRUB_DEFAULT=#(#:该数字为grub菜单中各启动项的顺序),而后使用grub2-mkconfig -o /boot/grub2/grub.cfg生成配置文件 - 安装grub2
-
grub2-install [--root-directory=/PATH/TO/ROOT] [DEVICE] 若为UEFI,则DEVICE可省略 - 生成新的grub.cfg文件
-
grub2-mkconfig -o /boot/grub2/grub.cfg
五、Kernel
Grub工作完成后,Kernel接管控制权,在此其主要工作为:
- 设备探测
- 驱动初始化(可能会从initrd(在redhat6中叫做initramfs)文件中装载驱动模块)
- 以只读方式挂载根文件系统(稍后init会重新挂载文件系统)
- 装载第一个进程init(PID: 1)
grub中指定的initrd(或initramfs)在此处将会用到,另外,第一个进程在CentOS 7中称为systemd,下一章将介绍
在内核的实现中,我们介绍了当前操作系统内核实现的两种主流方式
- 微内核将通过各内核子系统实现管理工作,如Windows,Solaris
- 宏内核将各种功能集于一身,Linux内核就是这种设计方式
理论上讲,微内核的设计思想更为先进,而事实上要协调好各个子系统去实现复杂管理任务,这本身也是一个非常复杂的工作
Linux内核通过将个功能分为不同的模块,按需动态装卸载,这些模块在Kernel 2.6版本以后本称为Kernel Object,文件名后缀为.ko(之前为.o)
BTW,在Linux中共享库为Shared Object(.so) 共享对象,在Windows中为Dynamic Link Library(.dll) 动态链接库
Linux内核文件一般位于/boot/vmlinuz-VERSION-RELEASE,而其模块文件为/lib/modules/VERSION-RELEASE/,而上文介绍的ramdisk,在CentOS 5中位于/boot/initrd-VERSION-RALEASE.img,而在CentOS 6之后的版本为/boot/initramfs-VERSION-RELEASE.img:
[root@localhost ~]# ll /boot/vmlinuz-`uname -r` -h
-rwxr-xr-x. 1 root root 4.8M Mar 6 2015 /boot/vmlinuz-3.10.0-229.el7.x86_64
[root@localhost ~]# ll /lib/modules/`uname -r` -h
total 2.6M
lrwxrwxrwx. 1 root root 38 Dec 20 04:15 build -> /usr/src/kernels/3.10.0-229.el7.x86_64
drwxr-xr-x. 2 root root 6 Mar 6 2015 extra
drwxr-xr-x. 11 root root 4.0K Dec 20 04:15 kernel
-rw-r--r--. 1 root root 668K Dec 20 04:22 modules.alias
-rw-r--r--. 1 root root 644K Dec 20 04:22 modules.alias.bin
-rw-r--r--. 1 root root 1.3K Mar 6 2015 modules.block
-rw-r--r--. 1 root root 5.8K Mar 6 2015 modules.builtin
-rw-r--r--. 1 root root 7.5K Dec 20 04:22 modules.builtin.bin
-rw-r--r--. 1 root root 209K Dec 20 04:22 modules.dep
-rw-r--r--. 1 root root 304K Dec 20 04:22 modules.dep.bin
-rw-r--r--. 1 root root 339 Dec 20 04:22 modules.devname
-rw-r--r--. 1 root root 108 Mar 6 2015 modules.drm
-rw-r--r--. 1 root root 108 Mar 6 2015 modules.modesetting
-rw-r--r--. 1 root root 1.5K Mar 6 2015 modules.networking
-rw-r--r--. 1 root root 82K Mar 6 2015 modules.order
-rw-r--r--. 1 root root 165 Dec 20 04:22 modules.softdep
-rw-r--r--. 1 root root 285K Dec 20 04:22 modules.symbols
-rw-r--r--. 1 root root 356K Dec 20 04:22 modules.symbols.bin
lrwxrwxrwx. 1 root root 5 Dec 20 04:15 source -> build
drwxr-xr-x. 2 root root 6 Mar 6 2015 updates
drwxr-xr-x. 2 root root 91 Dec 20 04:15 vdso
drwxr-xr-x. 2 root root 6 Mar 6 2015 weak-updates
[root@localhost ~]# ll /boot/initramfs-`uname -r`.img -h
-rw-------. 1 root root 20M Jan 18 13:06 /boot/initramfs-3.10.0-229.el7.x86_64.img
在RHEL系列发行版中,/lib/modules/VERSION-RELEASE/中有对应内核所需的各种外围模块,依赖关系由内核(依赖关系文件modules.dep)处理
kernel目录中的内容为内核主要模块:
| 目录 | 说明 |
|---|---|
arch |
平台相关,驱动CPU |
crypto |
加密解密 |
drivers |
驱动 |
fs |
文件系统 |
kernel |
内核自身的额外功能 |
lib |
库 |
mm |
Memory Management,内存管理 |
net |
网络(不是驱动,而是网络协议栈的实现) |
sound |
声卡 |
另外,ramdis由于需要提供文件系统支持,而用户的情况有各不相同,故该文件在安装操作系统时生成,我们亦可自行使用工具生成之:
- CentOS 5:
mkinitrd - CentOS 6+:
mkinitrd、dracut
启动相关内核参数
在Linux中,给kernel传递参数以控制其行为总共有三种方法:
-
build kernel之时的各个configuration选项
-
当kernel启动之时,可以参数在kernel被GRUB或LILO等启动程序调用之时传递给kernel
-
在kernel运行时,修改/proc或/sys目录下的文件
此处主要说明第二种方式——在Grub中为其传递参数
在./Documentation/kernel-parameters.txt中的内核参数详细说明,介绍了各参数及意义
kernel启动参数以空格分隔,严格区分大小写,对于module特有的kernel参数写法为,[module name].[parameter=XX]
启动参数通常是这样的形式: name[=value_1][,value_2]...[,value_10]
name是关键字,内核用它来识别应该把"关键字"后面的值传递给谁,也就是如何处理这个值,是传递给处理进程还是作为环境变量或者抛给"init"。值的个数限制为10,你可以通过再次使用该关键字使用超过10个的参数
下面列出了常用到的一些kernel启动参数
-
- 根磁盘相关启动参数:
-
root:指出启动的根文件系统 如:root=/dev/sda1 -
ro:指定根设备在启动过程中为read-only,默认情况下一般都是这样配的 -
rw和ro类似,它是规定为read-write,可写 -
rootfstype:根文件系统类型,如:rootfstype=ext4
-
- Console和kernel log相关启动参数:
-
console:console的设备和选项,如:console=tty0 console=ttyS0 -
debug:enable kernel debugging,启动中的所有debug信息都会打印到console上 -
quiet:disable all log messages,将kernel log level设置为KERN_WARNING,在启动中只非常严重的信息 -
loglevel:设置默认的console日志级别,如:loglevel=7(下文将介绍内核日志级别) -
time:设置在每条kernel log信息前加一个时间戳
-
- 内存相关的启动参数:
-
mem:指定kernel使用的内存量,mem=n[KMG] -
hugepages:设置大页表页(4MB大小)的最多个数,hugepages=n
-
- CPU相关的启动参数:
-
mce:Enable the machine check exception feature. -
nosmp:Run as a single-processor machine. 不使用SMP(多处理器) -
max_cpus:max_cpus=n, SMP系统最多能使用的CPU个数(即使系统中有大于n个的CPU)
-
- Ramdisk相关的启动参数:
-
initrd:指定初始化ramdisk的位置,initrd=filename -
noinitrd:不使用initrd的配置,即使配置了initrd参数
-
- 初始化相关启动参数:
-
init:在启动时去执行的程序,init=filename,默认值为/sbin/init
-
- PCI相关的启动参数:
-
pci:pci相关的选项,如pci=assign_buses,pci=nomsi
-
- SELinux相关启动参数:
-
enforcing:SELinux enforcing状态的开关,enforcing=0表示仅仅是记录危险而不是阻止访问,enforcing=1完全enable,默认值是0 -
selinux:在启动时关闭或开启SELinux,selinux=0表示关闭,selinux=1表示开启selinux
内核日志级别
日志的级别用于表示日志记录的详细程度,Linux Kernel一共有8个日志级别,在./include/linux/kern_levels.h中定义:
#ifndef __KERN_LEVELS_H__
#define __KERN_LEVELS_H__
#define KERN_SOH "\001" /* ASCII Start Of Header */
#define KERN_SOH_ASCII '\001'
#define KERN_EMERG KERN_SOH "0" /* system is unusable */
#define KERN_ALERT KERN_SOH "1" /* action must be taken immediately */
#define KERN_CRIT KERN_SOH "2" /* critical conditions */
#define KERN_ERR KERN_SOH "3" /* error conditions */
#define KERN_WARNING KERN_SOH "4" /* warning conditions */
#define KERN_NOTICE KERN_SOH "5" /* normal but significant condition */
#define KERN_INFO KERN_SOH "6" /* informational */
#define KERN_DEBUG KERN_SOH "7" /* debug-level messages */
#define KERN_DEFAULT KERN_SOH "d" /* the default kernel loglevel */
/*
* Annotation for a "continued" line of log printout (only done after a
* line that had no enclosing \n). Only to be used by core/arch code
* during early bootup (a continued line is not SMP-safe otherwise).
*/
#define KERN_CONT ""
#endif
六、init
内核初始化的最后一步就是启动 pid 为 1 的 init 进程。这个进程是系统的第一个进程。它负责产生其他所有用户进程
init 以守护进程方式存在,是所有其他进程的父进程
Init 系统能够定义、管理和控制 init 进程的行为。它负责组织和运行许多独立的或相关的始化工作(因此被称为 init 系统),从而让计算机系统进入某种用户预订的运行模式
仅仅将内核运行起来是毫无实际用途的,必须由 init 系统将系统代入可操作状态。比如启动外壳 shell 后,便有了人机交互,这样就可以让计算机执行一些预订程序完成有实际意义的任务。或者启动 X 图形系统以便提供更佳的人机界面,更加高效的完成任务。这里,字符界面的 shell 或者 X 系统都是一种预设的运行模式
