Tensorflow-FaceNet训练、模型导出、评估、测试、数据制作
近期研究的课题是孪生网络,看到了FaceNet采用了孪生网络,研究的同时顺带把人脸识别FaceNet实现下,做了个简单的人脸识别项目:包含人员登记、人员签到以及FaceNet模型训练、评估、测试、模型导出、数据制作。
项目通过MTCNN人脸检测模型,从照片中提取人脸图像; 把人脸图像输入到FaceNet,计算Embedding的特征向量; 采用annoy进行人脸匹配,比较特征向量间的欧式距离; 项目利用谷歌浏览器调用电脑摄像头进行人脸采集与识别业务。
每次识别时间约240ms(MAC only cpu)
项目地址:https://github.com/MrZhousf/tf_facenet
依赖
- tensorflow1.8
- python2.7
- flask
- flask_sqlalchemy
- annoy
FaceNet源码
https://github.com/davidsandberg/facenet
官方预训练模型VGGFace2下载
https://download.csdn.net/download/zsf442553199/10952495
LFW评估测试数据下载
http://vis-www.cs.umass.edu/lfw/lfw.tgz
亚洲人脸数据库_CASIA-FaceV5
原上传者地址:https://download.csdn.net/download/weixin_42179317/10405384
若无csdn积分可以直接用百度云盘下载:
https://pan.baidu.com/s/1WS4nooNQgmQHR6EpmrW6dw 密码: sc8b
项目运行步骤
- 修改项目配置文件config_development.yml
- 运行app.py
- 人脸采集页面:http://127.0.0.1:8090/user/sign_in
- 人脸识别页面:http://127.0.0.1:8090/user/sign_up
相关截图
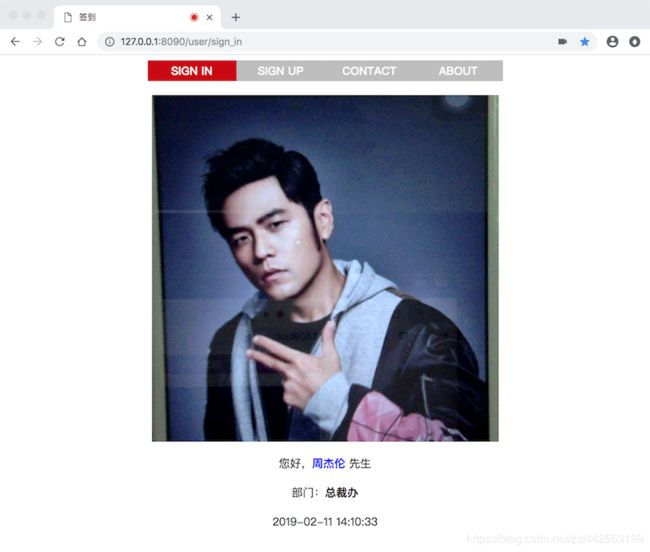
以周杰伦为例,此处仅用于学习与研究,莫怪。
- 人脸采集页面(谷歌浏览器打开)
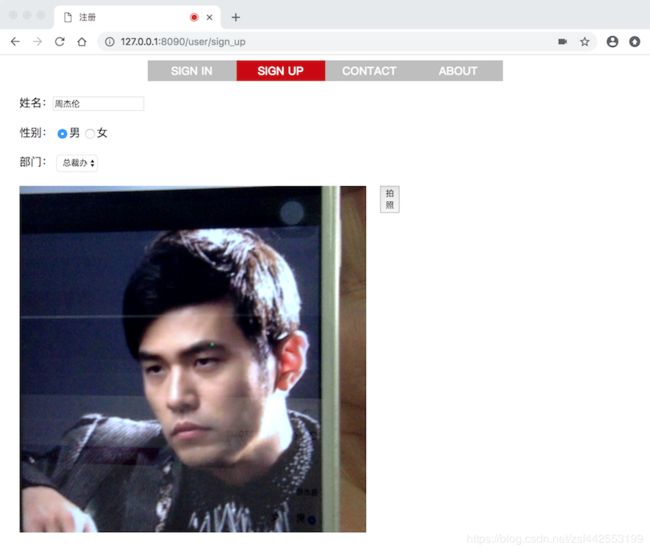
- 人脸识别页面(谷歌浏览器打开)
FaceNet
train目录下为FaceNet训练业务,训练采用train_tripletloss.py
- 训练:train.py
- 评估:eval.py
- 导出模型:export.py
- 比较:compare.py
- 可视化:show_train.py
- MTCNN人脸检测与对齐:align_data.py
- 制作评估数据(类似lfw的pairs.txt):create_eval_data.py
可以下载亚洲人脸数据库_CASIA-FaceV5,共500个中国人,每个人5张照片,总共2500张。用create_eval_data.py制作亚洲人脸评估数据集,这样就可以在训练亚洲人脸业务时进行有效的评估了。
训练配置文件:train_facenet.py
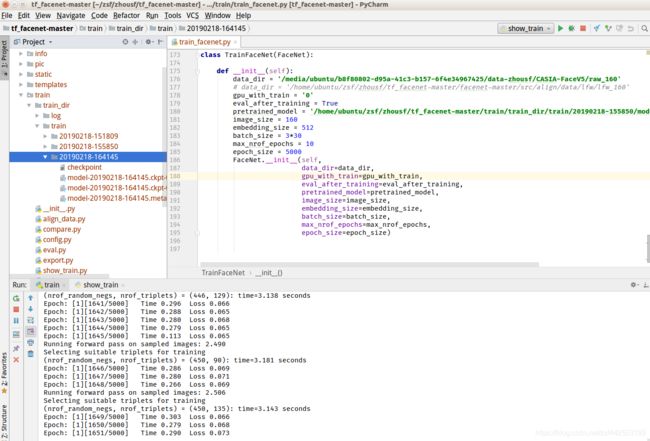
我针对亚洲人脸数据库_CASIA-FaceV5数据集进行了基于官方预训练VGGFace2模型进行预训练,训练机器配置为:
系统:ubuntu 16.04LTS
内存:16GB
CPU:Intel Core I7-6800K x12
GPU:GeForce GTX 1080Ti
训练参数train_tripletloss.py:
image_size=160, embedding_size=512, batch_size=90, max_nrof_epochs=10, epoch_size=500.
训练时间约45小时
训练得到模型 20190218-164145.pb
模型下载地址:https://download.csdn.net/download/zsf442553199/10965981
同样采用LFW数据集进行评估,准确率为68.467%:

而官方预训练VGGFace2模型评估准确率为98.5%:
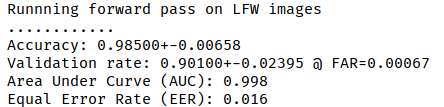
比较下发现针对亚洲人训练后准确率不升反降,不用担心,因为我们用了LFW来评估亚洲人,准确率肯定会下降的,毕竟亚洲人和欧美人长相还是有区别的。
为了验证我们训练的成果是有效的,我们做下以下测试:分别用以上两个模型对同一个亚洲人进行测试看得到的欧式空间距离,如果我们训练的模型的欧式空间距离比官方的模型要小,说明我们的训练是有效的。
运行train目录下的compare.py:
找了两张本人不同时期的照片进行测试
测试我们训练的模型,距离为0.6545:

测试官方预训练模型,距离为0.737:

很明显,我们训练的成果还是不错的。接下来,我们可以搜集大量的亚洲人脸数据进行训练,让我们的模型准确率提升到99%应该不是很难的事情。要注意的是训练和评估的数据都要用亚洲人脸数据。