RDD算子介绍
一、RDD算子简介
提供一优秀RDD讲解链接:https://blog.csdn.net/fortuna_i/article/details/81170565
spark在运行过程中通过算子对RDD进行计算,算子是RDD中定义的函数,可以对RDD中数据进行转换和操作,如下图
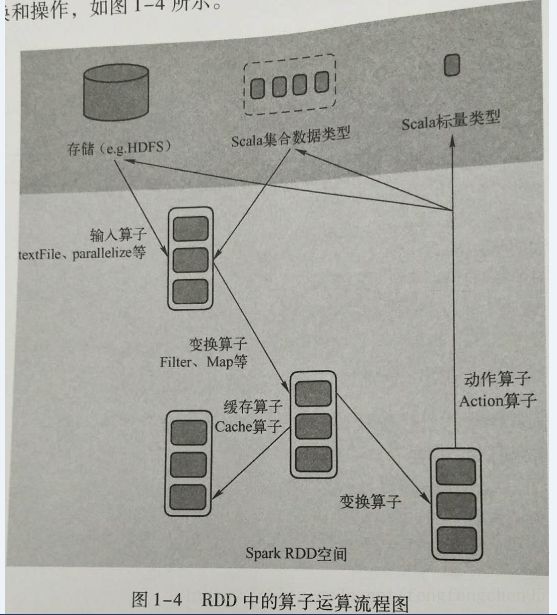
输入:spark程序中数据从外部数据空间输入到spark中的数据块,通过BlockManager进行管理
运行:在spark数据形成RDD后,可以通过变换算子,如filter等对数据进行操作,并将RDD转换为新的RDD,通过Action算子,触发Spark提交作业。如果数据复用,可以通过cache算子将数据缓存到内存中。
输出:程序运行结束后数据会输出Spark运行时的空间,存在到分布式存在结构(如:saveAsTextFile输出到HDFS)或者scala的数据集合中。
Spark将常用的大数据操作都转化成RDD的子类,Spark操作数据模型图如下;
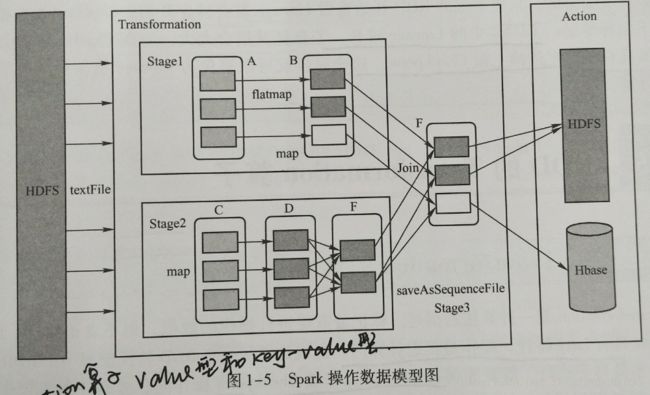
二、SparkRDD中的算子分类。
1.Value数据类型的Transformation算子,这种变化并不触发提供作业,针对处理的数据项是Value型的数据。
2.Key-Value类型的Transformation算子,这种变化并不触发提供作业,针对处理的数据项是Key-Value型的数据
3.Action算子,这类算子会触发SparkContext提交Job作业。
三、RDD Transformation
Transformations是一种算法描述,标记着需要进行数据操作的数据,但不真正执行,具有Lazy特性,操作延迟,需要等到Actions操作或者Checkpoint操作时,才能真正触发操作。
RDD转换,从之前的RDD构建一个新的RDD,像map()和filter()
1.逐元素的Transformation
map()接收函数,把函数应用到RDD的每一个元素,返回新的RDD
var lines2=line.map(word=>(word,1))
filter()接收函数,返回只包含满足filter()函数的元素的新RDD
var lines3=line.filter(word=word.contains("hello"))
flatMap()接收函数,对每一个输入元素,输出多个输出元素,将RDD中元素压扁后返回一般新的RDD
val inputs=sc.textFile("/data/shellScript/wordcount")
val lines=inputs.flatMap(line=line.split(","))
二、RDD集合运算
RDD支持数学集合的计算,例如并集、交集计算。
rdd1.distinct()去重
rdd1.union(rdd2) 并集
rdd1.intersecton(rdd2) 交集
rdd1.substact(rdd2) rdd1-rdd2
四、Action
在RDD上计算出一个结果,并把结果返回给driver program或者保存在文件系统,count(),save
RDD常用Action:
collect():返回RDD的所有元素
count():计数
countByValue():返回一个map表示唯一元素出现的个数
take(num):返回几个元素,随机无序
top(num):返回前几个元素,排序之后的top
takeOrdered(num)(ordering):返回基于提供的排序算法的前几个元素
reduce();接收一个函数,作用在RDD两个相同类型的元素上,返回新元素,可以实现,RDD中元素的累加,计数和其它类型的聚集操作,for example: rdd.reduce((x,y)=>x+y)
foreach():计算RDD的每一个元素,但不返回到本地