大多数 Linux 发行版的 init 系统是和 System V 相兼容的,被称为 sysvinit。这是人们最熟悉的 init 系统。一些发行版如 Slackware 采用的是 BSD 风格 Init 系统,这种风格使用较少,本文不再涉及。其他的发行版如 Gentoo 是自己定制的。Ubuntu 和 RHEL 采用 upstart 替代了传统的 sysvinit
,启动系统的第一个进程,在RHEL系列的各个发行版中,该程序亦各不相同
-
- CentOS5
- SysV init,进程串行启动
-
配置文件:
/etc/inittab
-
- CentOS6
- Upstart,采用D-Bus、事件驱动模型等新机制 4
-
配置文件:
/etc/inittab,/etc/init/*.conf
-
- CentOS7
-
Systemd
-
配置文件:
/usr/lob/systemd/system,/etc/systemd/system -
完全兼容SysV脚本机制,service命令依然可用,建议使用
systemctl命令来控制服务5
在 Linux 主要应用于服务器和 PC 机的时代,SysVinit 运行非常良好,概念简单清晰。它主要依赖于 Shell 脚本,这就决定了它的最大弱点:启动太慢。在很少重新启动的 Server 上,这个缺点并不重要。而当 Linux 被应用到移动终端设备的时候,启动慢就成了一个大问题。为了更快地启动,人们开始改进 sysvinit,先后出现了 upstart 和 systemd 这两个主要的新一代 init 系统
1. SysV init
SysVinit 就是 System V 风格的 init 系统,顾名思义,它源于 System V 系列 UNIX。它提供了比 BSD 风格 init 系统更高的灵活性。是已经风行了几十年的 UNIX init 系统6
运行级别
Sysvinit 用术语RunLevel来定义"预订的运行模式"。Sysvinit 检查 /etc/inittab文件中是否含有initdefault项。 这告诉 init 系统是否有一个默认运行模式。如果没有默认的运行模式,那么用户将进入系统控制台,手动决定进入何种运行模式
sysvinit 中运行模式描述了系统各种预订的运行模式,每种 Linux 发行版对运行模式的定义都各不相同。但 0,1,6 却得到了大家的一致赞同:
0:关机
1:单用户模式
6:重启
通常在/etc/inittab文件中定义了各种运行模式的工作范围。比如 RedHat 定义了runlevel3和5
运行模式3将系统初始化为字符界面的 shell 模式;运行模式 5 将系统初始化为 GUI 模式。无论是命令行界面还是 GUI,运行模式3和5相对于其他运行模式而言都是完整的正式的运行状态,计算机可以完成用户需要的任务。而模式1,S等往往用于系统故障之后的排错和恢复
很显然,这些不同的运行模式下系统需要初始化运行的进程和需要进行的初始化准备都是不同的。比如运行模式 3 不需要启动 X 系统。用户只需要指定需要进入哪种模式,sysvinit 将负责执行所有该模式所必须的初始化工作
RHEL系列发行版的运行级别如下
| RunLevel | 说明 |
|---|---|
0 |
halt,关机 |
1 |
single user mode,无需认证,直接以管理员身份切入,维护模式;1级别的其他表示方式:s,S,single |
2 |
multi user mode, no NFS,会启动网络功能,但不会启动NFS,维护模式 |
3 |
multi user mode, text mode |
4 |
reserved(保留级别),目前同3级别 |
5 |
multi user mode, graphic mode |
6 |
reboot,重启 |
SysV init运行流程
Sysvinit 巧妙地用脚本,文件命名规则和软链接来实现不同的runlevel,sysvinit需要读取/etc/inittab文件,该文件将完成:
-
设定默认运行级别
-
运行系统初始化脚本:
/etc/rc.sysinit -
运行指定运行级别对应的目录下的脚本(S的start,K的stop)
-
设定Ctrl+Alt+Del组合键的操作
-
定义UPS电源在电源故障/恢复时执行的操作
-
启动虚拟终端(2345级别)
-
启动图形终端(5级别)
/etc/inittab
/etc/inittab文件每行定义一种action以及与之对应的process,格式为
id:rublevels:action:process
id:操作的ID
runlevels:在哪些级别下执行此操作
#,###,也可以为空,表示所有级别
action:动作
initdefault: 设置默认运行级别,无需定义操作
sysinit: 指定系统初始化脚本
例:在CentOS 5中 si::sysinit:/etc/rc.d/rc.sysinit
wait: 等待系统切换至此级别时运行一次
如:l0:0:wait:etc/rc.d/rc 0
意味着启动或关闭/etc/rc.d/rc3.d/下的服务脚本所控制的服务
K*:要停止的服务;K##*,优先级,数字越小,越优先关闭,依赖的服务应先关闭
S*:要启动的服务;S##*:优先级,数字越小,越优先启动,被依赖的服务应先启动
ctrlaltdel:定义Ctrl,Alt,Delete键时的操作
respawn:当指定的操作进程被关闭时立即再执行一次,如
tty1:2345:respawn:/sbin/mingetty tty1
mingetty会调用login程序
打开虚拟终端的程序:mingetty、getty等
process:操作
sysvinit顺序地执行以下这些步骤,从而将系统初始化为预定的runlevel
-
/etc/rc.d/rc.sysinit -
/etc/rc.d/rc和/etc/rc.d/rcX.d/(X 代表运行级别 0-6) -
/etc/rc.d/rc.local -
X11(若需要的话)
/etc/rc.d/rc.sysinit
/etc/rc.d/rc.sysinit的工作为
-
设定主机名
-
设置欢迎信息
-
激活selinux和udev
-
挂载文件系统
-
激活swap
-
监测根文件系统,并以读写方式重新挂载根文件系统
-
根据/etc/sysctl.conf文件设置内核参数
-
激活LVM及软RAID设备
-
系统时钟
-
键盘映射
-
加载额外的驱动程序
-
清除过期的 locks 和 PID 文件
完成了以上这些工作之后,sysvinit 开始运行/etc/rc.d/rc脚本。该脚本接受一个RunLevel作为其参数,根据不同的 RunLevel,rc 脚本将打开对应该RunLevel的rcX.d目录(X为runlevel),找到并运行存放在该目录下的所有启动脚本。每个RunLevel都有一个这样的目录,目录名为/etc/rc.d/rcX.d
