【Druid】(六)Apache Druid 数据摄入
文章目录
- 一、数据格式
- 二、配置
- 2.1 DataSchema
- 2.1.1 parser
- 2.1.2 metricsSpec
- 2.1.3 GranularitySpec
- 2.2 ioConfig
- 2.3 tuningConfig
- 三、从 Hadoop 加载数据
- 3.1 加载数据
- 3.2 查询数据
- 四、从 kafka 加载数据
- 4.1 准备kafka
- 4.2 启动索引服务
- 4.3 加载历史数据
- 4.4 加载实时数据
- 4.5 加载自定义kafka 主题数据
一、数据格式
- 摄入规范化数据:JSON、CSV、TSV
- 自定义格式
- 其他格式
二、配置
主要是摄入的规则 Ingestion Spec
Ingestion Spec(数据格式描述)是Druid对要索引数据的格式以及如何索引该数据格式的一个统一描述,它是一个JSON文件,一般由三部分组成。
| Field | Type | Description | Required |
|---|---|---|---|
| dataSchema | JSON Object | 标识摄入数据的schema,dataSchema 是固定的,不随数据消费方式改变。不同specs 可共享 。 | yes |
| ioConfig | JSON Object | 标识data 从哪来,到哪去。数据消费方式不同,ioConfig也不相同。 | yes |
| tuningConfig | JSON Object | 标识如何调优不同的ingestion parameters 。根据不同的 ingestion method 不同。 | no |
{
"dataSchema" : {...},
"ioConfig" : {...},
"tuningConfig" : {...}
}
2.1 DataSchema
第一部分的dataSchema描述了数据的格式,如何解析该数据,典型结构如下。
{
"dataSource": <name_of_dataSource>,
"parser": {
"type": <>,
"parseSpec": {
"format": <>,
"timestampSpec": {},
"dimensionsSpec": {}
}
},
"metricsSpec": {},
"granularitySpec": {}
}
| Field | Type | Description | Required |
|---|---|---|---|
| dataSource | String | 要摄入的datasource 名称,Datasources 可看做为表 | yes |
| parser | JSON Object | ingested data 如何解析 | yes |
| metricsSpec | JSON Object array | aggregators(聚合器) 器列表 | yes |
| granularitySpec | JSON Object | 数据聚合设置,指定segment 的存储粒度和查询粒度 | yes |
2.1.1 parser
parser部分决定了数据如何被正确地解析,metricsSpec定义了数据如何被聚集计算,granularitySpec定义了数据分片的粒度、查询的粒度。
对于parser,type有两个选项:string和hadoopString,后者用于Hadoop索引的 job。parseSpec是数据格式解析的具体定义。
(1)string parser
| Field | Type | Description | Required |
|---|---|---|---|
| type | String | 一般为string,或在Hadoop indexing job 中使用hadoopyString | no |
| parseSpec | JSON Object | 标识格式format 和、imestamp、dimensions | yes |
parseSpec 两个功能:
- String Parser 用parseSpec 判定将要处理rows 的数据格式( JSON, CSV, TSV)
- 所有的Parsers 用parseSpec 判定将要处理rows 的timestamp 和dimensionsAll
JSON ParseSpec
| Field | Type | Description | Required |
|---|---|---|---|
| format | String | json | no |
| timestampSpec | JSON Object | 指明时间戳列名和格式 | yes |
| dimensionsSpec | JSON Object | 指明维度的设置 | yes |
| flattenSpec | JSON Object | 若json 有嵌套层级,则需要指定 | no |
CSV ParseSpec
| Field | Type | Description | Required |
|---|---|---|---|
| format | String | csv. | yes |
| timestampSpec | JSON Object | 指明时间戳列名和格式 | yes |
| dimensionsSpec | JSON Object | 指明维度的设置 | yes |
| listDelimiter | String | 多值dimensions 的分割符 | no(default = ctrl+A) |
| columns | JSON array | csv 的数据列名 | yes |
TSV ParseSpec
| Field | Type | Description | Required |
|---|---|---|---|
