OCR----Tesseract 3.x架构及原理解析
#Tesseract的历史
Tesseract是一个开源的OCR引擎,惠普公司的布里斯托尔实验室在1984-1994年开发完成。起初作为惠普的平板扫描仪的文字识别引擎。Tesseract在1995年UNLV OCR字符识别准确性测试中拔得头筹,受到广泛关注。后来HP放弃了OCR市场。在1994年以后,Tesseract的开发就停止了。
在2005年,HP将Tesseract贡献给开源社区。美国内华达州信息技术研究所获得该源码,同时,Google开始对Tesseract进行功能扩展及优化。目前,Tesseract作为开源项目发布在Google Project上,重获新生。Tesseract的最新版本是3.02,它支持60种以上的语言,提供一个引擎和一个命令行工具,官方下载地址:谷震平的传送门。
Tesseract架构解析
Tesseract引擎功能强大,概括地可以分为两部分:
- 图片布局分析
- 字符分割和识别
图片布局分析,是字符识别的准备工作。工作内容:通过一种混合的基于制表位检测的页面布局分析方法,将图像的表格、文本、图片等内容进行区分。
字符分割和识别是整个Tesseract的设计目标,工作内容最为复杂。首先是字符切割,Tesseract采用两步走战略:
- 利用字符间的间隔进行粗略的切分,得到大部分的字符,同时也有粘连字符或者错误切分的字符。这里会进行第一次字符识别,通过字符区域类型判定,根据判定结果对比字符库识别字符。
- 根据识别出来的字符,进行粘连字符的分割,同时把错误分割的字符合并,完成字符的精细切分。
当然,还有另一种说法----细致地可以分为四个部分:
- 分析连通区域
- 找到块区域
- 找文本行和单词
- 得出(识别)文本

图 Tesseract主要四个部分(仅代表谷震平个人观点,请勿抄袭)
举个详细的例子:
PS:此例也是Ray Smith的文章(Adapting the Tesseract Open Source OCR Engine for Multilingual OCR)中给出的,具有代表性。
不想贴文字,直接上图:
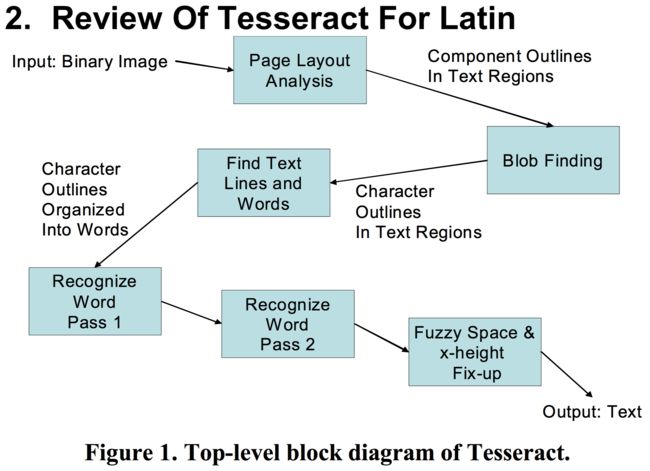
Tesseract的架构并不是我这三言两语能讲清楚地,欢迎留言补充纠正!谢谢合作!
Tesseract实现原理
原理这块相当复杂,这篇blog只谈TessBaseAPI相关的东西。后续系列再撰文补充。
TessBaseAPI是Tesseract引擎的一个核心类,关于这个类的源代码请戳这里:谷震平的传送门。我们来理解下这个类函数的运作机制,借此联想下Tesseract引擎的实现原理。机制如下:
- 调用Init()方法,即对引擎初始化
- 调用setImage()方法,设置图形流的信息
- 通过getUTF8Text()方法获得text信息
- 调用recognizedText类,判断text的正确性,然后输出。这里,会调用自有的trim()方法和length()方法做一些相应的处理。
关于Init()方法,官方的API介绍:
Instances are now mostly thread-safe and totally independent, but some global parameters >remain. Basically it is safe to use multiple TessBaseAPIs in different threads in parallel, UNLESS: you use SetVariable on some of the Params in classify and textord. If you do, then the effect will be to change it for all your instances.
Start tesseract. Returns zero on success and -1 on failure. NOTE that the only members that may be called before Init are those listed above here in the class definition.
The datapath must be the name of the parent directory of tessdata and must end in / . Any name after the last / will be stripped. The language is (usually) an ISO 639-3 string or NULL will default to eng. It is entirely safe (and eventually will be efficient too) to call Init multiple times on the same instance to change language, or just to reset the classifier. The language may be a string of the form []
[+[ ]]* indicating that multiple languages are to be loaded. Eg hin+eng will load Hindi and English. Languages may specify internally that they want to be loaded with one or more other languages, so the ~ sign is available to override that. Eg if hin were set to load eng by default, then hin+~eng would force loading only hin. The number of loaded languages is limited only by memory, with the caveat that loading additional languages will impact both speed and accuracy, as there is more work to do to decide on the applicable language, and there is more chance of hallucinating incorrect words. WARNING: On changing languages, all Tesseract parameters are reset back to their default values. (Which may vary between languages.) If you have a rare need to set a Variable that controls initialization for a second call to Init you should explicitly call End() and then use SetVariable before Init. This is only a very rare use case, since there are very few uses that require any parameters to be set before Init.
If set_only_non_debug_params is true, only params that do not contain “debug” in the name will be set.
The datapath must be the name of the data directory (no ending /) or some other file in which the data directory resides (for instance argv[0].) The language is (usually) an ISO 639-3 string or NULL will default to eng. If numeric_mode is true, then only digits and Roman numerals will be returned.
- Returns
- 0 on success and -1 on initialization failure.
其他函数的介绍,自己去读一些API吧,我就不贴了。API传送门

图 TessBaseAPI内置的一些方法
The End
我觉得自己肯定没有写清楚,欢迎留言来批评!
特别希望党老师来批评!
谢谢大家!
内容来自谷震平的blog,尊重原创,转载请注明出处!
谢谢~
欢迎加入星球:
