FFmpeg中基于深度学习模型的图像处理filter:dnn_processing介绍(1)
在FFmpeg中,一开始增加了两个基于深度学习的video filter,分别是用来超分辨率的vf,和用来去除雨点的derain。它们都是对每帧中的内容进行的调整,包括对帧size的改变,用到的算法都是基于深度学习的模型。实际上,相比于这样为每一种功能算法增加一个filter的思路,我们还可以采用另外一种思路,即,设计一个通用的filter,可以用一个filter来普适所有基于深度学习模型的图像处理算法,此即我最近为FFmpeg增加dnn_processing的设想。本想做个全面的介绍,不过感觉缺少大块时间,就拆分介绍,也可以顺便增加篇数活跃一下。
本篇主要介绍如何使用dnn_processing来完成针对灰度图的sobel算子的调用,sobel算子主要用作边缘检测,通过对像素周围区域中的灰度值做加权相加,达到检测边缘的效果。我们首先要重新编译FFmpeg源代码,以增加对TensorFlow的支持,然后再要写出和Sobel算子等效的TensorFlow网络模型,最后dnn_processing会加载并执行此网络模型,对输入的frame逐一进行处理。为简化代码,我们只关注sobel算子水平方向的特性。
- 重新编译FFmpeg
FFmpeg对深度学习模型的支持有两个后端,一是调用TensorFlow C动态库来完成,二是调用内部C代码来实现。前者被称为tensorflow后端(将简写为tf后端),后者被称为native后端。要启用tf后端,必须在编译FFmpeg的机器上有tensorflow c开发库(包括.h文件和.so文件),而且在configure的时候需要传入相应的参数。而任何情况下的编译,native后端总是被自动启用。这两个后端本文都会涉及,所以,我们必须重新编译FFmpeg。
首先,我们下载libtensorflow c开发库,其官方下载链接是https://www.tensorflow.org/install/lang_c ,目前最新版本是1.15.0,顺便提一句,主页上还提到目前还不支持tensorflow 2(There is no libtensorflow support for TensorFlow 2 yet.)。但是,从1.14到1.15版本切换的时候,头文件发生了变化,而FFmpeg最早是在2018年引入对Tensorflow的支持,所以,我们目前还无法使用1.15版本,必须使用之前的版本,比如1.14版本(derain必须用到1.14版本)。可以搜索下载libtensorflow-cpu-linux-x86_64-1.14.0.tar.gz,这个压缩包中有以下的文件:
将这些文件目录拷贝到/usr/local/下面,成为系统库的一部分,比如/usr/local/lib/libtensorflow.so,然后,就可以开始从源代码开始编译FFmpeg了。具体步骤如下。
# 首先下载ffmpeg源代码
$ git clone https://git.ffmpeg.org/ffmpeg.git
$ cd ffmpeg/
# 新建编译目录,以和源代码目录分离
$ mkdir build
$ cd build/
# 如果本机没有找到libtensorflow,下面的configure会出错。
# 成功的话,在输出信息中会看到如下的libtensorflow字样。
$ ../configure --enable-libtensorflow
...
External libraries:
alsa libxcb libxcb_xfixes xlib
iconv libxcb_shape sdl2 zlib
libtensorflow libxcb_shm sndio
...
# 然后make编译就可以了。
# 如无必要,不需要make install。
$ make
# 看一下编译结果,其中,诸如ffmpeg_g等
# 后面带_g的文件包括symbol信息,方便被gdb加载调试。
$ ls
config.asm doc ffmpeg ffplay ffprobe fftools libavdevice libavformat libswresample Makefile tests
config.h ffbuild ffmpeg_g ffplay_g ffprobe_g libavcodec libavfilter libavutil libswscale src
- 准备sobel算子的网络模型
sobel算子在水平方向的3x3区域的模板如下图所示,也就是说,如果图片在水平方向上存在像素值的突变,会被认为是一个边缘。
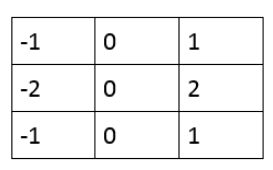
上述模板从深度学习的角度来看,其实就是一个卷积层,所以,我们可以用python脚本来生成Tensorflow网络模型,包括卷积层和必要的后处理,然后将网络模型保存为文件sobel.pb。我用的是python 3.5.2 和 tensorflow 1.13.1,如下所示。