| format | String | tsv. | yes |
| timestampSpec | JSON Object | 指明时间戳列名和格式 | yes |
| dimensionsSpec | JSON Object | 指明维度的设置 | yes |
| listDelimiter | String | 多值dimensions 的分割符 | no(default = ctrl+A) |
| columns | JSON array | tsv 的数据列名 | yes |
| delimiter | String | 数据之间的分隔符,默认是\t | no |
对于不同的数据格式,可能还有额外的parseSpec选项。
TimestampSpec
| Field | Type | Description | Required |
|---|---|---|---|
| column | String | timestamp 的列 | yes |
| format | String | iso, millis, posix, auto or Joda time,时间戳格式 | no (default = ‘auto’) |
DimensionsSpec
| Field | Type | Description | Required |
|---|---|---|---|
| dimensions | JSON数组 | 描述数据包含哪些维度。每个维度可以只是个字符串,或者可以额外指明维度的属性,例如 “dimensions”: [ “dimenssion1”, “dimenssion2”, “{“type”: “long”, “name”: “dimenssion3”} ],默认是string类型。 | yes |
| dimensionExclusions | JSON字符串数组 | 数据消费时要剔除的维度。 | no (default == []) |
| spatialDimensions | JSON对象数组 | 空间维度名列表,主要用于地理几何运算 | no (default == []) |
2.1.2 metricsSpec
metricsSpec是一个JSON对象数组,定义了一些聚合器(aggregators)。聚合器通常有如下的结构。
{
"type": <type>,
"name": <output_name>,
"fieldName": <metric_name>
}
| Field | Type | Description | Required |
|---|---|---|---|
| dimensions | String | count,longSum 等聚合函数类型 | yes |
| fieldName | String | 聚合函数运用的列名 | no |
| name | String | 聚合后指标的列名 | yes |
一些简单的聚合函数:
count 、longSum、longMin、longMax、doubleSum、doubleMin、doubleMax
2.1.3 GranularitySpec
聚合支持两种聚合方式:uniform和arbitrary,前者以一个固定的时间间隔聚合数据,后者尽量保证每个segments大小一致,时间间隔是不固定的。目前uniform是默认选项。
| Field | Type | Description | Required |
|---|---|---|---|
| type | String | uniform | yes |
| segmentGranularity | string | segment 的存储粒度,HOUR DAY 等 | yes |
| queryGranularity | string | 最小查询粒度MINUTE HOUR | yes |
| intervals | JSON Object array | 数据消费时间间隔 ,可选,对于流式数据 pull 方式而言可以忽略 | no |
"dataSchema" : {
"dataSource" : "wikipedia",
"parser" : {
"type" : "string",
"parseSpec" : {
"format" : "json",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
{ "name" : "commentLength", "type" : "long" },
{ "name" : "deltaBucket", "type" : "long" },
"flags",
"diffUrl",
{ "name": "added", "type": "long" },
{ "name": "deleted", "type": "long" },
{ "name": "delta", "type": "long" }
]
},
"timestampSpec": {
"column": "timestamp",
"format": "iso"
}
}
},
"metricsSpec" : [],
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2016-06-27/2016-06-28"],
"rollup" : false
}
}
2.2 ioConfig
ioConfig 指明了真正具体的数据源
| Field | Type | Description | Required |
|---|---|---|---|
| type | String | always be ‘realtime’. | yes |
| firehose | JSON Object | 指明数据源,例如本地文件 kafka | yes |
| plumber | JSON Object | Where the data is going. | yes |