在这些目录下存放着很多不同的脚本。文件名以S开头的脚本就是启动时应该运行的脚本,S后面跟的数字定义了这些脚本的执行顺序。在/etc/rc.d/rcX.d目录下的脚本其实都是一些软链接文件,真实的脚本文件存放在/etc/init.d目录下
/etc/rc.d/rc脚本中关于服务的启动与停止大致方式为
for srv in /etc/rc.d/rc$runlevel.d/K*; do
$srv stop
done
###
for srv in /etc/rc.d/rc$runlevel.d/S*; do
$srv start
done
/etc/rc.d/rc.local
当所有的初始化脚本执行完毕。Sysvinit 运行/etc/rc.d/rc.local脚本。
rc.local是 Linux 留给用户进行个性化设置的地方。您可以把自己私人想设置和启动的东西放到这里,一台 Linux Server 的用户一般不止一个,故而会有这样的考虑
Sysvinit 和系统关闭
Sysvinit 不仅需要负责初始化系统,还需要负责关闭系统。在系统关闭时,为了保证数据的一致性,需要小心地按顺序进行结束和清理工作
比如应该先停止对文件系统有读写操作的服务,然后再 umount 文件系统。否则数据就会丢失。
这种顺序的控制这也是依靠/etc/rc.d/rcX.d/目录下所有脚本的命名规则来控制的,在该目录下所有以 K 开头的脚本都将在关闭系统时调用,字母 K 之后的数字定义了它们的执行顺序
这些脚本负责安全地停止服务或者其他的关闭工作
2. Upstart init
Upstart 简介
大约在 2006 年或者更早的时候, Ubuntu 开发人员试图将 Linux 安装在笔记本电脑上。在这期间技术人员发现经典的 sysvinit 存在一些问题:它不适合笔记本环境。这促使程序员 Scott James Remnant 着手开发 upstart7
当 Linux 内核进入 2.6 时代时,内核功能有了很多新的更新。新特性使得 Linux 不仅是一款优秀的服务器操作系统,也可以被用于桌面系统,甚至嵌入式设备
桌面系统或便携式设备的一个特点是经常重启,而且要频繁地使用硬件热插拔技术。在现代计算机系统中,硬件繁多、接口有限,人们并非将所有设备都始终连接在计算机上,比如 U 盘平时并不连接电脑,使用时才插入 USB 插口。因此,当系统上电启动时,一些外设可能并没有连接。而是在启动后当需要的时候才连接这些设备
在 2.6 内核支持下,一旦新外设连接到系统,内核便可以自动实时地发现它们,并初始化这些设备,进而使用它们。这为便携式设备用户提供了很大的灵活性
可是这些特性为 sysvinit 带来了一些挑战。当系统初始化时,需要被初始化的设备并没有连接到系统上;比如打印机。为了管理打印任务,系统需要启动 CUPS 等服务,而如果打印机没有接入系统的情况下,启动这些服务就是一种浪费。Sysvinit 没有办法处理这类需求,它必须一次性把所有可能用到的服务都启动起来,即使打印机并没有连接到系统,CUPS 服务也必须启动
还有网络共享盘的挂载问题。在/etc/fstab中,可以指定系统自动挂载一个网络盘,比如 NFS,或者 iSCSI 设备。在上文sysvinit 的简介中可以看到,sysvinit 分析/etc/fstab挂载文件系统这个步骤是在网络启动之前。可是如果网络没有启动,NFS 或者 iSCSI 都不可访问,当然也无法进行挂载操作
Sysvinit 采用 netdev 的方式来解决这个问题,即/etc/fstab发现 netdev 属性挂载点的时候,不尝试挂载它,在网络初始化并使能之后,还有一个专门的 netfs 服务来挂载所有这些网络盘。这是一个不得已的补救方法,给管理员带来不便。部分新手管理员甚至从来也没有听说过 netdev 选项,因此经常成为系统管理的一个陷阱
针对以上种种情况,Ubuntu 开发人员在评估了当时的几个可选 init 系统之后,决定重新设计和开发一个全新的 init 系统,即 UpStart。UpStart 基于事件机制,比如 U 盘插入 USB 接口后,udev 得到内核通知,发现该设备,这就是一个新的事件。UpStart 在感知到该事件之后触发相应的等待任务,比如处理/etc/fstab 中存在的挂载点。采用这种事件驱动的模式,upstart 完美地解决了即插即用设备带来的新问题
此外,采用事件驱动机制也带来了一些其它有益的变化,比如加快了系统启动时间。sysvinit 运行时是同步阻塞的。一个脚本运行的时候,后续脚本必须等待
这意味着所有的初始化步骤都是串行执行的,而实际上很多服务彼此并不相关,完全可以并行启动,从而减小系统的启动时间。在 Linux 大量应用于服务器的时代,系统启动时间也许还不那么重要;然而对于桌面系统和便携式设备,启动时间的长短对用户体验影响很大。此外云计算等新的 Server 端技术也往往需要单个设备可以更加快速地启动
UpStart 满足了这些需求,目前不仅桌面系统 Ubuntu 采用了 UpStart,甚至企业级服务器级的 RHEL 也默认采用 UpStart 来替换 sysvinit 作为 init 系统
Upstart启动过程
内核初始化的最后,内核将启动 pid 为 1 的 init 进程,即 UpStart 进程
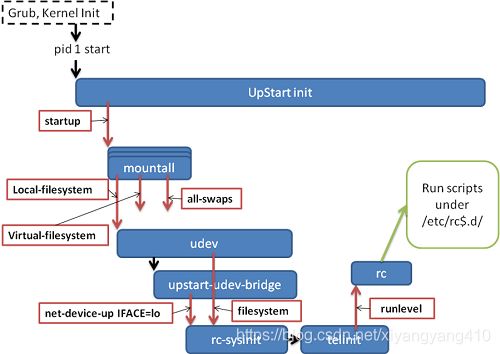
系统上电后运行 GRUB 载入内核。内核执行硬件初始化和内核自身初始化。在内核初始化的最后,内核将启动 pid 为 1 的 init 进程,即 UpStart 进程
Upstart 进程在执行了一些自身的初始化工作后,立即发出"startup"事件。上图中用红色方框加红色箭头表示事件,可以在左上方看到"startup"事件
所有依赖于"startup"事件的工作被触发,其中最重要的是 mountall。mountall 任务负责挂载系统中需要使用的文件系统,完成相应工作后,mountall 任务会发出以下事件:local-filesystem,virtual-filesystem,all-swaps
其中 virtual-filesystem 事件触发 udev 任务开始工作。任务 udev 触发 upstart-udev-bridge 的工作。Upstart-udev-bridge 会发出 net-device-up IFACE=lo 事件,表示本地回环 IP 网络已经准备就绪。同时,任务 mountall 继续执行,最终会发出 filesystem 事件
此时,任务 rc-sysinit 会被触发,因为 rc-sysinit 的 start on 条件为:
start on filesystem and net-device-up IFACE=lo
任务 rc-sysinit 调用 telinit。Telinit 任务会发出 runlevel 事件,触发执行/etc/init/rc.conf。
rc.conf 执行/etc/rc$.d/目录下的所有脚本,和 SysVInit 非常类似
配置文件
Upstart配置文件为/etc/inittab,/etc/init/*.conf,而在Upstart中,/etc/inittab仅用于定义默认运行级别,同时也将一些其他配置作为专门的文件保存,如Ctrl-Alt-Delete按键的定义位于/etc/init/control-alt-delete.conf,此在/etc/inittab中已有说明
# inittab is only used by upstart for the default runlevel.
#
# ADDING OTHER CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# System initialization is started by /etc/init/rcS.conf
#
# Individual runlevels are started by /etc/init/rc.conf
#
# Ctrl-Alt-Delete is handled by /etc/init/control-alt-delete.conf
#
# Terminal gettys are handled by /etc/init/tty.conf and /etc/init/serial.conf,
# with configuration in /etc/sysconfig/init.
#
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
#
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
id:3:initdefault:
/etc/init/*.conf
任何一个工作都是由一个工作配置文件(Job Configuration File)定义的。这个文件是一个文本文件,包含一个或者多个小节(stanza)。每个小节是一个完整的定义模块,定义了工作的一个方面,比如 author 小节定义了工作的作者。工作配置文件存放在/etc/init 下面,是以.conf 作为文件后缀的文件
一个真正的工作配置文件会包含很多小节,其中比较重要的小节有以下几个
-
- “expect” Stanza
-
Upstart 除了负责系统的启动过程之外,和 SysVinit 一样,Upstart 还提供一系列的管理工具。当系统启动之后,管理员可能还需要进行维护和调整,比如启动或者停止某项系统服务。或者将系统切换到其它的工作状态,比如改变运行级别
-
为了启动,停止,重启和查询某个系统服务。Upstart 需要跟踪该服务所对应的进程。比如 httpd 服务的进程 PID 为 1000。当用户需要查询 httpd 服务是否正常运行时,Upstart 就可以利用 ps 命令查询进程 1000,假如它还在正常运行,则表明服务正常。当用户需要停止 httpd 服务时,Upstart 就使用 kill 命令终止该进程。为此,Upstart 必须跟踪服务进程的进程号
-
部分服务进程为了将自己变成后台精灵进程(daemon),会采用两次派生(fork)的技术,另外一些服务则不会这样做。假如一个服务派生了两次,那么 UpStart 必须采用第二个派生出来的进程号作为服务的 PID。但是,UpStart 本身无法判断服务进程是否会派生两次,为此在定义该服务的工作配置文件中必须写明 expect 小节,告诉 UpStart 进程是否会派生两次
-
Expect 有两种,"expect fork"表示进程只会 fork 一次;"expect daemonize"表示进程会 fork 两次
-
- “exec” Stanza 和"script" Stanza
-
一个 UpStart 工作一定需要做些什么,可能是运行一条 shell 命令,或者运行一段脚本。用"exec"关键字配置工作需要运行的命令;用"script"关键字定义需要运行的脚本
-
以下显示了 exec 和 script 的用法
# mountall.conf description “Mount filesystems on boot” start on startup stop on starting rcS ... script . /etc/default/rcS [ -f /forcefsck ] && force_fsck=”--force-fsck” [ “$FSCKFIX”=”yes” ] && fsck_fix=”--fsck-fix” ... exec mountall –daemon $force_fsck $fsck_fix end script ... -
这是 mountall 的例子,该工作在系统启动时运行,负责挂载所有的文件系统。该工作需要执行复杂的脚本,由"script"关键字定义;在脚本中,使用了 exec 来执行 mountall 命令
-
- “start on” Stanza 和"stop on" Stanza
-
"start on"定义了触发工作的所有事件。"start on"的语法很简单,如下所示:
-
start on EVENT [[KEY=]VALUE]... [and|or...] -
EVENT 表示事件的名字,可以在 start on 中指定多个事件,表示该工作的开始需要依赖多个事件发生。多个事件之间可以用 and 或者 or 组合,"表示全部都必须发生"或者"其中之一发生即可"等不同的依赖条件。除了事件发生之外,工作的启动还可以依赖特定的条件,因此在 start on 的 EVENT 之后,可以用 KEY=VALUE 来表示额外的条件,一般是某个环境变量(KEY)和特定值(VALUE)进行比较。如果只有一个变量,或者变量的顺序已知,则 KEY 可以省略。
-
"stop on"和"start on"非常类似,只不过是定义工作在什么情况下需要停止
-
以下是"start on"和"stop on"的一个例子
#dbus.conf description “D-Bus system message bus” start on local-filesystems stop on deconfiguring-networking … -
D-Bus 是一个系统消息服务,上面的配置文件表明当系统发出 local-filesystems 事件时启动 D-Bus;当系统发出 deconfiguring-networking 事件时,停止 D-Bus 服务
3. Systemd