具体的python脚本如下所示:
import tensorflow as tf
import numpy as np
from skimage import color
from skimage import io
# 读入原始彩色图片,因为我们一般拿到的都是彩色图
in_img = io.imread('input.jpg')
# 将彩色图转换为灰度图,并且保存到文件
gray_img = color.rgb2gray(in_img)
io.imsave('ori_gray.jpg', gray_img)
# 调整in_data的shape,以匹配模型输入
in_data = np.expand_dims(gray_img, axis=0)
in_data = np.expand_dims(in_data, axis=3)
# 设置Sobel算子的水平模板,这里无需训练,直接设置即可。
# 卷积核的格式是[filter_height, filter_width, in_channels, out_channels]
filter_data = np.array([-1.,0,1.,-2.,0,2.,-1.,0,1.]).reshape(3,3,1,1).astype(np.float32)
filter = tf.Variable(filter_data)
# 构建网络模型,用到了conv2d、maximum和minumum这三层。
# sobel_in是模型的输入变量名,将被dnn_processing引用。
x = tf.placeholder(tf.float32, shape=[1, None, None, 1], name='sobel_in')
conv = tf.nn.conv2d(x, filter, strides=[1, 1, 1, 1], padding='VALID')
# 下面两个函数将数据clip到有效数值范围[0.0, 1.0]。
y = tf.math.minimum(conv, 1.0)
# sobel_out是模型的输出变量名,将被dnn_processing引用。
y = tf.math.maximum(y, 0.0, name='sobel_out')
# 模型的执行准备
sess=tf.Session()
sess.run(tf.global_variables_initializer())
# 将模型文件保存为sobel.pb,这个文件包括了一切信息,将被ffmpeg所使用
graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, ['sobel_out'])
tf.train.write_graph(graph_def, '.', 'sobel.pb', as_text=False)
# 执行模型,并将结果保存为图片文件
output = sess.run(y, feed_dict={x: in_data})
output = np.squeeze(output)
io.imsave("out.jpg", output)
随意的用手机拍了一张照片如下,作为python脚本的输入。

执行脚本过程中生成的灰度图如下所示:

脚本执行完毕后得到的输出图片如下所示,可以看出,从水平方向分析的边缘基本都被检测出来了。我们将在ffmpeg中使用dnn_processing来达到这样的效果。

作为脚本最重要的输出,我们可以看到网络模型文件sobel.pb已经生成。实际上,sobel.pb就是我们编写脚本的关键目的,脚本的其他部分都是为了确保脚本的正确性。
$ ls sobel.pb -sh
4.0K sobel.pb
由于sobel.pb只能被用于tf后端,为了支持native后端,我们还需要从sobel.pb文件生成sobel.model文件,这是native后端支持的模型文件。在FFmpeg内部已经有了自动转换的方法,如下所示:
$ cd /your_path_to_ffmpeg_source_tree/ffmpeg
$ cd tools/python
$ python convert.py /your_path/sobel.pb
$ ls sobel.model -sh
4.0K sobel.model
- 执行dnn_processing
万事俱备,只欠执行。FFmpeg支持视频作为输入,也支持单张图片作为输入。为了和之前的python脚本有对比,我们继续用input.jpg作为输入,以out.jpg作为输出。具体执行命令如下所示:
# 回到一开始的编译目录
$ cd /your_path_to_ffmpeg_source_tree/ffmpeg/build
# 为避免命令行参数过长,可以将input.jpg文件和
# 两个模型文件sobel.pb和sobel.model拷贝到当前目录下。
# 调用tf后端执行,会显式用到两个filter。
# 首先,调用format,将格式转换为grayf32,因为这是网络模型需要的格式。
# 然后则是dnn_processing,其参数比较简单,
# 通过model参数指出模型文件,
# 而input和output则是网络模型的输入和输出变量名,在内部通过变量名实现和AVFrame的数据交互,
# dnn_backend参数则是指出后端使用tf。
# 最后,输出结果在out.jpg中。
$ ./ffmpeg -i input.jpg -vf \
format=grayf32, \
dnn_processing=model=sobel.pb:input=sobel_in:output=sobel_out:dnn_backend=tensorflow \
out.jpg
# 如果调用native后端执行的话,只需要修改model和dnn_backend这两个参数即可。
# 由于native后端还不成熟,这里是还不支持tf.math.minimum,所以这个命令并不会真正成功。
$ ./ffmpeg -i input.jpg -vf \
format=grayf32,\
dnn_processing=model=sobel.model:input=sobel_in:output=sobel_out:dnn_backend=native \
out.jpg
如果模型的输入输出接受uint8类型,即0到255的像素值的话,那么上述命令中的format的参数应是gray8,即format=gray8。
dnn_processing还支持RGB和YUV的输入格式,将在后续介绍。
以上内容是本人业余时间兴趣之作,限于水平,差错难免,仅代表个人观点,和本人任职公司无关。
本文首发于微信公众号:那遁去的一