不同的firehose 的格式不太一致,以kafka 为例:
{
firehose : {
consumerProps : {
auto.commit.enable : false
auto.offset.reset : largest
fetch.message.max.bytes : 1048586
group.id : druid-example
zookeeper.connect : localhost:2181
zookeeper.connect.timeout.ms : 15000
zookeeper.session.timeout.ms : 15000
zookeeper.sync.time.ms : 5000
},
feed : wikipedia
type : kafka-0.8
}
}
ioConfig 的案例:
"ioConfig" : {
"type" : "index",
"firehose" : {
"type" : "local",
"baseDir" : "quickstart/",
"filter" : "wikipedia-2016-06-27-sampled.json"
},
"appendToExisting" : false
}
2.3 tuningConfig
tuningConfig 这部分配置是优化数据输入的过程
| Field | Type | Description | Required |
|---|---|---|---|
| type | String | realtime | no |
| maxRowsInMemory | Integer | 在存盘之前内存中最大的存储行数,指的是聚合后的行数indexing 所需Maximum heap memory= maxRowsInMemory * (2 +maxPendingPersists). | no (default ==75000) |
| windowPeriod | ISO 8601 Period String | 默认10 分钟,最大可容忍时间窗口,超过窗口,数据丢弃 | no (default ==PT10m) |
| intermediatePersistPeriod | ISO 8601 Period String | 多长时间数据临时存盘一次 | no (default ==PT10m) |
| basePersistDirectory | String | 临时存盘目录 | no (default == javatmp dir) |
| versioningPolicy | Object | 如何为segment 设置版本号 | no (default == basedon segment start time) |
| rejectionPolicy | Object | 数据丢弃策略 | no (default ==‘serverTime’) |
| maxPendingPersists | Integer | 最大同时存盘请求数,达到上限,输入将会暂停 | no (default == 0) |
| shardSpec | Object | 分片设置 | no (default ==‘NoneShardSpec’) |
| buildV9Directly | Boolean | 是否直接构建V9 版本的索引 | no (default == true) |
| persistThreadPriority | int | 存盘线程优先级 | no (default == 0) |
| mergeThreadPriority | int | 存盘归并线程优先级 | no (default == 0) |
| reportParseExceptions | Boolean | 是否汇报数据解析错误 | no (default == false) |
"tuningConfig" : {
"type" : "index",
"targetPartitionSize" : 5000000,
"maxRowsInMemory" : 25000,
"forceExtendableShardSpecs" : true
}
三、从 Hadoop 加载数据
3.1 加载数据
批量摄取维基百科样本数据,文件位于quickstart/wikipedia-2016-06-27-sampled.json。使用
quickstart/wikipedia-index-hadoop.json 摄取任务文件。
bin/post-index-task --file quickstart/wikipedia-index-hadoop.json
此命令将启动Druid Hadoop 摄取任务。
摄取任务完成后,数据将由历史节点加载,并可在一两分钟内进行查询。
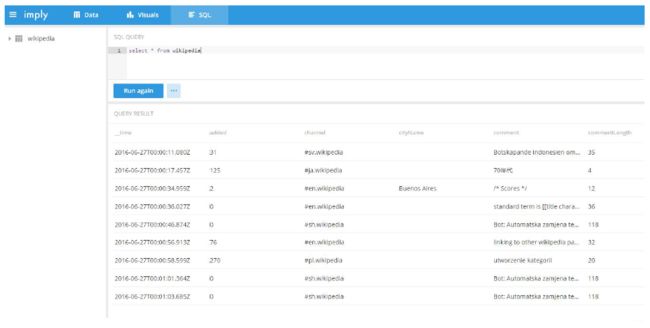
3.2 查询数据
四、从 kafka 加载数据
4.1 准备kafka
- 启动kafka
[chris@hadoop102 kafka]$ bin/kafka-server-start.sh config/server.properties
[chris@hadoop103 kafka]$ bin/kafka-server-start.sh config/server.properties
[chris@hadoop104 kafka]$ bin/kafka-server-start.sh config/server.properties
- 创建wikipedia 主题
[chris@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 –topic
wikipedia --partitions 1 --replication-factor 1 –create
Created topic "wikipedia".