Systemd特点
更快启动
对于系统启动而言,System与以上二者最大的区别如下图8

假设有6个不同的启动项目, 比如 Job1、Job2 等等。在 SysVInit 中,每一个启动项目都由一个独立的脚本负责,它们由 sysVinit 顺序地,串行地调用。因此总的启动时间为 T 1 + T 2 + T 3 + T 4 + T 5 + T 6 + T 7 T1+T2+T3+T4+T5+T6+T7 T1+T2+T3+T4+T5+T6+T7。其中一些任务有依赖关系,比如 1,2,3,4
而 Job 5 和 F 却和 1,2,3,4 无关。这种情况下,UpStart 能够并发地运行任务{5,6,(1,2,3,4)},使得总的启动时间减少为 T 1 + T 2 + T 3 T1+T2+T3 T1+T2+T3
这无疑增加了系统启动的并行性,从而提高了系统启动速度。但是在 UpStart 中,有依赖关系的服务还是必须先后启动。比如任务 1,2,(3,4)因为存在依赖关系,所以在这个局部,还是串行执行
Systemd 能够更进一步提高并发性,即便对于那些 UpStart 认为存在相互依赖而必须串行的服务,也可以并发启动
按需启动服务
当 sysvinit 系统初始化的时候,它会将所有可能用到的后台服务进程全部启动运行。并且系统必须等待所有的服务都启动就绪之后,才允许用户登录。这种做法有两个缺点:首先是启动时间过长;其次是系统资源浪费
某些服务很可能在很长一段时间内,甚至整个服务器运行期间都没有被使用过。比如 CUPS,打印服务在多数服务器上很少被真正使用到。您可能没有想到,在很多服务器上 SSHD 也是很少被真正访问到的。花费在启动这些服务上的时间是不必要的;同样,花费在这些服务上的系统资源也是一种浪费
Systemd 可以提供按需启动的能力,只有在某个服务被真正请求的时候才启动它。当该服务结束,systemd 可以关闭它,等待下次需要时再次启动它
启动挂载点和自动挂载的管理
传统的 Linux 系统中,用户可以用/etc/fstab 文件来维护固定的文件系统挂载点。这些挂载点在系统启动过程中被自动挂载,一旦启动过程结束,这些挂载点就会确保存在。这些挂载点都是对系统运行至关重要的文件系统,比如 HOME 目录。和 sysvinit 一样,Systemd 管理这些挂载点,以便能够在系统启动时自动挂载它们。Systemd 还兼容/etc/fstab 文件,您可以继续使用该文件管理挂载点
有时候用户还需要动态挂载点,比如打算访问 DVD 内容时,才临时执行挂载以便访问其中的内容,而不访问光盘时该挂载点被取消(umount),以便节约资源。传统地,人们依赖 autofs 服务来实现这种功能
Systemd 内建了自动挂载服务,无需另外安装 autofs 服务,可以直接使用 systemd 提供的自动挂载管理能力来实现 autofs 的功能
实现事务性依赖关系管理
系统启动过程是由很多的独立工作共同组成的,这些工作之间可能存在依赖关系,比如挂载一个 NFS 文件系统必须依赖网络能够正常工作。Systemd 虽然能够最大限度地并发执行很多有依赖关系的工作,但是类似"挂载 NFS"和"启动网络"这样的工作还是存在天生的先后依赖关系,无法并发执行。对于这些任务,systemd 维护一个"事务一致性"的概念,保证所有相关的服务都可以正常启动而不会出现互相依赖,以至于死锁的情况
日志服务
systemd 自带日志服务 journald,该日志服务的设计初衷是克服现有的 syslog 服务的缺点。比如:
-
syslog 不安全,消息的内容无法验证。每一个本地进程都可以声称自己是 Apache PID 4711,而 syslog 也就相信并保存到磁盘上
-
数据没有严格的格式,非常随意。自动化的日志分析器需要分析人类语言字符串来识别消息。一方面此类分析困难低效;此外日志格式的变化会导致分析代码需要更新甚至重写
Systemd Journal 用二进制格式保存所有日志信息,用户使用 journalctl 命令来查看日志信息。无需自己编写复杂脆弱的字符串分析处理程序
Systemd Journal 的优点如下
-
简单性:代码少,依赖少,抽象开销最小
-
零维护:日志是除错和监控系统的核心功能,因此它自己不能再产生问题。举例说,自动管理磁盘空间,避免由于日志的不断产生而将磁盘空间耗尽
-
移植性:日志 文件应该在所有类型的 Linux 系统上可用,无论它使用的何种 CPU 或者字节序
-
性能:添加和浏览 日志 非常快
-
最小资源占用:日志 数据文件需要较小
-
统一化:各种不同的日志存储技术应该统一起来,将所有的可记录事件保存在同一个数据存储中。所以日志内容的全局上下文都会被保存并且可供日后查询。例如一条固件记录后通常会跟随一条内核记录,最终还会有一条用户态记录。重要的是当保存到硬盘上时这三者之间的关系不会丢失。Syslog 将不同的信息保存到不同的文件中,分析的时候很难确定哪些条目是相关的
-
扩展性:日志的适用范围很广,从嵌入式设备到超级计算机集群都可以满足需求
-
安全性:日志 文件是可以验证的,让无法检测的修改不再可能
Unit
系统初始化需要做的事情非常多。需要启动后台服务,比如启动 SSHD 服务;需要做配置工作,比如挂载文件系统。这个过程中的每一步都被systemd抽象为一个配置单元,即Unit。可以认为一个服务是一个配置单元;一个挂载点是一个配置单元;一个交换分区的配置是一个配置单元;等等
unit由其相关的配置文件进行标识和识别和配置,文件中主要包含了系统服务、监听的socket、保存的快照以及其他与init相关的信息,这些配置文件主要保存在
-
-
/usr/lib/systemd/system/ - 存放已经安装的RPM包的systemd单位文件
-
-
-
/run/systemd/system/ - 运行时已经创建的systemd单位,该目录优先级高于上一个目录
-
-
-
/etc/systemd/system/ - 已经创建的和由系统管理的systemd单元,该目录优先级高于上一个目录
-
systemd 将配置单元归纳为以下一些不同的类型
| Unit | 说明 |
|---|---|
| Service unit | .service,系统服务,代表一个后台服务进程 |
| Target unit | .target,systemd单元组,此类配置单元为其他配置单元进行逻辑分组。它们本身实际上并不做什么,只是引用其他配置单元而已。这样便可以对配置单元做一个统一的控制。这样就可以实现大家都已经非常熟悉的运行级别概念。比如想让系统进入图形化模式,需要运行许多服务和配置命令,这些操作都由一个个的配置单元表示,将所有这些配置单元组合为一个目标(target),就表示需要将这些配置单元全部执行一遍以便进入目标所代表的系统运行状态 |
