关于官网介绍hadoop-3.2.1安装
1.首先准备ssh安装
机器的公钥: id_rsa.pub
机器的私钥:id_rsa
a、输入ssh-keygen,在本机/peiyajie/.ssh/目录下生成id_rsa(私钥)、id_ras.pub(公钥)两个文件
b、输入ssh-copy-id [user]@[host],远程主机上就会有/peiyajie/.ssh/authorized_keys文件,文件内容和第一个主机的公钥相同,(相当于下图的第一步)发送本机公钥给远程服务器,此操作可能需要时间。这一步是将公钥复制到机器中去
SSH密钥到目标主机,开启无密码SSH登录
ssh-copy-id user@host
完成即可
2.手动下载然后上传服务器 下载地址:https://hadoop.apache.org/releases.html
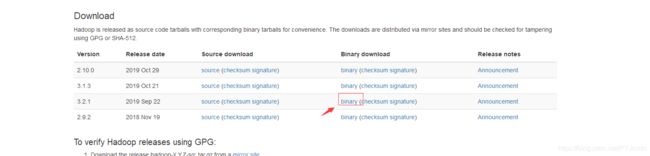
tar -zxvf hadoop-3.2.1.tar.gz
当然要完成jdk安装,之后才进行(自己进行百度)
2.1进入目录:cd /home/peiyajie/hadoop-3.2.1/etc/hadoop/
修改命令:vim hadoop-env.sh
修改jdk安装目录:export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
2.2创建一个hadoop运行时产生文件的存储路径文件夹
![]()
修改core-site.xml文件,里面增加
2.3修改文件:vim /home/peiyajie/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
增加
然后启动hadoop
第一次启动需要格式话文件
格式化: /home/peiyajie/hadoop-3.2.1/bin/hdfs namenode -format
启动:/home/peiyajie/hadoop-3.2.1/sbin/start-dfs.sh
停止: /home/peiyajie/hadoop-3.2.1/sbin/stop-dfs.sh
修改机器端口开放,这里面开放9870和8088端口
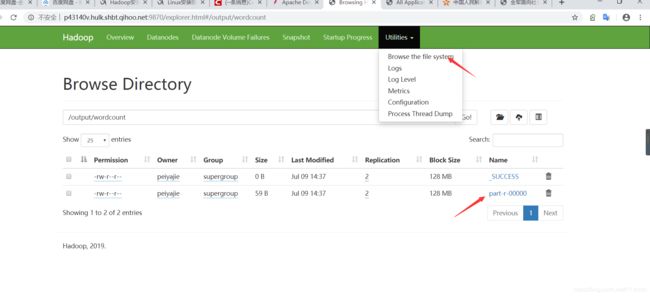
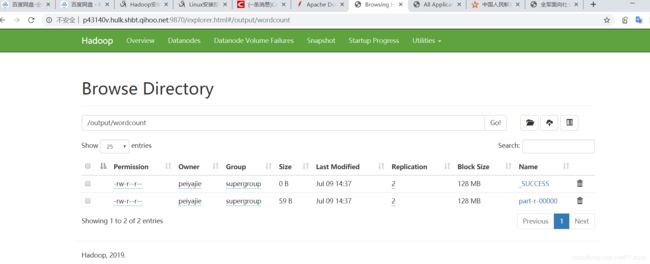
http://p43140v.hulk.shbt.qihoo.net:9870
3.开启yarn功能
3.1进入目录 cd /home/peiyajie/hadoop-3.2.1/etc/hadoop,修改文件 vim mapred-site.xml
注意在配置文件里面需要配置:
export HADOOP_HOME=/home/peiyajie/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin:$PATH
3.2进入目录 cd /home/peiyajie/hadoop-3.2.1/etc/hadoop
修改文件vim yarn-site.xml
添加以下配置:
yarn启动和关闭:
/home/peiyajie/hadoop-3.2.1/sbin/start-yarn.sh
/home/peiyajie/hadoop-3.2.1/sbin/stop-yarn.sh
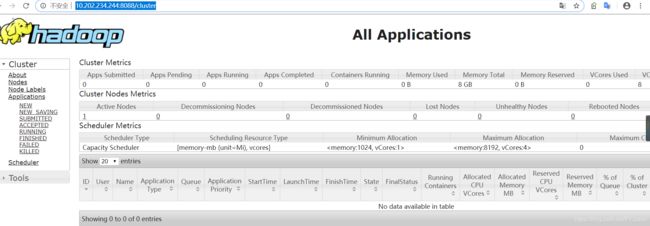
访问即可完成http://10.202.234.244:8088/cluster
4.执行自带的wordcount
4.1/home/peiyajie/hadoop-3.2.1
vi test.txt
创建如下文件夹:
home/peiyajie/hadoop-3.2.1/bin/hadoop fs -mkdir -p /data/wordcount
/home/peiyajie/hadoop-3.2.1/bin/hadoop fs -mkdir /output
将文件放入对应目录:
/home/peiyajie/hadoop-3.2.1/bin/hadoop fs -put test.txt /data/wordcount
查看列表:
/home/peiyajie/hadoop-3.2.1/bin/hadoop fs -ls /
/home/peiyajie/hadoop-3.2.1/bin/hadoop fs -ls /data/wordcount
产生统计结果:
/home/peiyajie/hadoop-3.2.1/bin/hadoop jar /home/peiyajie/hadoop-3.2.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /data/wordcount /output/wordcount
查看产生的结果:
/home/peiyajie/hadoop-3.2.1/bin/hadoop fs -cat /output/wordcount/part-r-00000