- 查看主题是否创建成功
[chris@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
__consumer_offsets
first
wikipedia
4.2 启动索引服务
我们将使用Druid 的Kafka 索引服务从我们新创建的维基百科主题中提取消息。要启动该服务,我们需要通过从Imply 目录运行以下命令向Druid 的overlord 提交supervisor spec。
[chris@hadoop102 imply-2.7.10]$ curl -XPOST -H'Content-Type: application/json' -d
@quickstart/wikipedia-kafka-supervisor.json
http://hadoop102:8090/druid/indexer/v1/supervisor
说明:
curl 是一个利用 URL 规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具。
-X为HTTP 数据包指定一个方法,比如PUT、DELETE。默认的方法是GET 6.4.3-H为HTTP 数据包指定 Header 字段内容-d为POST 数据包指定要向HTTP 服务器发送的数据并发送出去,如果的内容以符号@ 开头,其后的字符串将被解析为文件名,curl 命令会从这个文件中读取数据发送。
4.3 加载历史数据
启动kafka 生产者生产数据
[chris@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 –
-topic wikipedia < /opt/module/imply-2.7.10/quickstart/wikipedia-2016-06-27-sampled.json
说明:
< 将文件作为命令输入
可在kafka 本地看到相应的数据生成
[chris@hadoop103 logs]$ pwd
/opt/module/kafka/logs
将样本事件发布到Kafka 的wikipedia 主题,然后由Kafka 索引服务将其提取到Druid 中。你现在准备运行一些查询了!
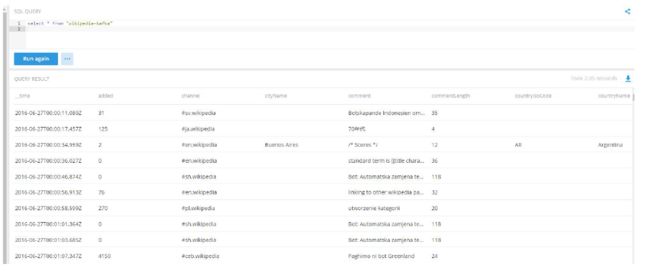
4.4 加载实时数据
下载一个帮助应用程序,该应用程序将解析维基媒体的IRC 提要中的event,并将这些event发布到我们之前设置的Kafka 的wikipedia 主题中。
[chris@hadoop102 imply-2.7.10]$ curl -O
https://static.imply.io/quickstart/wikiticker-0.4.tar.gz
说明:
-O 在本地保存获取的数据时,使用它们在远程服务器上的文件名进行保存。
[chris@hadoop102 imply-2.7.10]$ tar -zxvf wikiticker-0.4.tar.gz
[chris@hadoop102 imply-2.7.10]$ cd wikiticker-0.4
现在运行带有参数的wikiticker,指示它将输出写入我们的Kafka 主题:
[chris@hadoop102 wikiticker-0.4]$ bin/wikiticker -J-Dfile.encoding=UTF-8 -out kafka –
topic Wikipedia
查询多次,对比结果的变化
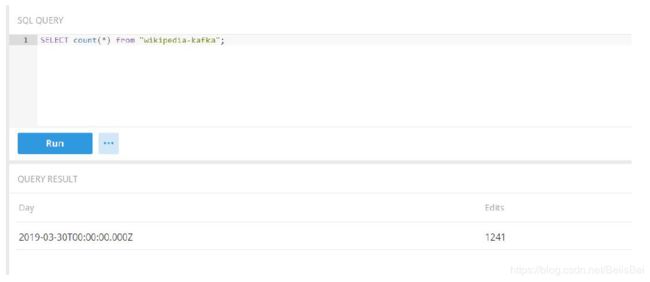
4.5 加载自定义kafka 主题数据
可以通过编写自定义supervisor spec 来加载自己的数据集。要自定义受监督的Kafka 索引服务提取,可以将包含的quickstart/wikipedia-kafka-supervisor.json 规范复制到自己的文件中,根据需要进行编辑,并根据需要创建或关闭管理程序。没有必要自己重启Imply 或Druid 服务。