| Automount unit | .automount,文件系统自动挂载点,此类配置单元封装系统结构层次中的一个自挂载点。每一个自挂载配置单元对应一个挂载配置单元 ,当该自动挂载点被访问时,systemd 执行挂载点中定义的挂载行为 |
| Device unit | .device,被内核识别的设备文件,此类配置单元封装一个存在于 Linux 设备树中的设备。每一个使用 udev 规则标记的设备都将会在 systemd 中作为一个设备配置单元出现 |
| Mount unit | .mount,文件系统挂载点,此类配置单元封装文件系统结构层次中的一个挂载点。Systemd 将对这个挂载点进行监控和管理。比如可以在启动时自动将其挂载;可以在某些条件下自动卸载。Systemd 会将/etc/fstab中的条目都转换为挂载点,并在开机时处理 |
| Path unit | .path,文件系统中的文件或目录 |
| Scope unit | .scope,外部创建的进程 |
| Slice unit | .slice,管理系统进程的一组分层组织单位 |
| Snapshot unit | .snapshot,一个被保存的systemd管理状态,与 target 配置单元相似,快照是一组配置单元 |
| Socket unit | .socket,进程间通信的套接字,此类配置单元封装系统和互联网中的一个 套接字 。当下,systemd 支持流式、数据报和连续包的 AF_INET、AF_INET6、AF_UNIX socket 。每一个套接字配置单元都有一个相应的服务配置单元 。相应的服务在第一个"连接"进入套接字时就会启动(例如:nscd.socket 在有新连接后便启动 nscd.service) |
| Swap unit | .swap,swap设备或swap文件,和挂载配置单元类似,交换配置单元用来管理交换分区。用户可以用交换配置单元来定义系统中的交换分区,可以让这些交换分区在启动时被激活 |
| Timer unit | .timer,systemd定时器,定时器配置单元用来定时触发用户定义的操作,这类配置单元取代了 atd、crond 等传统的定时服务 |
Target Unit与运行级别
systemd 用Target替代了运行级别的概念,提供了更大的灵活性,如您可以继承一个已有的目标,并添加其它服务,来创建自己的目标。下表列举了systemd下的目标和常见 RunLevel 的对应关系
| Sysvinit RunLevel | Systemd Target | 说明 |
|---|---|---|
| 0 | runlevel0.target, poweroff.target | 关闭系统 |
| 1, s, single | runlevel1.target, rescue.target | 单用户模式 |
| 2, 4 | runlevel2.target, runlevel4.target, multi-user.target | 用户定义/域特定运行级别,默认等同于 3 |
| 3 | runlevel3.target, multi-user.target | 多用户,非图形化。用户可以通过多个控制台或网络登录 |
| 5 | runlevel5.target, graphical.target | 多用户,图形化。通常为所有运行级别 3 的服务外加图形化登录 |
| 6 | runlevel6.target, reboot.target | 重启 |
| emergency | emergency.target | 紧急 Shell |
CentOS 7启动次序
- UEFI或BIOS初始化,运行POST
- 选择启动设备
- 引导装载程序,Centos 7为grub2
- 加载装载程序的配置文件:
/etc/grub.d/*,/etc/default/grub,/boot/grub2/grub.cfg - 加载initramfs驱动模块
- 加载内核选项
- 内核初始化,CentOS 7使用systemd代替init
- 执行initrd.target所有单元,包括挂载
/etc/fstab - 从initramfs根文件系统切换到磁盘根目录
- systemd执行默认target配置,配置文件
/etc/systemd/system/default.target - systemd执行sysinit.target初始化系统及basic.target准备操作系统
- systemd启动multi-user.target下的本机服务器服务
- systemd执行multi-user.target下的
/etc/rc.d/rc.local - systemd执行multi-user.target下的getty.target及登录服务
- systemd执行graphical需要的服务
七、相关命令
此处将介绍上文内容涉及到的一些常用命令或工具,systemd机制下的其他管理,如服务管理等,后续将介绍
init
上文已有介绍,init是系统的守护进程,同时可也是用户空间的管理工具,在SysV,Upstart,SystemD中都可使用
用户可使用给命令后跟一个数字的形式来切换运行级别,即
init RUN_LEVEL
RUN_LEVEL:0-6
如,要切换至单用户模式,使用init 1即可
runlevel
从命令的名称可以看出,该命令可用于查看运行级别,如
[root@localhost ~]# runlevel
N 3
[root@localhost ~]# init 5
[root@localhost ~]# runlevel
3 5
该命令的输出结果为上次运行级别 当前运行级别,若系统没有切换运行级别,则上次运行级别为N
uname
该命令用于查看系统信息,常用选项为
uname [OPTION]
OPTION
-r:内核release号
-n:主机名
-a:所有信息
[root@localhost ~]# uname
Linux
[root@localhost ~]# uname -r
2.6.32-504.el6.x86_64
[root@localhost ~]# uname -n
localhost.localdomain
[root@localhost ~]# uname -a
Linux localhost.localdomain 2.6.32-504.el6.x86_64 #1 SMP Wed Oct 15 04:27:16 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
systemctl
systemctl为System Control之意,是systemd系统中的非常强大的系统管理工具,同时也是一个服务管理器,其使用格式为
systemctl [OPTIONS...] COMMAND [NAME...]
此处介绍系统启动相关管理,服务管理后续将做介绍
-
- 切换运行级别
-
systemctl isolate NAME.target -
init命令依然可用
-
- 查看运行级别
-
systemctl list-units -t target -
该命令可展示当前活动的target,如
-
[root@localhost ~]# systemctl list-units -t target UNIT LOAD ACTIVE SUB DESCRIPTION basic.target loaded active active Basic System bluetooth.target loaded active active Bluetooth cryptsetup.target loaded active active Local Encrypted Volumes getty.target loaded active active Login Prompts local-fs-pre.target loaded active active Local File Systems (Pre) local-fs.target loaded active active Local File Systems multi-user.target loaded active active Multi-User System network-online.target loaded active active Network is Online network.target loaded active active Network paths.target loaded active active Paths remote-fs-pre.target loaded active active Remote File Systems (Pre) remote-fs.target loaded active active Remote File Systems slices.target loaded active active Slices sockets.target loaded active active Sockets sound.target loaded active active Sound Card swap.target loaded active active Swap sysinit.target loaded active active System Initialization timers.target loaded active active Timers LOAD = Reflects whether the unit definition was properly loaded. ACTIVE = The high-level unit activation state, i.e. generalization of SUB. SUB = The low-level unit activation state, values depend on unit type. 18 loaded units listed. Pass --all to see loaded but inactive units, too. To show all installed unit files use 'systemctl list-unit-files'. -
可以看到当前为multi-user.target
-
此外,
runlevel、who -r也可用于查看运行级别
-
- 设定默认运行级别
-
systemctl set-default NAME.target -
对于CentOS 6,修改
/etc/inittab中initdefault行信息即可
-
- 切换至紧急救援模式
-
systemctl rescue
-
- 切换emergency模式
-
systemctl emergency
-
- 其他命令
-
- 关机:
systemctl halt,systemctl poweroff
- 关机:
-
- 重启:
systemctl reboot
- 重启:
-
- 挂起:
systemctl suspend
- 挂起:
-
- 创建快照:
systemctl hibernate
- 创建快照:
-
- 快照后挂起:
systemctl hybrid-sleep
- 快照后挂起:
例
分别用while、for循环检测10.0.0.1/24网段存活的IP地址,网络相关内容详见Linux网络与进程管理9
-
for实现
#!/bin/bash ipaddr="10.0.0." declare -i uphosts=0 declare -i downhosts=0 trap 'echo "quit"; exit 5' INT startping() { ping -W 1 -c 1 ${ipaddr}${1} &> /dev/null && echo "${ipaddr}${1} online" && let uphosts+=1 || echo "${ipaddr}${1} offline" && downhosts+=1 } for((i=1;i<225;i++)); do startping $i done echo "Up: $uphosts" echo "Down: $downhosts" -
while实现
#!/bin/bash ipaddr="10.0.0." declare -i uphosts=0 declare -i downhosts=0 declare -i i=1 trap 'echo "quit"; exit 5' INT startping() { ping -W 1 -c 1 ${ipaddr}${1} &> /dev/null && echo "${ipaddr}${1} online" && let uphosts+=1 || echo "${ipaddr}${1} offline" && downhosts+=1 } while [ $i -lt 255 ]; do startping $i let i++ done echo "Up: $uphosts" echo "Down: $downhosts"
引用自 https://zh.wikipedia.org/wiki/%E5%8A%A0%E7%94%B5%E8%87%AA%E6%A3%80 ↩︎
相关规范:http://down.51cto.com/data/2459500 ↩︎
内容来自 https://zh.wikipedia.org/wiki/%E7%B5%B1%E4%B8%80%E5%8F%AF%E5%BB%B6%E4%BC%B8%E9%9F%8C%E9%AB%94%E4%BB%8B%E9%9D%A2 ↩︎
参考资料:https://en.wikipedia.org/wiki/D-Bus ↩︎
服务相关内容后续将做介绍 ↩︎
该小节内容参考自 https://www.ibm.com/developerworks/cn/linux/1407_liuming_init1/index.html ↩︎
该小节内容参考自 https://www.ibm.com/developerworks/cn/linux/1407_liuming_init2/index.html ↩︎
该小节内容参考自 https://www.ibm.com/developerworks/cn/linux/1407_liuming_init3/index.html ↩︎
那篇文章字数有点长,写不了了? ↩︎